


















一份详细的LSTM和GRU图解
在这篇文章中,我们将从LSTM和GRU背后的直觉开始。然后我(Michael)将解释使LSTM和GRU表现良好的内部机制。如果你想了解这两个网络背后的机制,那么这篇文章就是为你准备的。
短期记忆
RNN受到短期记忆的影响。如果序列很长,他们将很难将信息从较早的时间步传送到后面的时间步。因此,如果你尝试处理一段文本进行预测,RNN可能会遗漏开头的重要信息。
在反向传播期间,RNN存在梯度消失的问题(梯度用于更新神经网络权重的值)。梯消失度问题是当梯度反向传播随着时间的推梯度逐渐收缩。如果梯度值变得非常小,则不会产生太多的学习。

梯度更新规则
因此,在递归神经网络中,获得小梯度更新的层会停止学习。那些通常是较早的层。因为这些层不再学习,RNN会忘记它在较长序列中看到的内容,因此只有短期记忆。
LSTM和GRU解决方案
LSTM和GRU是作为短期记忆的解决方案而创建的。它们具有称为门(gate)的内部机制,它可以调节信息流。
这些门可以了解序列中哪些数据重要以进行保留或丢弃。这样,它可以将相关信息传递到长序列中进行预测。现有的基于RNN的几乎所有技术结果都是通过LSTM和GRU这两个网络实现的。LSTM和GRU进行语音识别,语音合成和文本生成,甚至可以使用它们为视频生成字幕。
将通过直观的解释和插图来进行解释,尽量避免使用数学。
