


















谷歌的Gemini 2.5 Pro在AI“智商”大战中领跑编码排行榜和MENSA测试

简要概述
- 谷歌最新推出的Gemini 2.5 Pro在WebDev Arena排行榜上名列前茅,超越了Claude等竞争对手,成为开发者追求卓越编码能力的首选。
- 该AI模型拥有100万个令牌的上下文窗口(可扩展至200万个),使其能够处理远超ChatGPT和Claude 3.7 Sonnet等模型能力的大型代码库和复杂项目。
- 它在推理基准测试中也取得了最高分,包括MENSA智商测试和人类最后考试,展示了处理复杂开发任务所需的高级问题解决能力。
谷歌最近推出的Gemini 2.5 Pro已在编码排行榜上升至榜首,击败了著名的Claude。WebDev Arena——一个类似于LLM竞技场的非宗派排名网站,但专注于衡量AI模型的编码能力。这一成就正值谷歌推动其旗舰AI模型在编码和推理任务中成为领导者之际。
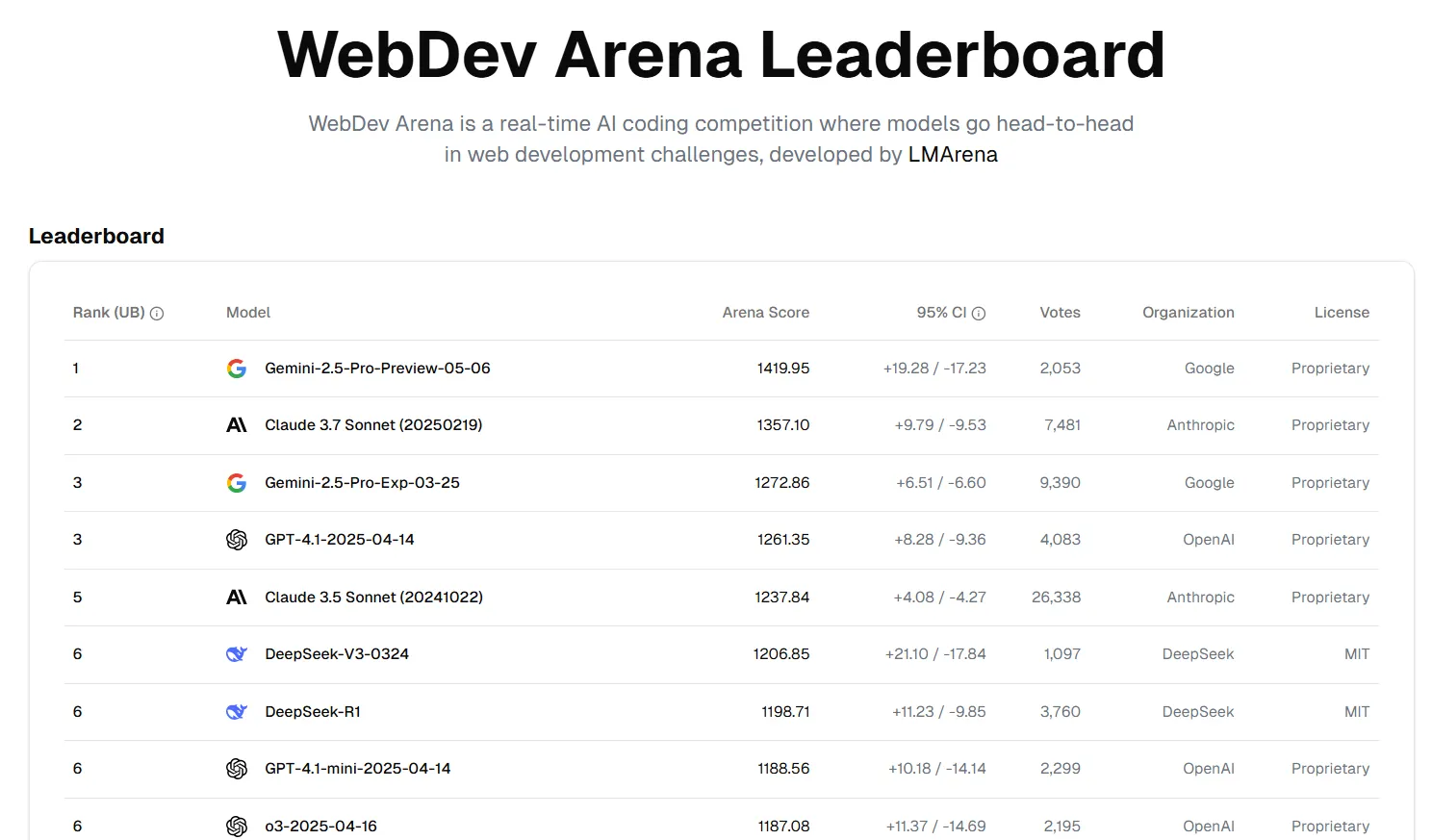
