











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何选择完美的机器学习算法
2023年07月25日 由 Camellia 发表
263499
0
在解决数据科学问题时,选择适当的机器学习算法是最重要的决策之一。
有数百种机器学习算法可供选择,每种算法都有各自的优缺点。某些算法在特定类型的问题或具体数据集上的表现可能比其他算法更好。
“没有免费的午餐”(NFL)这一定理说明没有一种算法适用于所有问题,换句话说,当所有算法的性能在所有可能的问题上达到平均值时,所有算法都具有相同的性能。
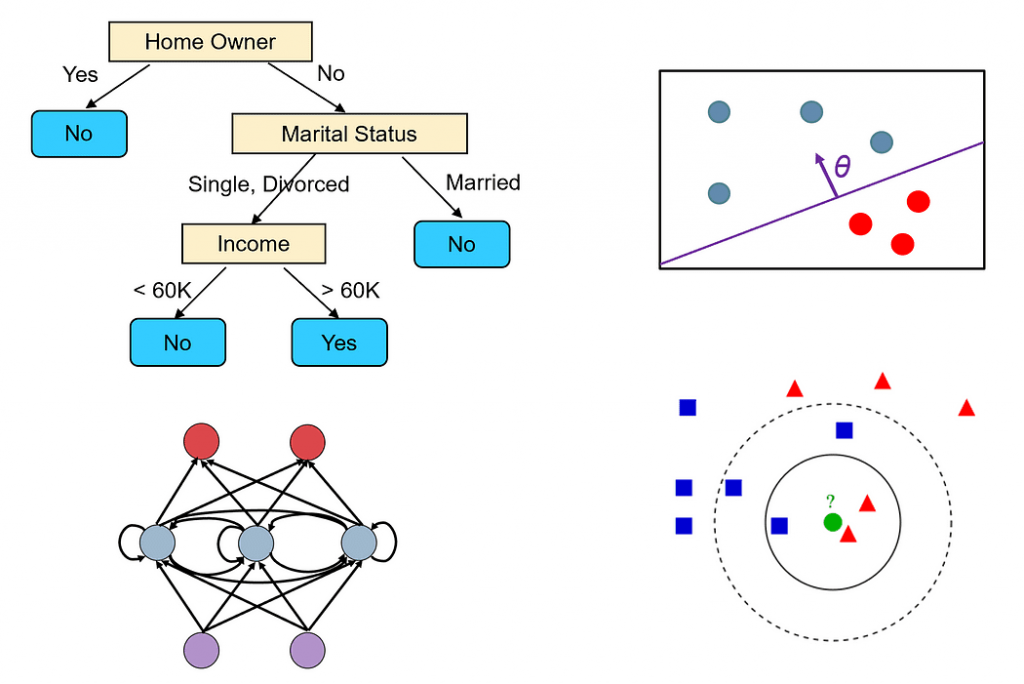
在本文中,我们将讨论选择模型时应考虑的主要因素以及如何比较不同的机器学习算法。
下面的列表包含了在考虑特定机器学习算法时可能你会问自己的10个问题:
1.该算法可以解决哪些类型的问题?算法只能解决回归或分类问题,还是两者都能解决?它能处理多类/多标签问题,还是只能处理二元分类问题?
2.该算法对数据集有什么假设?例如,一些算法假设数据是线性可分的(如感知机或线性SVM),而其他算法假设数据服从正态分布(如高斯混合模型)。
3.该算法的性能是否有任何保证?例如,如果该算法尝试解决优化问题(如逻辑回归或神经网络),它是保证找到全局最优解还是只能找到局部最优解?
4.训练模型所需的数据量如何?与其他算法相比,一些算法,例如深度神经网络,对数据更敏感。
5.该算法是否有过拟合的倾向?如果是,该算法是否提供处理过拟合的方式?
6.在训练和预测期间,该算法的运行时间和内存需求如何?
7.为了将数据准备好供算法使用,需要进行哪些数据预处理步骤?
8.该算法有多少超参数?具有很多超参数的算法需要更多的时间来训练和调整。
9.该算法的结果是否容易解释?在许多问题领域(如医疗诊断),我们希望能够用人类术语解释模型的预测结果。有些模型可以轻松可视化(如决策树),而其他模型则更像是一个黑盒(如神经网络)。
10.该算法是否支持在线(增量)学习,即我们能否在额外的样本上训练它,而无需从头开始重建模型?