直觉
让我们从一个思想实验开始。假设你在网上查看评论来决定你是否要买Life麦片。你会首先阅读评论,确定某人认为麦片好不好
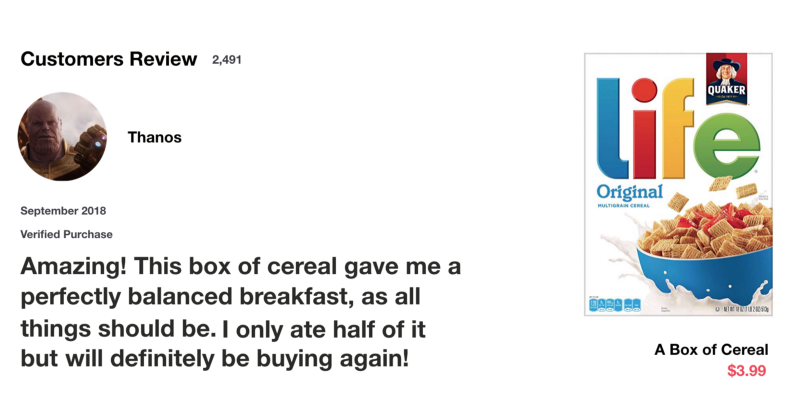
当你阅读评论时,你的大脑下意识地只会记住重要的关键词。你会选择“amazing”和“perfectly balanced breakfast”这样的词汇。你不太关心“this”,“give”,“all”,“should”等字样。如果朋友第二天问你评论说什么,你一般不会一字不漏地记住它。你可能还记得主要观点,比如“will definitely be buying again”。如果你是这样,那么其他的单词就会从记忆中逐渐消失。

这就是LSTM或GRU的作用。它可以学习只保留相关信息来进行预测,忘记不相关的数据。在这种情况下,你记得的单词让你判断麦片是好的。
RNN的回顾
为了理解LSTM或GRU如何实现这一点,让我们回顾一下RNN。RNN的工作原理是:第一个词被转换成机器可读的向量。然后RNN逐个处理向量序列。 
逐个处理序列
处理时,它将先前的隐藏状态传递给序列的下一步。隐藏状态充当神经网络的记忆。它保存着网络以前见过的数据信息。
将隐藏状态传递给下一个时间步