今年早些时候发布的Gemini 2.5 Pro在多个类别中排名第一包括编码、风格控制和创意写作。该模型庞大的上下文窗口——从一百万令牌扩展到两百万即将实现——使其能够处理即使是最接近的竞争对手也无法应对的大型代码库和复杂项目。作为对比,强大的模型如ChatGPT和Claude 3.7 Sonnet最多只能处理128K令牌。
Gemini也是所有AI模型中“智商”最高的。TrackingAI通过正式的MENSA测试,使用来自挪威门萨的口头问题创建了一种标准化的方式来比较AI模型。
Gemini 2.5 Pro在这些测试中得分高于竞争对手,即使使用训练数据中未公开的定制问题。
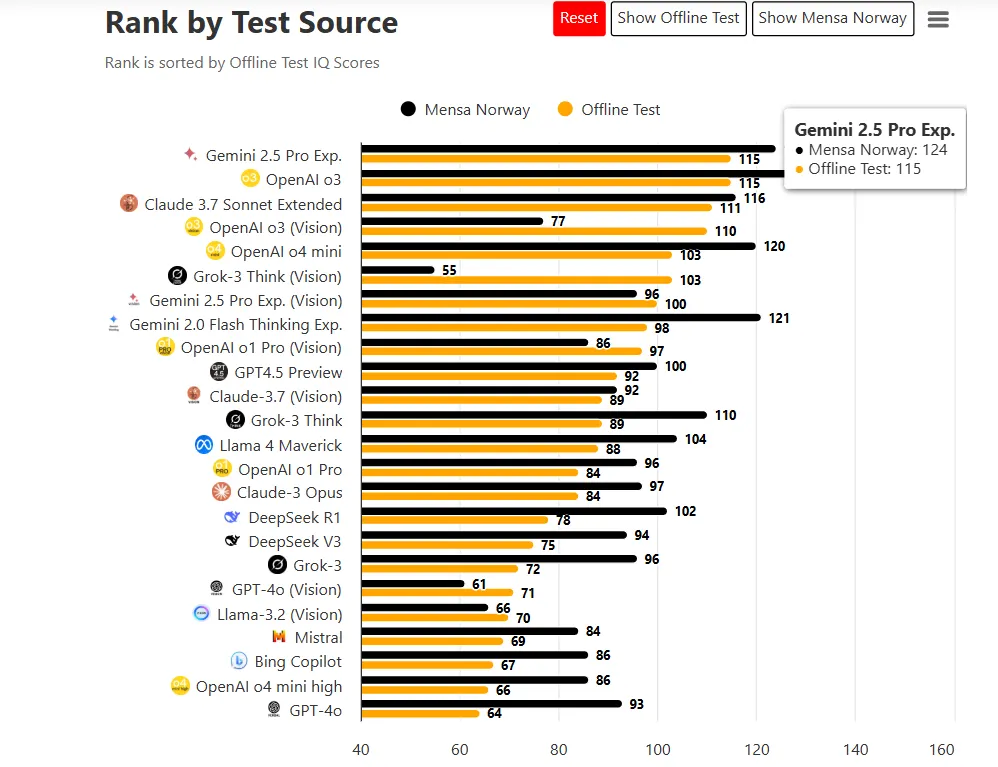
在离线测试中,新的Gemini的智商得分为115,位列“聪明才智”之列,而普通人类智力得分约为85到114分。但AI拥有智商的概念需要解读。AI系统不像人类那样拥有智商,因此更适合将基准测试视为推理基准表现的隐喻。
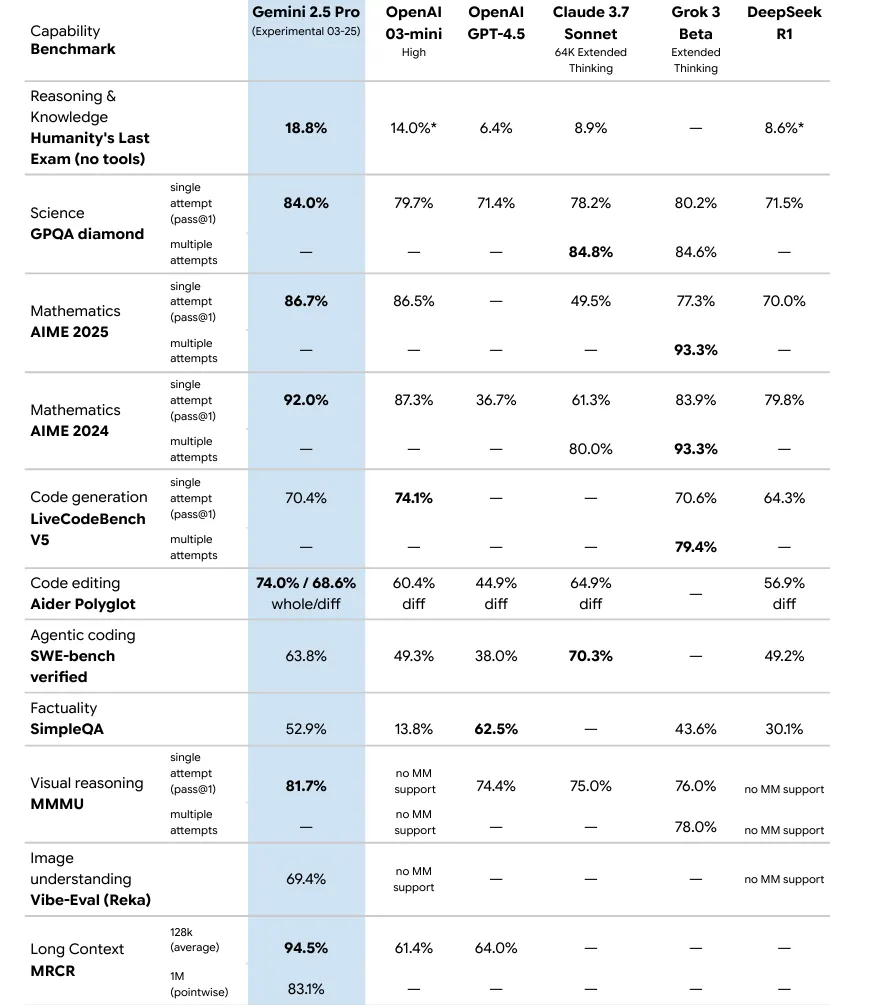
在专为AI设计的基准测试中,Gemini 2.5 Pro在AIME 2025数学测试中得分86.7%,在GPQA科学评估中得分84.0%。在人类最后考试(HLE)中,这是一项为避免测试饱和问题而创建的更新更难的基准测试,Gemini 2.5得分18.8%,击败了OpenAI的o3 mini(14%)和Claude 3.7 Sonnet(8.9%),在性能提升方面表现出色。
新版Gemini 2.5 Pro现已免费(有速率限制)向所有Gemini用户开放。谷歌此前将此版本描述为“2.5 Pro的实验版本”,是其“思考模型”家族的一部分,旨在通过推理生成响应,而不仅仅是生成文本。
尽管没有赢得所有基准测试,Gemini已凭借其多功能性引起开发者的关注。该模型可以从单一提示创建复杂应用程序,构建交互式网络应用程序、无尽奔跑游戏和视觉模拟,而无需详细说明。
我们测试了该模型,要求其修复损坏的HTML5代码。它生成了近1000行代码,提供的结果在质量和对完整指令的理解方面超过了之前的领导者Claude 3.7 Sonnet。
对于在职开发者来说,Gemini 2.5 Pro的输入成本为每百万令牌2.50美元,输出成本为每百万令牌15.00美元,定位为一些竞争对手的更便宜替代品,同时仍提供令人印象深刻的能力。
该AI模型在其高级计划中处理多达30,000行代码,使其适合企业级项目。其多模态能力——处理文本、代码、音频、图像和视频——增加了其他专注于编码的模型无法匹敌的灵活性。