例如,让我们以这两种最流行的算法为例:决策树和神经网络,根据上述标准进行比较。
1.决策树可以处理分类和回归问题。它们也可以轻松处理多类和多标签问题。
2.决策树算法对数据集没有任何特定的假设。
3.决策树使用贪心算法构建,无法保证找到最优树(即最小化所需的分类测试次数以正确分类所有训练样本的树)。但是,如果我们保持扩展树节点直到所有叶节点中的样本属于同一类的树,决策树可以在训练集上达到100%的准确性。这种树通常不是很好的预测器,因为它们在训练集中过拟合了噪声。
4.决策树在小型或中等大小的数据集上表现良好。
5.决策树很容易过拟合。然而,我们可以通过使用剪枝来减少过拟合。我们还可以使用集成方法,如随机森林,将多个决策树的输出合并起来。这些方法较少受到过拟合的影响。
6.构建决策树的时间复杂度为O(n²p),其中n是训练样本的数量,p是特征的数量。决策树的预测时间取决于树的高度,通常在n的对数级别,因为大多数决策树是相当平衡的。
7.决策树不需要进行任何数据预处理。它们可以无缝处理不同类型的特征,包括数值和分类特征。它们也不需要对数据进行规范化。
8.决策树有几个关键的超参数需要调整,特别是如果使用剪枝,例如,树的最大深度和用于决定如何分割节点的杂质度量。
9.决策树易于理解和解释,并且可以轻松可视化(除非树非常大)。
10.决策树无法轻松修改以考虑新的训练样本,因为数据集中的小变化可能导致树的拓扑结构发生大的变化。
1.神经网络是最通用、最灵活的机器学习模型之一。它们可以解决几乎任何类型的问题,包括分类、回归、时间序列分析、自动生成内容等。
2.神经网络对数据集没有任何假设,但数据需要进行规范化。
3.神经网络使用梯度下降进行训练。因此,它们只能找到局部最优解。然而,有各种技术可用于避免陷入局部极小值,例如动量和自适应学习率。
4.深度神经网络需要大量数据进行训练,数量级为数百万个样本点。通常,网络越大(层数和神经元数越多),我们需要更多数据来训练。
5.网络太大可能会记住所有的训练样本,并且不能很好地泛化。对于许多问题,你可以从一个小型网络开始(例如仅有一到两个隐藏层),逐渐增加其大小,直到开始过拟合训练集。你也可以添加正则化以处理过拟合。
6.神经网络的训练时间取决于许多因素(网络的大小、训练它所需的梯度下降迭代次数等)。然而,预测时间非常快,因为我们只需要对网络进行一次前向传播即可获得标签。
7.神经网络要求所有特征都是数值化和规范化的。
8.神经网络有许多需要调整的超参数,如层数、每层神经元数、使用哪种激活函数、学习率等。
9.神经网络的预测结果很难解释,因为它们基于大量神经元的计算,每个神经元对最终预测的贡献很小。
10.神经网络可以轻松适应包括额外的训练样本,因为它们使用增量学习算法(随机梯度下降)。
下表比较了一些流行算法的训练和预测时间(n是训练样本的数量,p是特征的数量)。
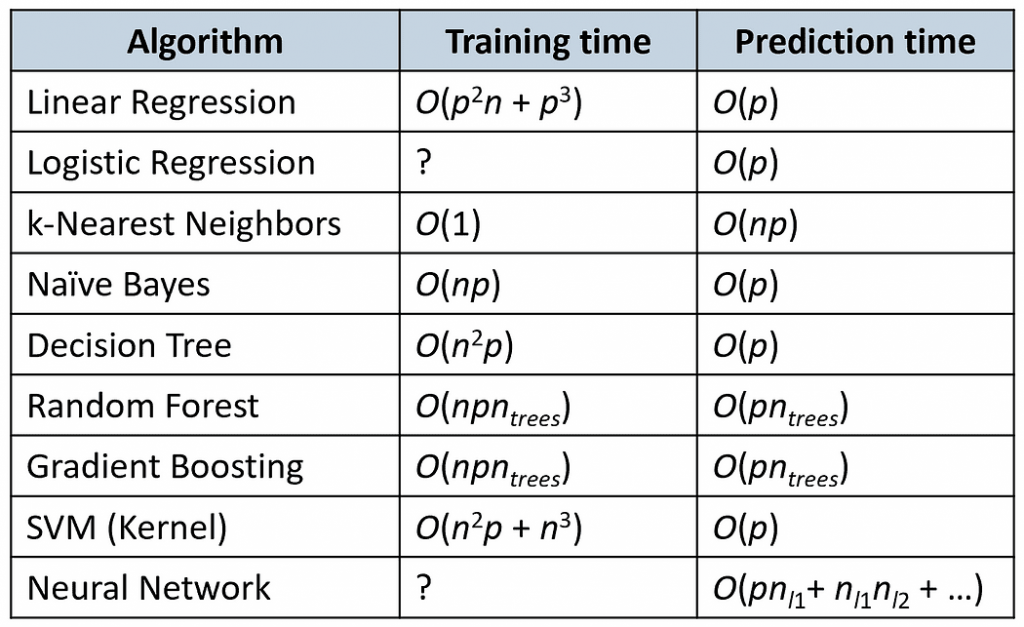
来源:https://www.kdnuggets.com/2023/07/ml-algorithm-choose.html
有数百种机器学习算法可供选择,每种算法都有各自的优缺点。某些算法在特定类型的问题或具体数据集上的表现可能比其他算法更好。
“没有免费的午餐”(NFL)这一定理说明没有一种算法适用于所有问题,换句话说,当所有算法的性能在所有可能的问题上达到平均值时,所有算法都具有相同的性能。
在本文中,我们将讨论选择模型时应考虑的主要因素以及如何比较不同的机器学习算法。
关键算法方面
下面的列表包含了在考虑特定机器学习算法时可能你会问自己的10个问题:
1.该算法可以解决哪些类型的问题?算法只能解决回归或分类问题,还是两者都能解决?它能处理多类/多标签问题,还是只能处理二元分类问题?