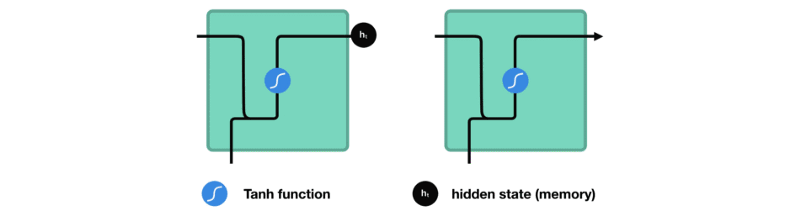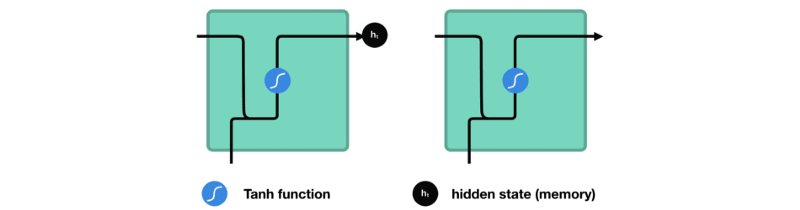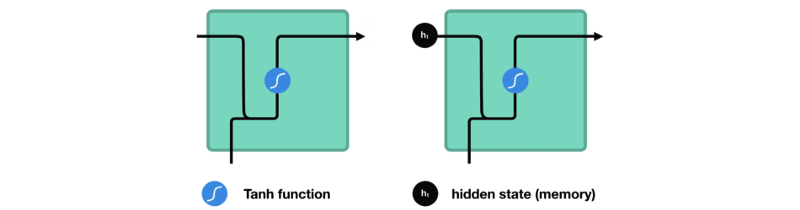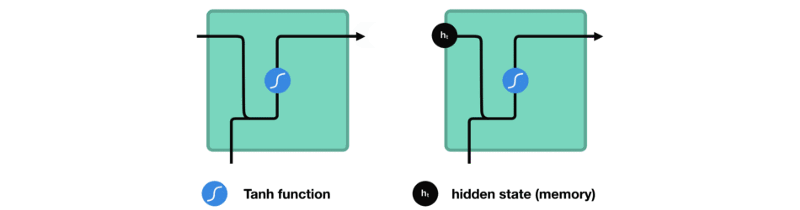
让我们观察RNN的一个单元格,看看如何计算隐藏状态。首先,将输入和先前隐藏状态组合成一个向量。这个向量现在含有当前输入和先前输入的信息。向量经过tanh激活,输出新的隐藏状态,或网络的记忆。
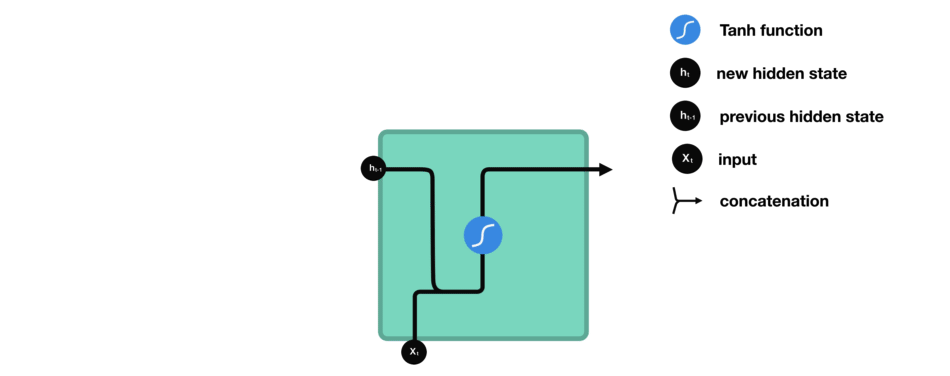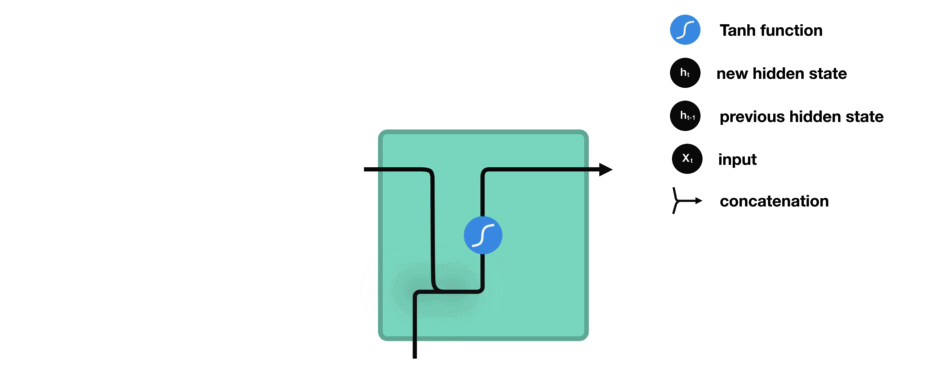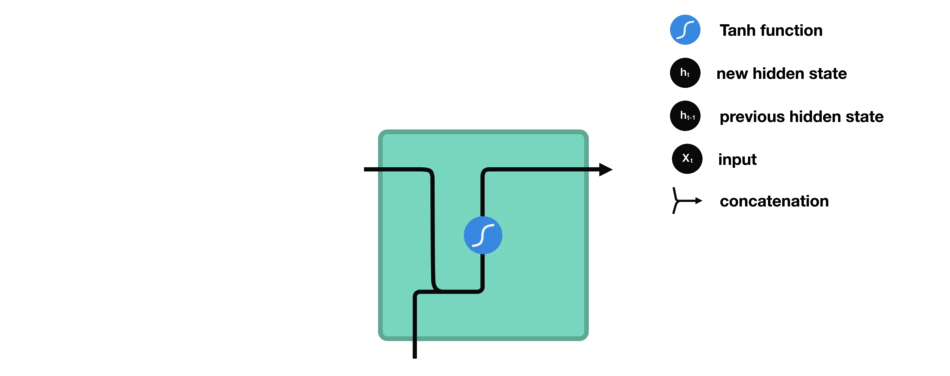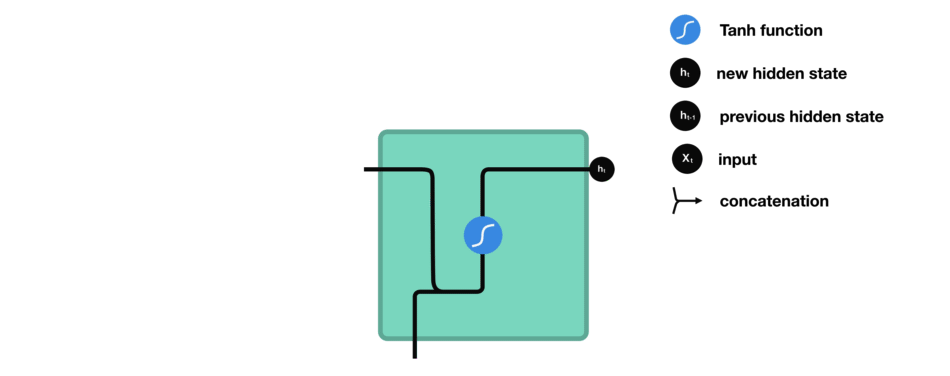
RNN细胞
Tanh激活
tanh激活用于帮助调节流经网络的值。tanh函数将值压缩在-1和1之间。
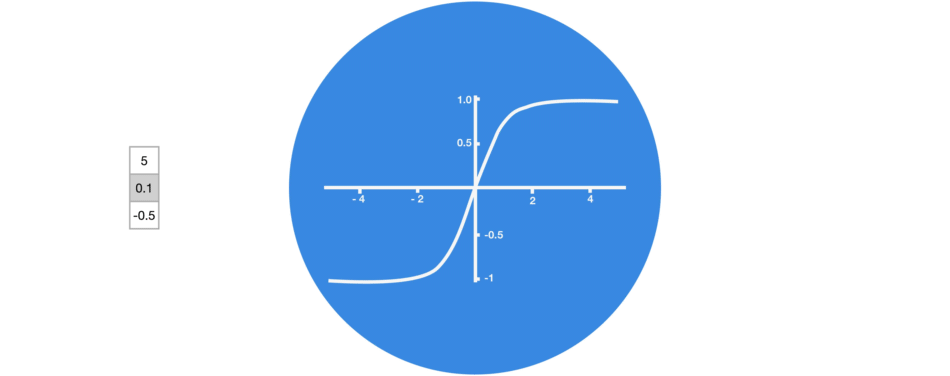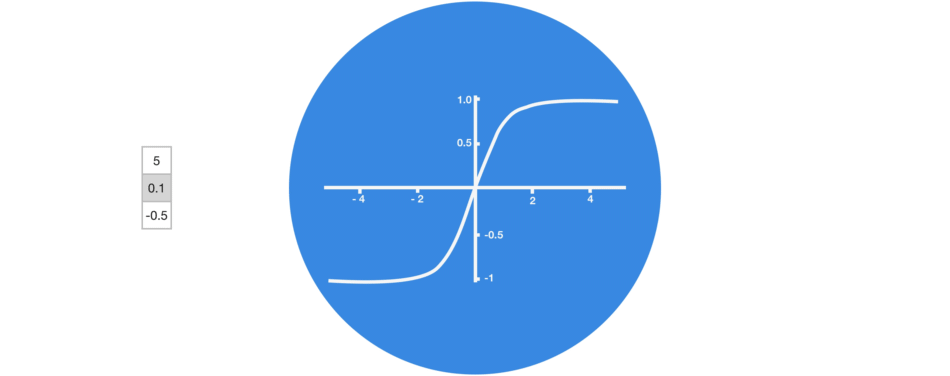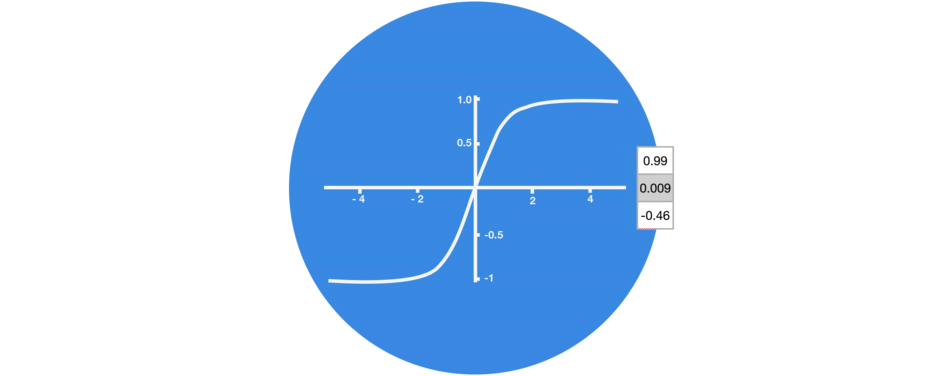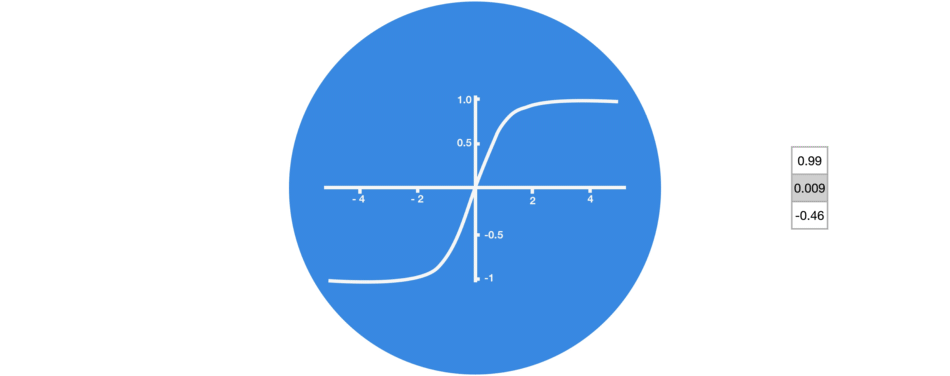
Tanh将值压缩到-1和1之间
