











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Keras和PyTorch的视觉识别与迁移学习对比
2018年10月10日 由 yuxiangyu 发表
421794
0

在上一篇文章中,我们简述了Keras和PyTorch的区别,旨在帮助你选择更适合你需求的框架。现在,我们进行实战。我们将让Keras和PyTorch互相较量以展示他们的优劣。我们使用的问题是:区分异形和铁血战士。
图像分类,是计算机视觉任务之一。由于在大多数情况下从头开始训练很难实施(因为它很需要数据),我们使用在ImageNet上预训练的ResNet-50进行迁移学习。我们尽可能贴合实际地展示概念差异和惯例。同时,我们的代码保持简约,使其清晰、易于阅读和重用。
那么,什么是迁移学习?为什么使用ResNet-50?实际上,很少有人从头开始训练整个卷积网络(使用随机初始化),因为足够大小的数据集相对罕见的。因此,通常在非常大的数据集(例如ImageNet,其包含具有1000个类别的120万个图像)上预训练ConvNet,然后使用ConvNet作为自己任务的初始化或固定特征提取器(出自Andrej Karpathy,CS231n)。
迁移学习是对在给定任务上训练的网络进行微小调整以执行另一个类似任务的过程。在我们的案例中,我们使用经过训练的ResNet-50模型对ImageNet数据集中的图像进行分类。这足以学习很多可能在其他视觉任务中有用的纹理和模式,甚至可以辨别异形大战铁血战士中的异形。这样,我们使用更少的计算能力来取得更好的结果。
在我们的例子中,我们以最简单的方式做到:
- 保持预训练的卷积层(即,所谓的特征提取器),保持它们的权重不变。
- 删除原始稠密层,并用我们用于训练的新稠密层替换。
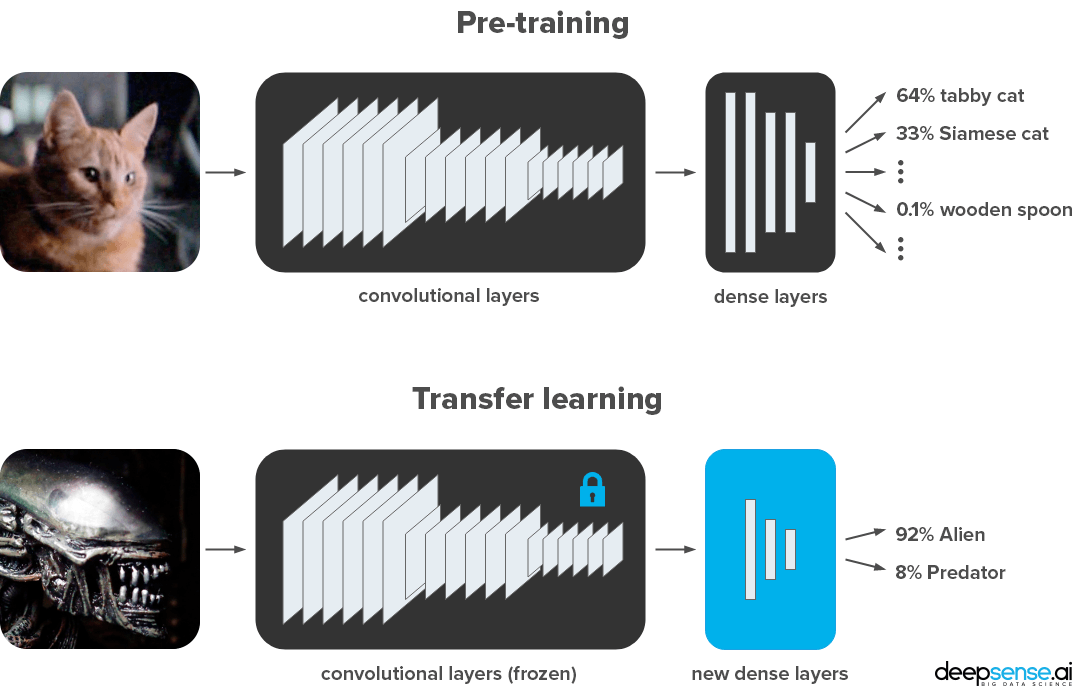
那么,应该选择哪个网络作为特征提取器?
ResNet-50是很流行的ImageNet图像分类模型(AlexNet,VGG,GoogLeNet,Inception,Xception也很流行的模型)。它是一种基于残余连接的50层深度神经网络架构,残连接差是为每层增加修改的连接(注意,是修改)。
我们通过七个步骤完成Alien vs. Predator任务:
- 准备数据集
- 导入依赖项
- 创建数据生成器
- 创建网络
- 训练模型
- 保存并加载模型
- 对样本测试图像进行预测
我们在Jupyter Notebooks(Keras-ResNet50.ipynb,PyTorch-ResNet50.ipynb)中使用Python代码补充了这篇博客文章。这种环境比裸脚本更便于原型设计,因为我们可以逐个单元地执行它并将峰值输出到输出中。
好的,我们走吧!
0.准备数据集
我们通过谷歌搜索“alien”和“predator”来创建数据集。我们保存了JPG缩略图(大约250×250像素)并手动过滤了结果。以下是一些例子:

我们将数据分为两部分:
- 训练数据(每类347个样本) - 用于训练网络。
- 验证数据(每类100个样本) - 在训练期间不使用,以检查模型在以前没有看过的数据上的性能。
Keras要求以下列方式将数据集放在文件夹中:
|-- train
|-- alien
|-- predator
|-- validation
|-- alien
|-- predator
如果要查看将数据组织到目录中的过程,可以查看data_prep.ipynb文件。
Kaggle下载数据集:https://www.kaggle.com/pmigdal/alien-vs-predator-images
1.导入依赖项
我们假设你有Python 3.5+,Keras 2.2.2(带有TensorFlow 1.10.1后端)和PyTorch 0.4.1。具体需求可查看requirements.txt文件。
首先,我们需要导入所需的模块。我们将Keras,PyTorch和他们共有的代码(两者都需要)分开。
共有
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
KERAS
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import ResNet50
from keras.applications.resnet50 import preprocess_input
from keras import Model, layers
from keras.models import load_model, model_from_json
PYTORCH
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
我们可以分别键入keras .__ version__ 和torch .__ version__来检查框架的版本。
2.创建数据生成器
通常,图像不能一次全部加载,因为这样内存会不够。并且,我们希望通过一次处理少量图像来从GPU中受益。因此,我们使用数据生成器分批加载图像(例如,一次32个图像)。每次遍历整个数据集都称为一个训练周期(epoch,或者说一次迭代)。
我们还使用数据生成器进行预处理:我们调整图像大小并将其标准化,以使它们像ResNet-50一样(224 x 224像素,带有缩放的颜色通道)。最后但并非最不重要的是,我们使用数据生成器随机扰动图像:

执行此类更改称为数据增强(data augmentation)。我们用它来告诉神经网络,哪种变化无关紧要。或者,换句话说,我们通过基于原始数据集生成的新图像来获得可能无限大的数据集。
几乎所有的视觉任务都在不同程度上受益于训练的数据增加。在我们的案例中,我们随机剪切,缩放和水平翻转我们的异形和铁血战士。
因此,我们创建生成器的步骤是:
- 从文件夹加载数据
- 标准化数据(训练和验证)
- 数据增强(仅限训练)
KERAS
train_datagen = ImageDataGenerator(
shear_range=10,
zoom_range=0.2,
horizontal_flip=True,
preprocessing_function=preprocess_input)
train_generator = train_datagen.flow_from_directory(
'data/train',
batch_size=32,
class_mode='binary',
target_size=(224,224))
validation_datagen = ImageDataGenerator(
preprocessing_function=preprocess_input)
validation_generator = validation_datagen.flow_from_directory(
'data/validation',
shuffle=False,
class_mode='binary',
target_size=(224,224))
PYTORCH
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
data_transforms = {
'train':
transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomAffine(0, shear=10, scale=(0.8,1.2)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize]),
'validation':
transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize])}
image_datasets = {
'train':
datasets.ImageFolder('data/train', data_transforms['train']),
'validation':
datasets.ImageFolder('data/validation', data_transforms['validation'])}
dataloaders = {
'train':
torch.utils.data.DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True,
num_workers=4),
'validation':
torch.utils.data.DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False,
num_workers=4)}
在Keras中,你可以使用内置的增强和preprocess_input 方法来标准化图像,但你无法控制它们的顺序。在PyTorch中,必须手动标准化图像,但你可以以任何你喜欢的方式安排增强。
还有其他细微差别:例如,Keras默认使用边界像素填充增强图像的其余部分(如上图所示),而PyTorch用黑色。每当一个框架比另一个更好地处理你的任务时,请仔细查看它们是否执行相同的预处理(我几乎可以肯定他们不同)。
3.创建网络
下一步是导入预训练好的ResNet-50模型,这在两种情况下都是轻而易举的。我们保持所有ResNet-50的卷积层不变,仅训练最后两个完全连接(稠密)层。由于我们的分类任务只有2个类,我们需要调整最后一层(ImageNet有上千个)。
也就是说,我们:
- 加载预训练好的网络,减掉头部并固定权重,
- 添加自定义稠密层(我们选择128个神经元的隐藏层),
- 设置优化器和损失函数。
KERAS
conv_base = ResNet50(include_top=False,
weights='imagenet')
for layer in conv_base.layers:
layer.trainable = False
x = conv_base.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(128, activation='relu')(x)
predictions = layers.Dense(2, activation='softmax')(x)
model = Model(conv_base.input, predictions)
optimizer = keras.optimizers.Adam()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
PYTORCH
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.resnet50(pretrained=True).to(device)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 2)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters())我们很容易从Keras和PyTorch加载ResNet-50。他们还提供了其他许多有名的预训练架构。那么,它们有什么区别?
在Keras中,我们可以仅导入特征提取层,不加载外来数据(include_top = False)。然后,我们使用基本模型的输入和输出以功能性的方式创建模型。然后我们使用 model.compile(...)将损失函数,优化器和其他指标放入其中。
在PyTorch中,模型是一个Python对象。在models.resnet50中,稠密层存储在model.fc属性中。我们重写它们。损失函数和优化器是单独的对象。对于优化器,我们需要显式传递我们希望它更新的参数列表。

