


















Claude Sonnet 4.5 顶级 SWE-Bench 验证,扩展编码专注超过 30 小时

Anthropic 已发布Claude Sonnet 4.5,这是迄今为止最先进的编码模型,在代理任务、长时间任务表现和计算机使用能力方面有了重大改进。公司表示,模型的增强训练和安全方法显著改善了其行为,减少了奉承、欺骗、权力追求和妄想推理等倾向。该模型现已通过Claude API、桌面和移动应用程序以与其前身相同的价格提供。
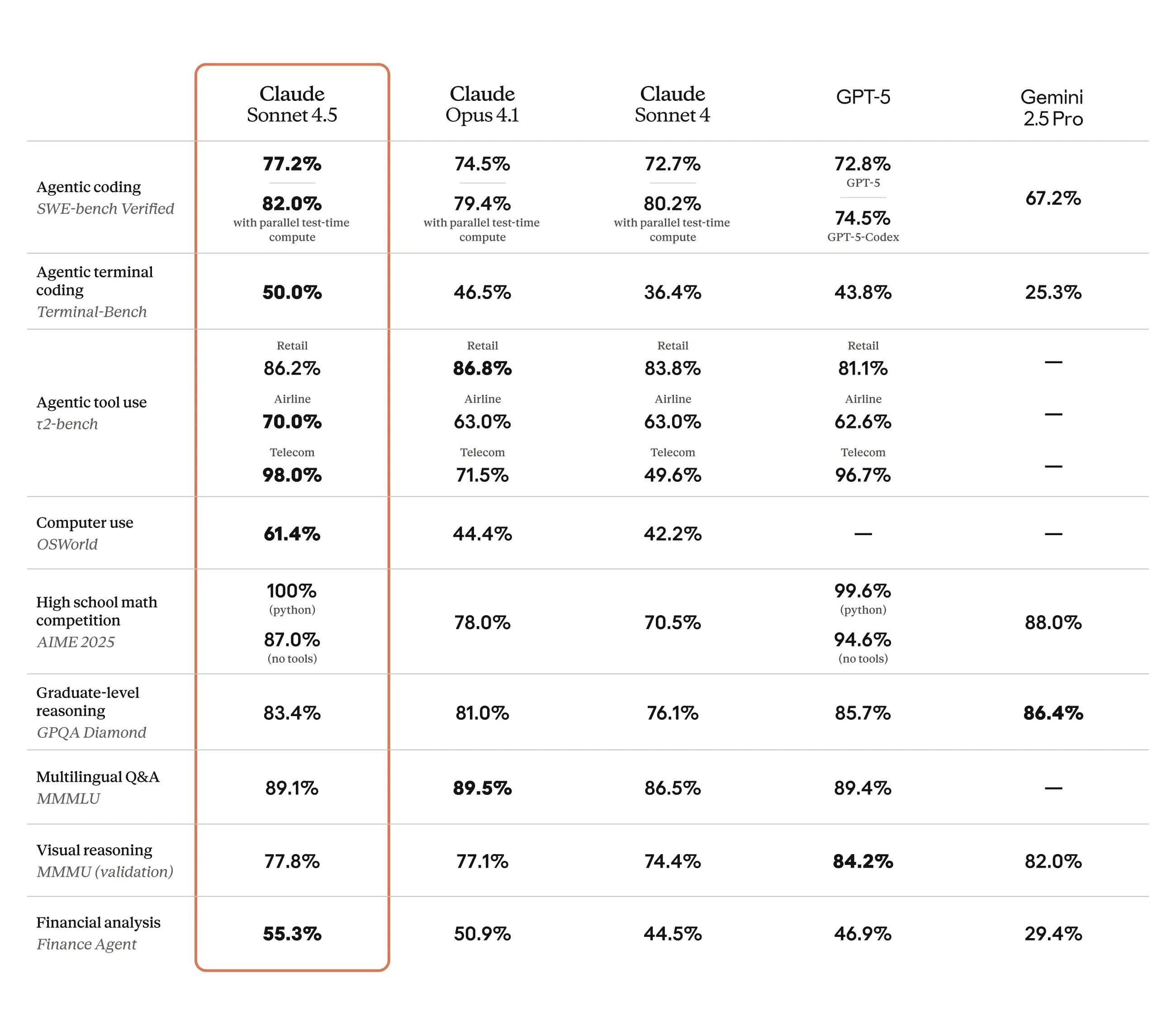
Claude Sonnet 4.5 建立在 Anthropic 逐步改进模型性能的策略之上,同时保持一致性和安全性。该模型展示了在超过 30 小时内维持复杂的多步骤推理和代码执行任务的能力。在SWE-bench 验证基准上,该基准衡量 AI 模型解决现实世界软件问题的能力,Claude Sonnet 4.5 获得了 77.2% 的分数,高于 Sonnet 4 的 72.7%,标志着自主编码能力的显著进步。在OSWorld 基准上,该基准评估现实世界的计算机使用技能,Sonnet 4.5 达到了 61.4%,相比四个月前的 42.2% 有显著提高。
Anthropic 将 Sonnet 4.5 描述为其“最一致的前沿模型”,强调了更强大能力与更严格安全措施之间的平衡。在ASL-3下,公司增强了自动分类器,能够检测并阻止潜在有害指令,包括与化学、生物、放射或核(CBRN)风险相关的指令。根据 Anthropic 的说法,自引入以来与Claude Opus 4在 2025 年 5 月发布相比,误报率下降了十倍。
为了评估 Claude Sonnet 4.5 在自主、工具支持场景中的行为,Anthropic 进行了系列代理安全测试,涵盖恶意代码生成和防御提示注入攻击。在 150 个被 Anthropic 使用政策禁止的恶意编码请求中,Claude Sonnet 4.5 仅在两个请求中失败,反映了改进的安全训练。该模型获得了 98.7% 的安全评分,相比 Claude Sonnet 4 的 89.3%,显示出显著更强的拒绝行为和对恶意代理使用的抵抗力。
Anthropic 建议所有用户升级到 Claude Sonnet 4.5,并将其视为“即插即用的替代品”,在不增加成本的情况下提供更强的性能。
早期采用者报告编码工作流程的可测量收益:
Cognition 的联合创始人兼 CEO Scott Wu 指出,“对于 Devin 来说,Claude Sonnet 4.5 将计划性能提高了 18%,端到端评估分数提高了 12%,这是自 Claude Sonnet 3.6 发布以来我们见过的最大提升。它在测试自己的代码方面表现出色,使 Devin 能够运行更长时间,处理更困难的任务,并交付生产就绪的代码。”
replit 的总裁 Michele Catasta 分享道:“Claude Sonnet 4.5 的编辑能力非常出色。我们从 Sonnet 4 的 9% 错误率降至我们内部代码编辑基准的 0%。更高的工具成功率和更低的成本是代理编码的重大飞跃。Claude Sonnet 4.5 完美平衡了创造力和控制力”
独立开源开发者 Simon Wilson 在他的博客上分享道:“我最初的印象是,它感觉比 GPT-5-Codex 更适合编码,自从几周前发布以来,它一直是我首选的编码模型”
Anthropic 推动更安全、更自主的编码模型与 AI 生态系统中的类似进步相呼应。OpenAI 最近发布了GPT-5-Codex,这是GPT-5的一个版本,专为复杂的软件工程任务优化,如大规模代码重构和扩展代码审查工作流程。