当向量流经神经网络时,由于各种数学运算,它经历了许多变换。假设一个值连续乘以3。你可以看到某些值如何爆炸增长的,导致其他值看起来微不足道。

没有tanh的矢量变换
tanh函数确保值在-1和1之间,从而调节神经网络的输出。你可以看到上面的相同值通过tanh函数保持界限之间。

使用tanh的矢量变换
这是一个RNN。它内部的操作很少,但在适当的情况下(如短序列)工作得很好。RNN使用的计算资源比它的进化变体LSTM和GRU要少得多。
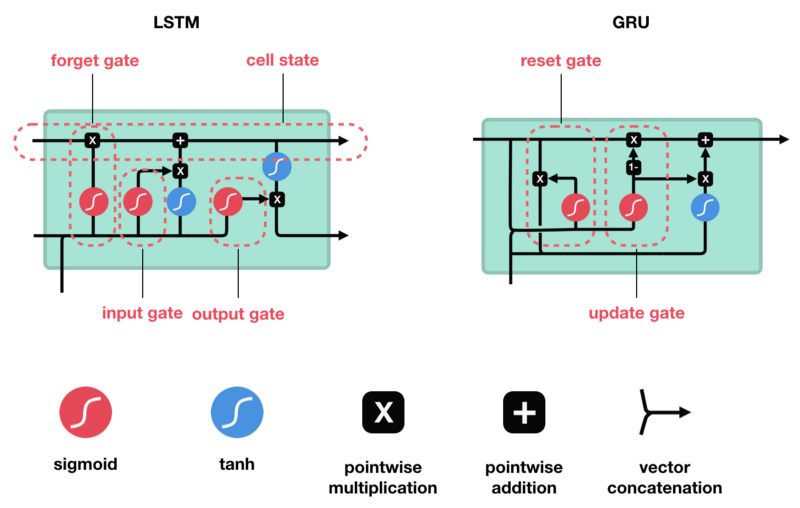
LSTM
LSTM具有与RNN类似的控制流。它在前向传播时处理传递信息的数据。区别在于LSTM单元内的操作。
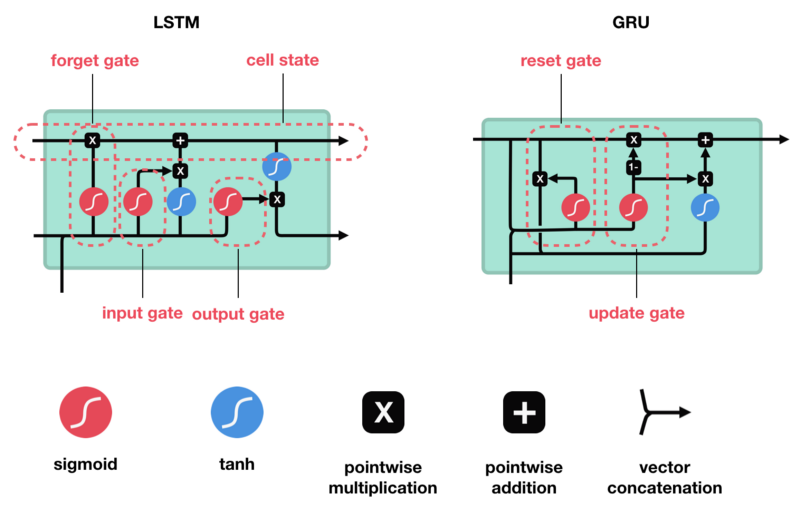
LSTM单元及其操作
这些操作用于允许LSTM保留或忘记信息。这些操作可能会有点难,所以我们将逐步介绍这些它们。
核心概念
LSTM的核心概念是单元状态(cell state),它是多种不同的门。单元状态充当传输的高速公路,在序列链中传递相关信息。你可以将其视为网络的记忆。理论上,单元状态可以在序列的整个处理过程中携带相关信息。因此,即使来自较早时间步的信息也可用于较晚时间步,从而减少短期记忆的影响。随着单元状态继续进行,信息通过门被添加或移除到单元状态。门是不同的神经网络,用来决定哪些信息可以允许进入单元状态。在训练中,门可以知道哪些信息是需要保存或忘记的。