在PyTorch中,我们应该使用.to(device)方法显式地指定要加载到GPU的内容。每当我们打算在GPU上放置一个对象时,我们都必须编写它。
冻结层的工作方式与此类似。然而,在 Keras 的批量标准化层中,它被破坏了 (截至当前版本,详见http://blog.datumbox.com/the-batch-normalization-layer-of-keras-is-broken/)。也就是说,无论如何都会修改一些层,即使 trainable = False。
Keras和PyTorch以不同的方式处理log-loss。
在Keras中,网络预测概率(具有内置的softmax函数),其内置成本函数假设它们使用概率工作。
在PyTorch中我们更加自由,但首选的方法是返回logits。这是出于数值原因,执行softmax然后log-loss意味着执行多余的log(exp(x))操作。因此,我们使用LogSoftmax(和NLLLoss)代替使用softmax,或者将它们组合成一个nn.CrossEntropyLoss 损失函数。
4.训练模型

我们继续进行最重要的一步 - 模型训练。我们需要传递数据,计算损失函数并相应地修改网络权重。虽然Keras和PyTorch在数据增强方面已经存在一些差异,但代码长度差不多。但在训练这一步,差的就很多了。
在这里,我们:
- 训练模型,
- 测量损失函数(log-loss)和训练和验证集的准确性。
KERAS
history = model.fit_generator(
generator=train_generator,
epochs=3,
validation_data=validation_generator)
PYTORCH
def train_model(model, criterion, optimizer, num_epochs=3):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(image_datasets[phase])
epoch_acc = running_corrects.double() / len(image_datasets[phase])
print('{} loss: {:.4f}, acc: {:.4f}'.format(phase,
epoch_loss,
epoch_acc))
return model
model_trained = train_model(model, criterion, optimizer, num_epochs=3)
在Keras中,model.fit_generator执行训练......然后就没了!在Keras的训练就是这么简单。正如你在notebook中所看到的,Keras还为我们提供了进度条和计时功能。但如果你想做任何非标准的事情,那你就有的头疼了。

PyTorch与此截然不同。这里一切都是明确的。你需要更多行代码来构建基本训练,但你可以随意更改和自定义你想要的所有内容。
让我们剖析下PyTorch训练代码。我们有嵌套循环,迭代:
- 迭代次数,
- 训练和验证阶段,
- 批次。
epoch循环很好理解,只是重复里面的代码。训练和验证阶段:
- 一些特殊的层,如批量标准化(出现在ResNet-50中)和dropout(在ResNet-50中不存在),在训练和验证期间的工作方式不同。我们分别通过model.train()和model.eval()设置它们的行为。
- 当然,我们使用不同的图像进行训练和验证。
- 最重要但也很容易理解的事情:我们只在训练期间训练网络。magic命令optimizer.zero_grad(),loss.backward()和 optimizer.step()(按此顺序)完成工作。如果你理解什么是反向传播,你就会欣赏它们的优雅。
我们负责计算迭代的损失并打印。
5.保存并加载模型
保存
一旦我们的网络经过训练,通常这需要很高的计算和时间成本,最好将其保存以备以后使用。一般来说,有两种类型保存:
- 将整个模型结构和训练权重(以及优化器状态)保存到文件中,
- 将训练过的权重保存到文件中(将模型架构保留在代码中)。
你可以随意选择。在这里,我们保存模型。
KERAS
# architecture and weights to HDF5
model.save('models/keras/model.h5')
# architecture to JSON, weights to HDF5
model.save_weights('models/keras/weights.h5')
with open('models/keras/architecture.json', 'w') as f:
f.write(model.to_json())
PYTORCH
torch.save(model_trained.state_dict(),'models/pytorch/weights.h5')

