


















谷歌悄然升级Gemini 2.5 Pro

谷歌发布了其Gemini 2.5 Pro模型的升级预览版,在编码、推理和响应质量方面的性能有所提升,为开发者在未来几周内的全面上市做好准备。
关键点
- 谷歌悄然为开发者推出了升级版的Gemini 2.5 Pro预览版。
- 该模型在编码基准测试中表现出色,并在科学和推理任务中取得了优异成绩。
- 全面上市将在“几周内”到来。
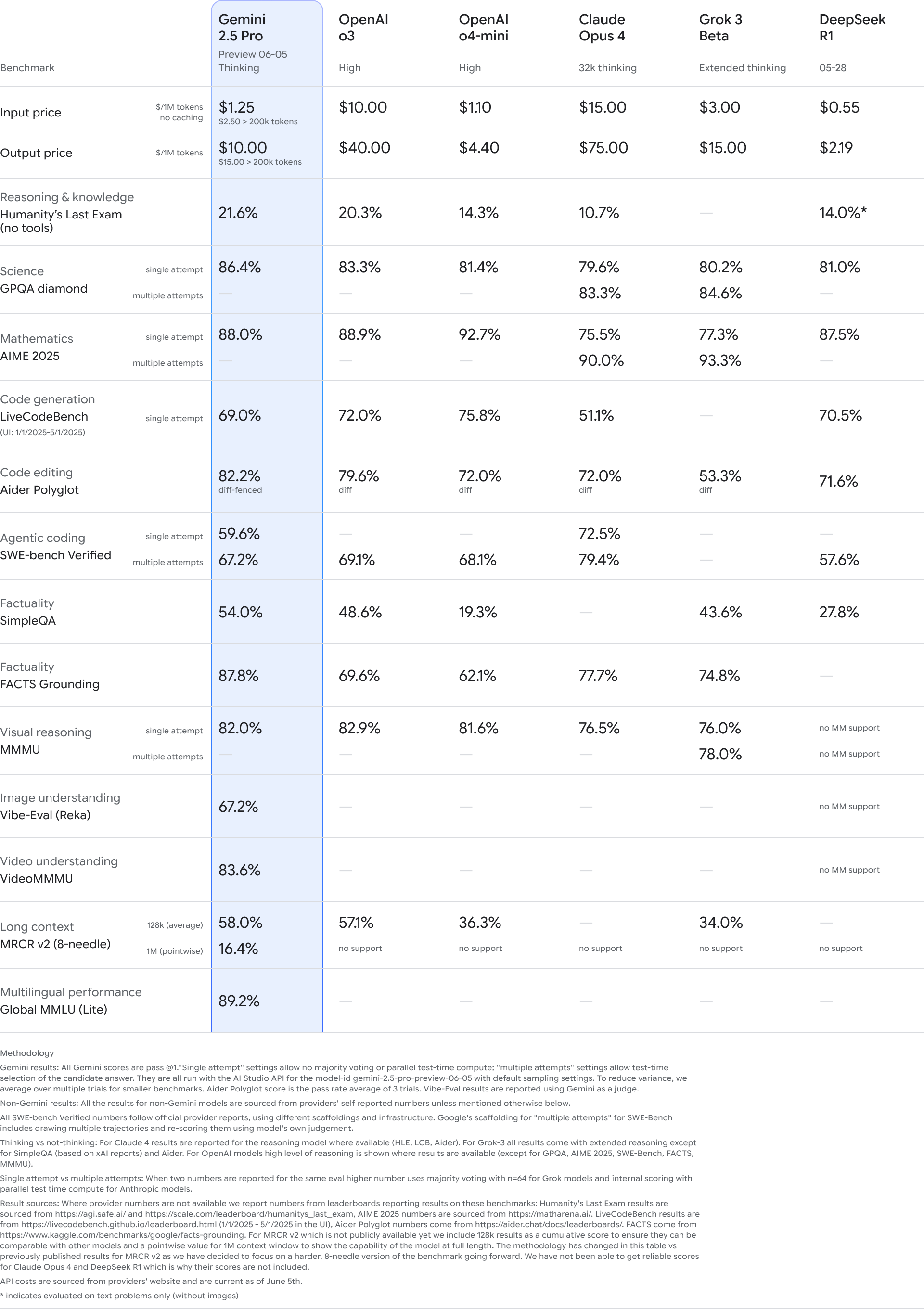
与上个月在I/O大会上宣布的版本相比,这款升级的Pro模型在各方面的性能都有所提升。在LMArena上提升了24个Elo点,仍然领先于其他领域,并在测试编码能力的WebDevArena基准测试中名列前茅。更令人印象深刻的是,它继续在Aider Polyglot基准测试中名列前茅,这是多语言编码辅助中最具挑战性的测试之一。如果你的开发团队曾因模型幻觉或推理缓慢而受挫,这是谷歌不那么隐晦的提示,建议你再试试Gemini。
它在GPQA和“人类最后的考试”(是的,这是真实的基准测试)中也得分很高,这些测试考察科学和推理能力。如果你正在为研究密集型或技术领域构建助手,这一点很重要,而不仅仅是能角色扮演或总结推文的聊天机器人。
谷歌声称它也在倾听开发者的反馈。据报道,响应结构更好、更具创意,解决了过去关于Gemini经常干巴巴或机械化语气的投诉。是否真的让使用体验更愉快——或者只是没那么烦人——我们将在更多人测试后得出结论。
这种快速的步伐反映了当前AI时刻的一个更广泛的事实:没有人能承受哪怕几个月的落后。Elo分数,自谷歌第一代Gemini Pro模型以来,已经提高了300多分。谷歌I/O 2025:桑达尔·皮查伊的开幕主题演讲而竞争对手的步伐同样迅速。OpenAI推出了o3,Anthropic刚刚发布了Claude 4,甚至像DeepSeek这样的小公司也在发布能够与大型科技巨头竞争的模型。
显而易见的是,AI军备竞赛已经达到了一个新的强度水平。当谷歌愿意在随机的星期四发布重要的模型更新,而不是等待他们的下一个大型主题演讲时,你就知道竞争压力已经从根本上改变了这些公司的运作方式。对于用户来说,这意味着更强大的AI工具不断到来。对于行业来说,这意味着没有人能在他们的基准测试上休息太久。
如果OpenAI是华丽的产品工作室,Anthropic是宪法实验室,那么谷歌似乎正在建立其作为企业级AI供应商的声誉,并不断推出产品。对于寻求前沿智能和稳定基础的开发者来说,这开始看起来是一个相当有吸引力的提议。