Sigmoid
“门”包括sigmoid激活。它类似于tanh激活,但不是在-1和1之间压缩值,而是在0和1之间取值。这有助于更新或忘记数据,因为任何数字乘以0都是0,使值消失或者说被“遗忘”。任何数字乘以1都是相同的值,因此值保持相同”。网络可以了解哪些数据不重要可以被遗忘,或者哪些数据需要保存。
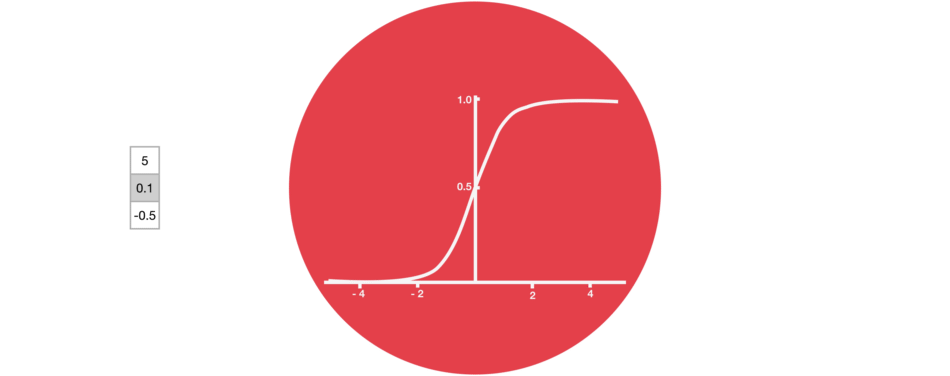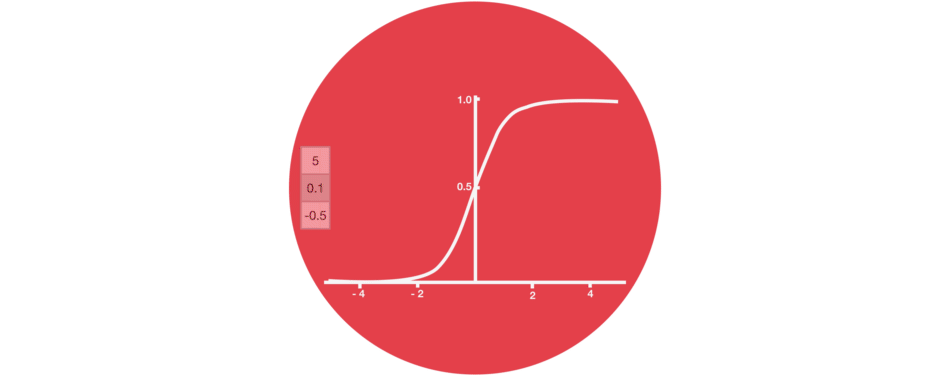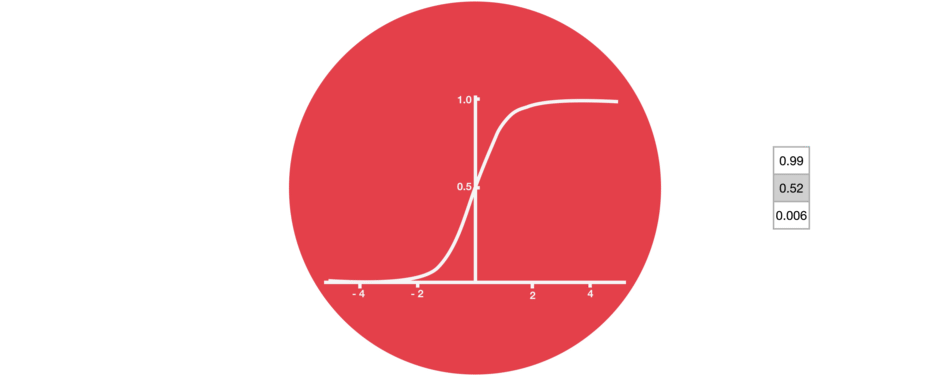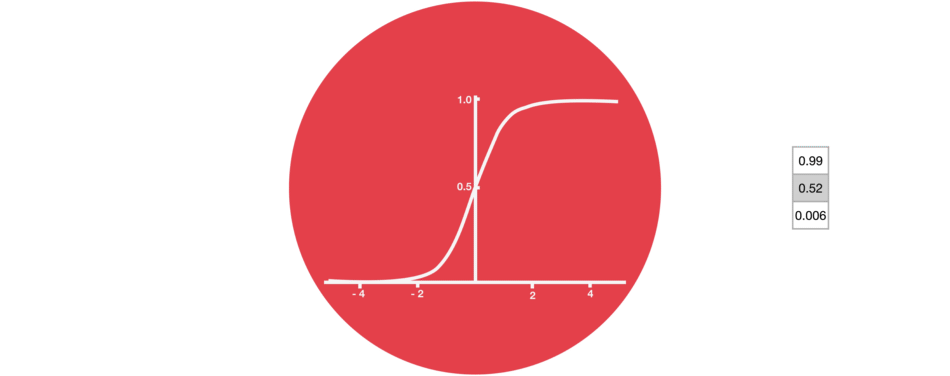
Sigmoid将值压缩至0和1之间
让我们深入了解不同的大门在做什么,不是吗?因此,我们有三个不同的门来调节LSTM单元中的信息流。忘记门,输入门和输出门。
遗忘门
首先,我们介绍遗忘门(forget gate)。此门决定应丢弃或保留哪些信息。来自先前隐藏状态和来自当前输入的信息通过sigmoid函数传递。值介于0和1之间。越接近0越容易遗忘,越接近1则意味着要保留。
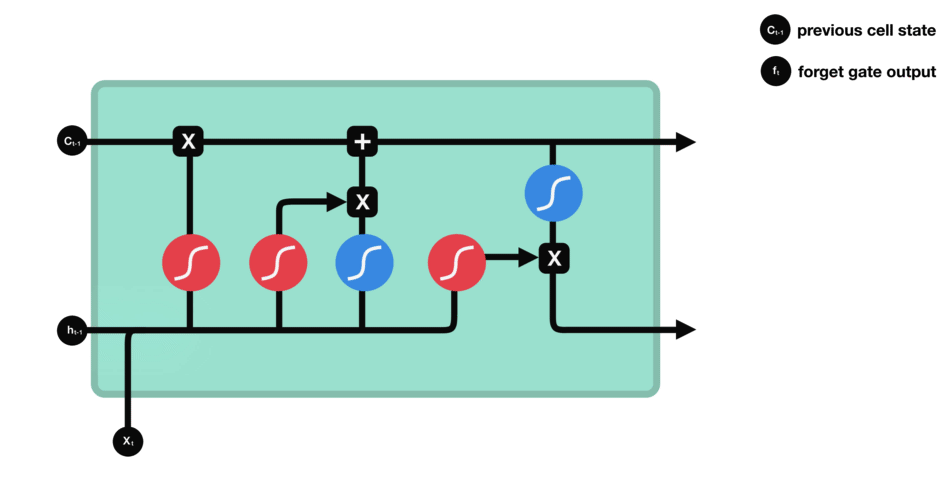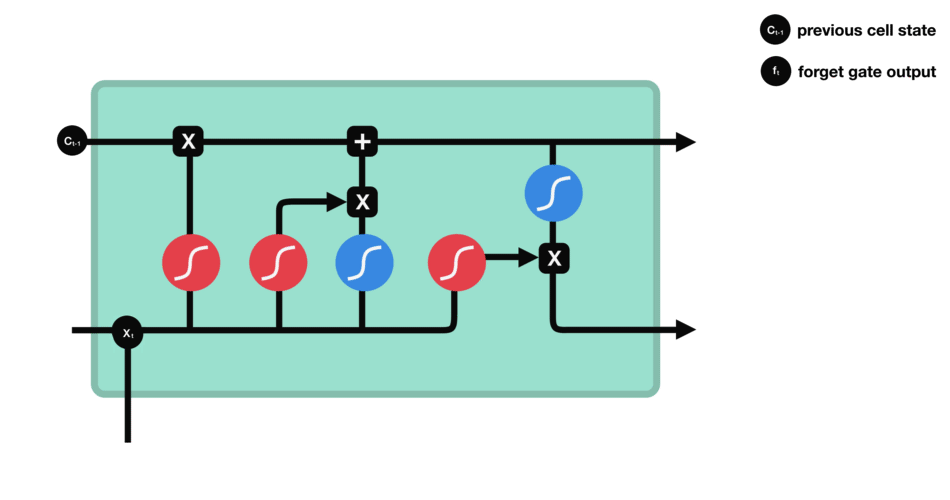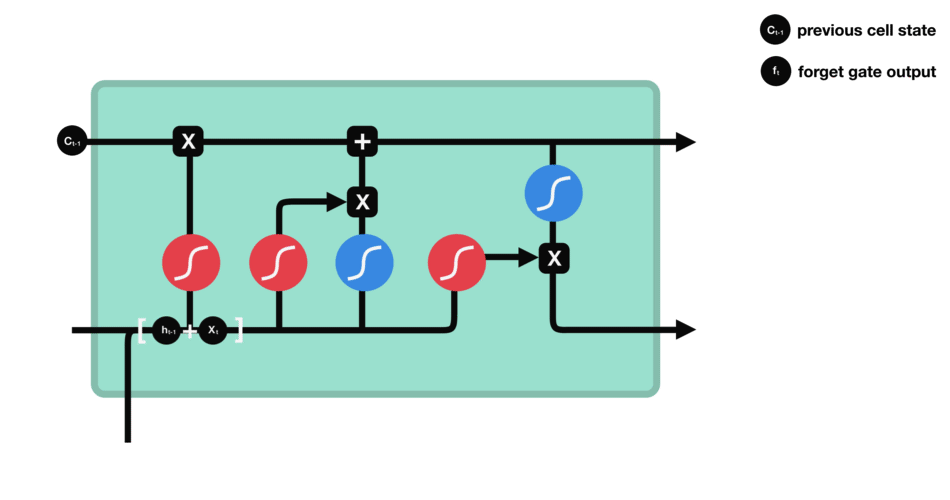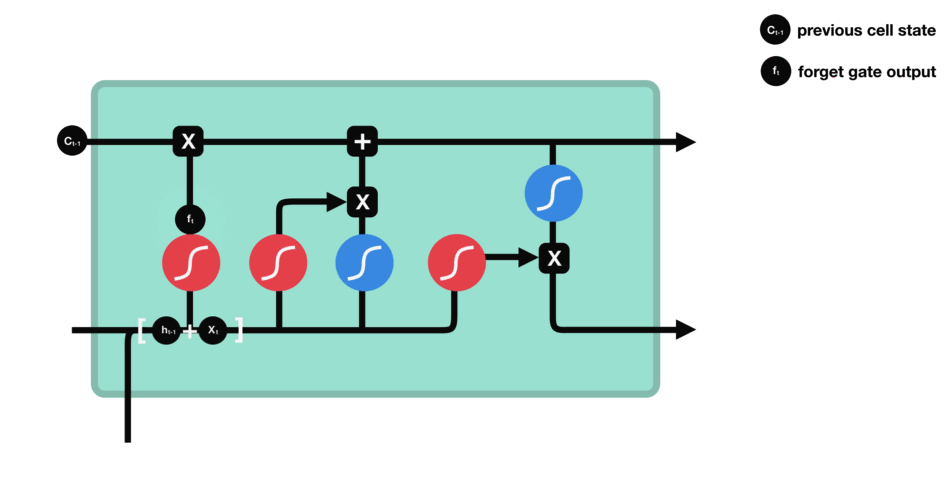