两个框架中都有一行代码就足够了。在Keras中,可以将所有内容保存到HDF5文件,或将权重保存到HDF5,并将架构保存到可读的json文件中。另外,你可以加载模型并在浏览器中运行它。
目前,PyTorch创建者建议仅保存权重。他们不鼓励保存整个模型,因为API仍在不断发展。
加载
加载模型和保存一样简单。你需要记住你选择的保存方法和文件路径。
KERAS
# architecture and weights from HDF5
model = load_model('models/keras/model.h5')
# architecture from JSON, weights from HDF5
with open('models/keras/architecture.json') as f:
model = model_from_json(f.read())
model.load_weights('models/keras/weights.h5')
PYTORCH
model = models.resnet50(pretrained=False).to(device)
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 2)).to(device)
model.load_state_dict(torch.load('models/pytorch/weights.h5'))
在Keras中,我们可以从JSON文件加载模型,而不是在Python中创建它(至少在我们不使用自定义层时不需要这样)。这种序列化方便了转换模型。
PyTorch可以使用任何Python代码。所以我们必须在Python中重新创建一个模型。在两个框架中加载模型权重比较类似。
6.对测试样本图像进行预测
为了公平地检查我们的解决方案的质量,我们要求模型预测未用于训练的图像中怪物的类型。我们可以使用验证集或者任何其他图像。
在这里,我们:
- 加载和预处理测试图像
- 预测图像类别
- 显示图像和预测
共有
validation_img_paths = ["data/validation/alien/11.jpg",
"data/validation/alien/22.jpg",
"data/validation/predator/33.jpg"]
img_list = [Image.open(img_path) for img_path in validation_img_paths]
KERAS
validation_batch = np.stack([preprocess_input(np.array(img.resize((img_size, img_size))))
for img in img_list])
pred_probs = model.predict(validation_batch)
PYTORCH
validation_batch = torch.stack([data_transforms['validation'](img).to(device)
for img in img_list])
pred_logits_tensor = loaded_model(validation_batch)
pred_probs = F.softmax(pred_logits_tensor, dim=1).cpu().data.numpy()
共有
fig, axs = plt.subplots(1, len(img_list), figsize=(20, 5))
for i, img in enumerate(img_list):
ax = axs[i]
ax.axis('off')
ax.set_title("{:.0f}% Alien, {:.0f}% Predator".format(100*pred_probs[i,0],
100*pred_probs[i,1]))
ax.imshow(img)
像训练一样,预测也分批进行(这里我们一批3个,也可以每批1个)。在Keras和PyTorch中,我们需要加载和预处理数据。新手常见的错误是忘记了预处理步骤(包括颜色缩放)。也许方法仍然有效,但会导致糟糕的预测(因为它能有效地看到相同的形状,但不能有效看到不同的颜色和对比度)。
在PyTorch中还有两个步骤,因为我们需要:
- 将logits转换为概率,
- 将数据传输到CPU并转换为NumPy(当我们忘记此步骤时,错误消息会很明白的告诉你)。
下面就是我们得到的:

成功了!你也可以使用其他图像。如果你无法想出任何其他(或任何人),可以尝试使用你同事的照片。
结论
现在你看到了,Keras和PyTorch在如何定义,修改,训练,评估和导出标准深度学习模型方面的差异。有些部分,它纯粹是针对不同的API约定,而其他部分,则涉及抽象级别之间的基本差异。
Keras在更高级别的抽象上运行。它更加即插即用,通常更简洁,但这是以灵活性为代价的。
PyTorch提供更明确和详细的代码。在大多数情况下,它意味着可调试和灵活的代码,只需多费一点时间。然而,PyTorch的训练更加冗长,但有时这会提供很大的灵活性。
github:https://github.com/deepsense-ai/Keras-PyTorch-AvP-transfer-learning
Kaggle kernels:https://www.kaggle.com/pmigdal/alien-vs-predator-images/kernels
Neptune:https://app.neptune.ml/deepsense-ai/Keras-vs-PyTorch

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消