2.该算法对数据集有什么假设?例如,一些算法假设数据是线性可分的(如感知机或线性SVM),而其他算法假设数据服从正态分布(如高斯混合模型)。
3.该算法的性能是否有任何保证?例如,如果该算法尝试解决优化问题(如逻辑回归或神经网络),它是保证找到全局最优解还是只能找到局部最优解?
4.训练模型所需的数据量如何?与其他算法相比,一些算法,例如深度神经网络,对数据更敏感。
5.该算法是否有过拟合的倾向?如果是,该算法是否提供处理过拟合的方式?
6.在训练和预测期间,该算法的运行时间和内存需求如何?
7.为了将数据准备好供算法使用,需要进行哪些数据预处理步骤?
8.该算法有多少超参数?具有很多超参数的算法需要更多的时间来训练和调整。
9.该算法的结果是否容易解释?在许多问题领域(如医疗诊断),我们希望能够用人类术语解释模型的预测结果。有些模型可以轻松可视化(如决策树),而其他模型则更像是一个黑盒(如神经网络)。
10.该算法是否支持在线(增量)学习,即我们能否在额外的样本上训练它,而无需从头开始重建模型?
算法比较示例
例如,让我们以这两种最流行的算法为例:决策树和神经网络,根据上述标准进行比较。
决策树
1.决策树可以处理分类和回归问题。它们也可以轻松处理多类和多标签问题。
2.决策树算法对数据集没有任何特定的假设。
3.决策树使用贪心算法构建,无法保证找到最优树(即最小化所需的分类测试次数以正确分类所有训练样本的树)。但是,如果我们保持扩展树节点直到所有叶节点中的样本属于同一类的树,决策树可以在训练集上达到100%的准确性。这种树通常不是很好的预测器,因为它们在训练集中过拟合了噪声。
4.决策树在小型或中等大小的数据集上表现良好。
5.决策树很容易过拟合。然而,我们可以通过使用剪枝来减少过拟合。我们还可以使用集成方法,如随机森林,将多个决策树的输出合并起来。这些方法较少受到过拟合的影响。
6.构建决策树的时间复杂度为O(n²p),其中n是训练样本的数量,p是特征的数量。决策树的预测时间取决于树的高度,通常在n的对数级别,因为大多数决策树是相当平衡的。
7.决策树不需要进行任何数据预处理。它们可以无缝处理不同类型的特征,包括数值和分类特征。它们也不需要对数据进行规范化。
8.决策树有几个关键的超参数需要调整,特别是如果使用剪枝,例如,树的最大深度和用于决定如何分割节点的杂质度量。
9.决策树易于理解和解释,并且可以轻松可视化(除非树非常大)。
10.决策树无法轻松修改以考虑新的训练样本,因为数据集中的小变化可能导致树的拓扑结构发生大的变化。
神经网络
1.神经网络是最通用、最灵活的机器学习模型之一。它们可以解决几乎任何类型的问题,包括分类、回归、时间序列分析、自动生成内容等。
2.神经网络对数据集没有任何假设,但数据需要进行规范化。
3.神经网络使用梯度下降进行训练。因此,它们只能找到局部最优解。然而,有各种技术可用于避免陷入局部极小值,例如动量和自适应学习率。
4.深度神经网络需要大量数据进行训练,数量级为数百万个样本点。通常,网络越大(层数和神经元数越多),我们需要更多数据来训练。
5.网络太大可能会记住所有的训练样本,并且不能很好地泛化。对于许多问题,你可以从一个小型网络开始(例如仅有一到两个隐藏层),逐渐增加其大小,直到开始过拟合训练集。你也可以添加正则化以处理过拟合。
6.神经网络的训练时间取决于许多因素(网络的大小、训练它所需的梯度下降迭代次数等)。然而,预测时间非常快,因为我们只需要对网络进行一次前向传播即可获得标签。
7.神经网络要求所有特征都是数值化和规范化的。
8.神经网络有许多需要调整的超参数,如层数、每层神经元数、使用哪种激活函数、学习率等。
9.神经网络的预测结果很难解释,因为它们基于大量神经元的计算,每个神经元对最终预测的贡献很小。
10.神经网络可以轻松适应包括额外的训练样本,因为它们使用增量学习算法(随机梯度下降)。
时间复杂度
下表比较了一些流行算法的训练和预测时间(n是训练样本的数量,p是特征的数量)。
来源:https://www.kdnuggets.com/2023/07/ml-algorithm-choose.html

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消