遗忘门操作
输入门
要更新单元状态,我们需要输入门。首先,我们将先前的隐藏状态和当前输入传递给sigmoid函数。这决定了通过将值转换为0到1来更新哪些值。0表示不重要,1表示重要。你还将隐藏状态和当前输入传递给tanh函数,将它们压缩到-1和1之间以帮助调节网络。然后将tanh输出与sigmoid输出相乘。sigmoid输出将决定哪些信息很重要,需要tanh输出保存。
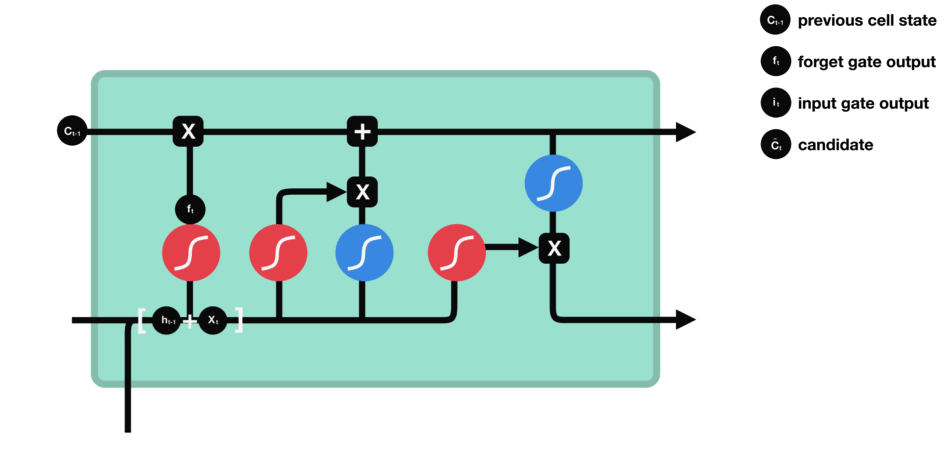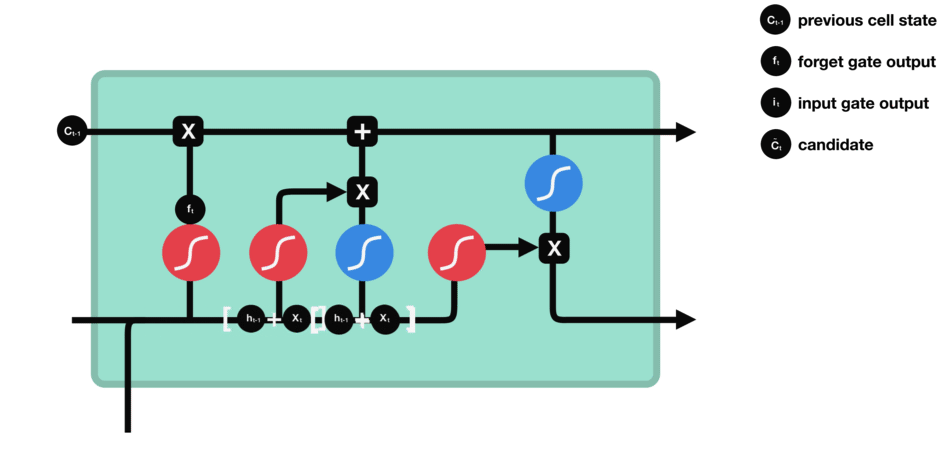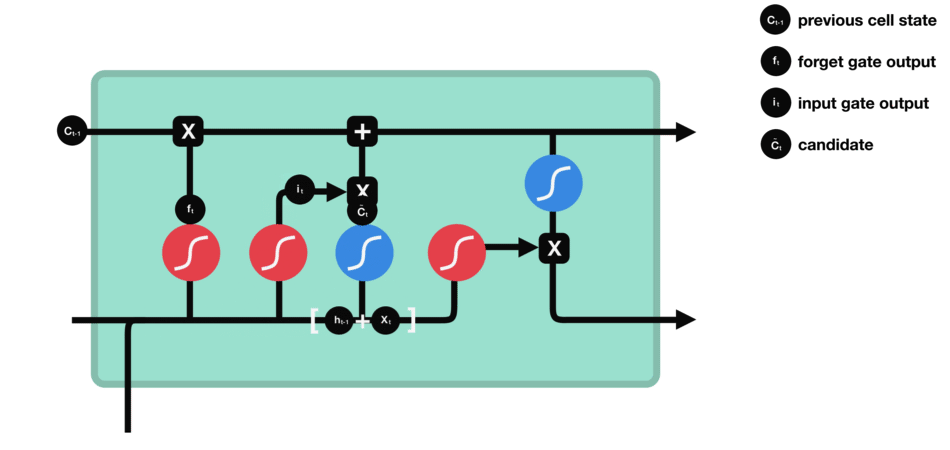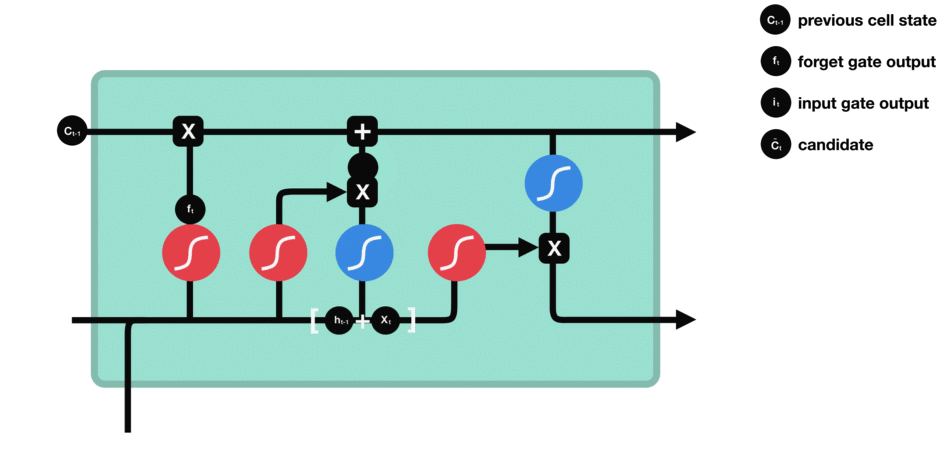
输入门操作
单元状态
现在我们有足够的信息来计算单元状态。首先,单元状态逐点乘以遗忘向量。如果它乘以接近0的值,则有可能在单元状态中丢弃值。然后我们从输入门获取输出并进行逐点加法,将单元状态更新为神经网络发现相关的新值。这就得到了新的单元状态。
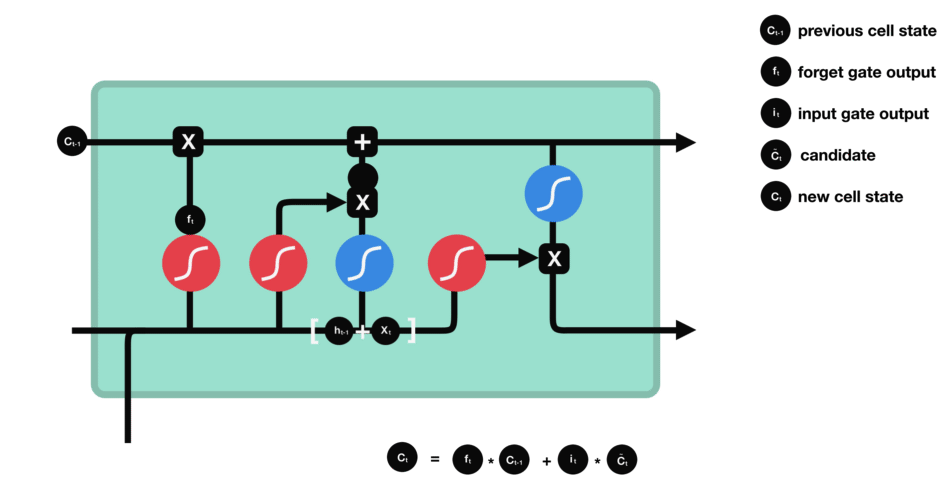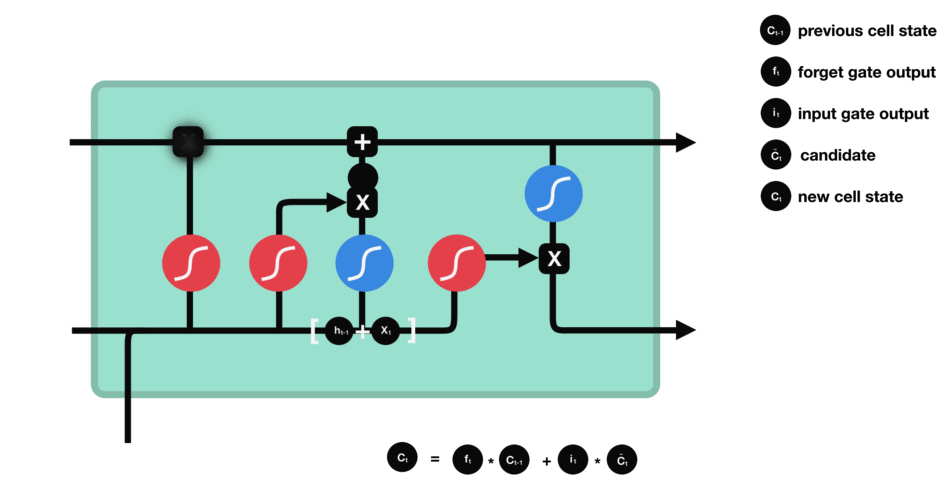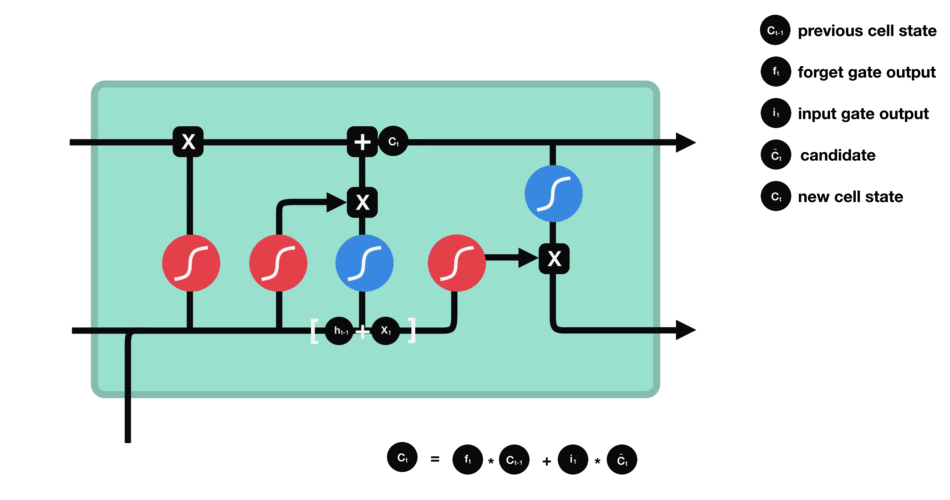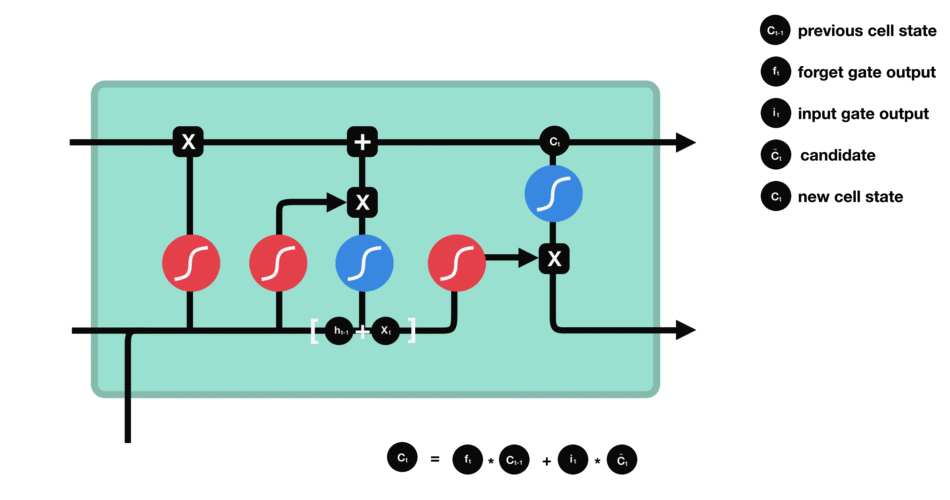
计算细胞状态
输出门
最后我们有输出门。输出门决定下一个隐藏状态是什么。请记住,隐藏状态包含有关先前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给sigmoid函数。然后我们将新的单元状态传递给tanh函数。将tanh输出与sigmoid输出相乘,以决定隐藏状态应携带的信息。它的输出是隐藏状态。然后将新的单元状态和新的隐藏状态传递到下一个时间步。
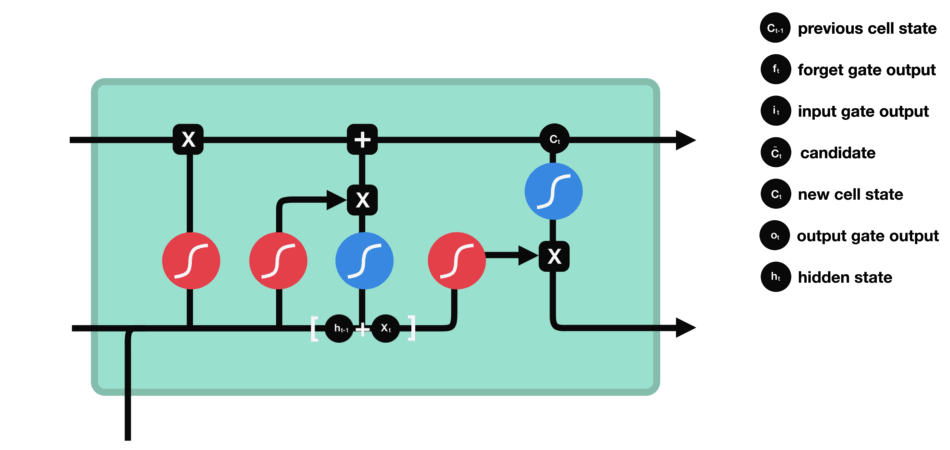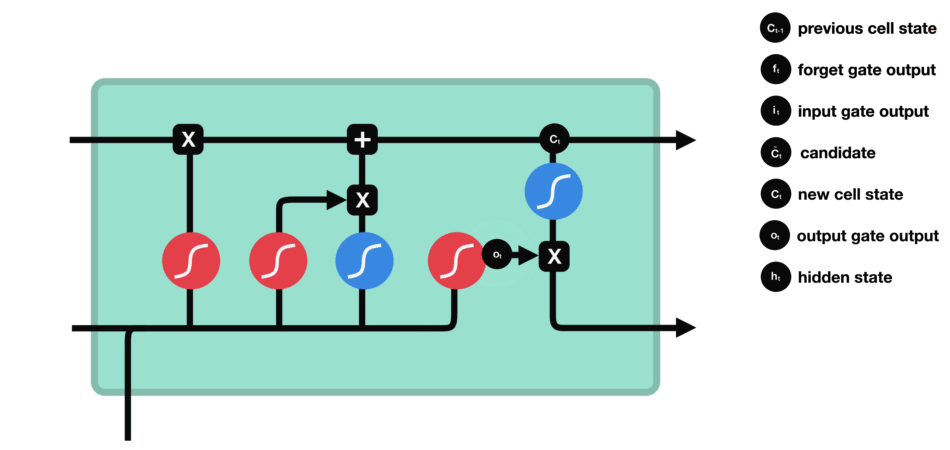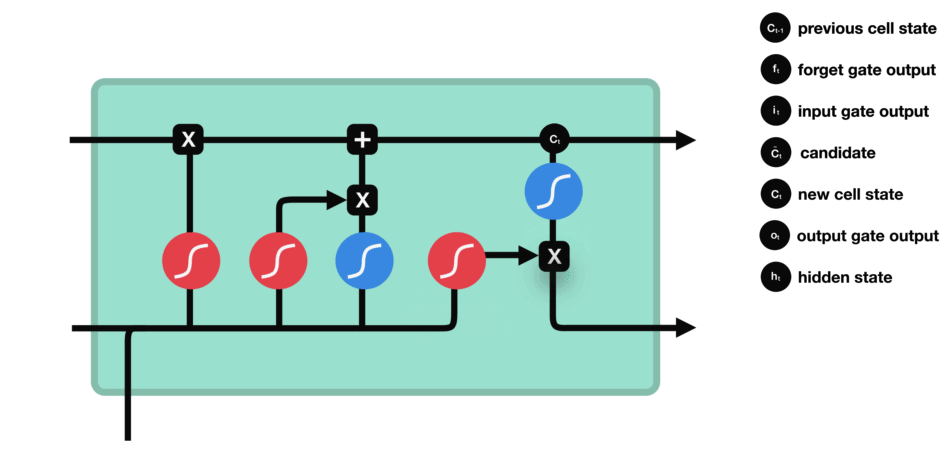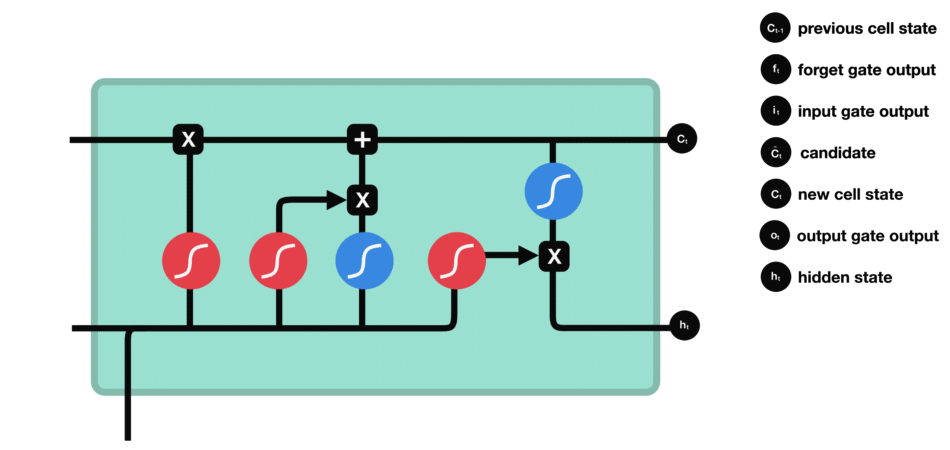
输出门操作
回顾一下,遗忘门决定了哪些内容与前面的时间步相关。输入门决定了从当前时间步添加哪些信息。输出门决定下一个隐藏状态应该是什么。
代码演示
通过查看代码有些人可以更好的理解,以下是一个使用python伪代码的例子。

python伪代码
1.首先,先前的隐藏状态和当前输入被连接起来。我们称之为组合(combine)。
2.组合的结果传入到遗忘层中。该层删除不相关的数据。
3.使用组合创建候选(candidate)层。它保存要添加到单元状态的可能值。
4. 组合也传入输入层。该层决定应将候选者中的哪些数据添加到新的单元状态。
5.在计算遗忘层,候选层和输入层之后,使用那些向量和先前的单元状态来计算单元状态。
6.然后计算输出。
7.输出和新的单元状态逐点相乘得到新的隐藏状态。
就是这些!LSTM网络的控制流程是几个张量操作和一个for循环。你可以使用隐藏状态进行预测。结合所有这些机制,LSTM能够选择在序列处理期间需要记住或忘记哪些信息。
GRU
所以现在我们知道LSTM是如何工作的,让我们简单地看一下GRU。GRU是新一代RNN,与LSTM非常相似。GRU不使用单元状态,而是使用隐藏状态来传输信息。它也只有两个门,一个重置门和一个更新门(reset gate and update gate)。
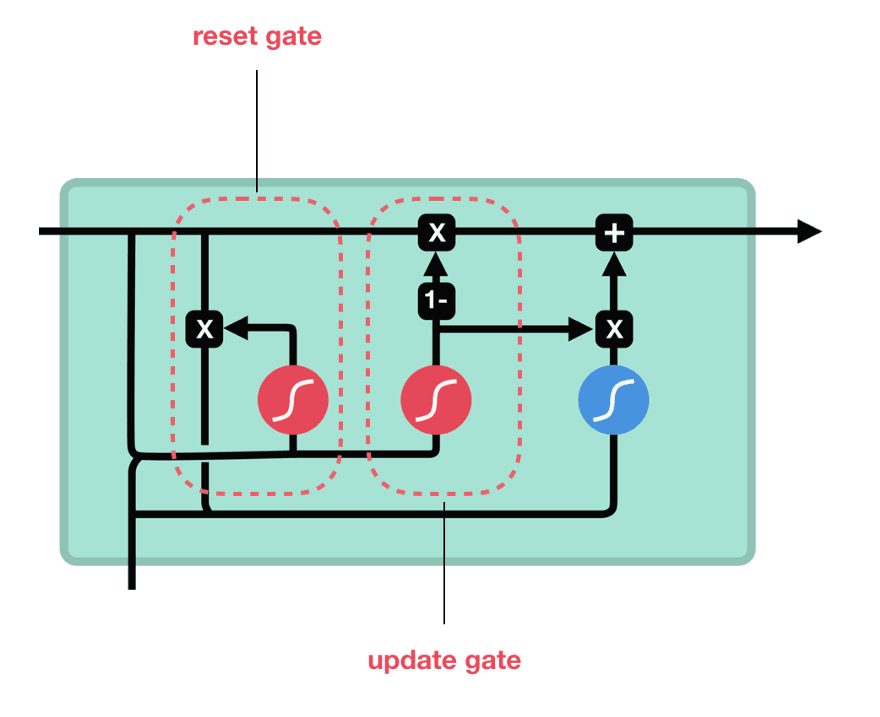
GRU单元和它的门
更新门
更新门的作用类似于LSTM的遗忘和输入门。它决定要丢弃哪些信息和要添加哪些新信息。
重置门
重置门是另一个用来决定要忘记多少过去的信息的门。
这就是GRU。GRU的张量操作较少;因此,他们的训练速度要比LSTM快一些。但还说不清哪个更好。研究人员和工程师通常都会尝试,以确定哪一个更适合他们的用例。









