











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






加快托管LLM推理速度的7种方法
2023年08月01日 由 Alex 发表
368143
0
从小型初创公司到大型公司,公司都希望利用现代LLM的力量,并将其纳入公司的产品和基础设施中。他们面临的挑战之一是如此大的模型需要大量的资源进行部署。
加速模型推理是开发人员面临的一个重要挑战。这与降低计算资源费用和应用程序响应速度有关。
“在未来,LLM推理每加快1%,其经济价值就相当于 Google 搜索基础设施加速 1%。"——Jim Fan, NVIDIA高级人工智能科学家
这篇文章有点长,所以这里总结一下要点:
1. 使用精度降低:float16或bfloat16。这将使模型的速度提高约20%,并将内存消耗降低2倍。
2. 使用8位或4位量化可以将内存消耗减少2倍或3倍。当在内存有限的小型设备上运行时,这是最好的。注意:量化会降低预测的质量。
3. 使用适配器(LoRA、QLoRA)进行微调,以提高数据的预测准确性。可以很好地与之后的量化相结合。
4. 使用张量并行性在多个GPU上进行更快的推理以运行大型模型。
我选择了Falcon——Technology Innovation Institute发布的最新开源大型语言模型。它是一个只有解码器的自回归模型,有两个变体:70亿参数模型和400亿参数模型。40B模型变体在AWS上的384个GPU上进行了两个月的训练。
根据对模型的了解,Falcon架构与GPT-3和LLaMA非常相似,除了使用多查询注意力(Shazeer 2019)和RefinedWeb语料库作为训练数据集(这可能是成功的关键)。
多查询注意是一个概念,在不同的注意头之间共享相同的键和值张量以提高效率,如下面的多头注意块所示。
为了进行我的实验,我使用了Lit-GPT库,它包括一个开源LLM的实现,并由Lightning Fabric提供支持。至于硬件设置,我使用了单个A100 GPU,内存容量为40GB。
要启动实验,第一步包括下载模型权重并将其转换为lit-gpt格式。使用以下脚本很容易做到这一点:
要执行模型,只需运行以下命令:
使用16位精度
在GPU上训练深度神经网络时,我们通常使用低于最大精度,即32位浮点运算(实际上,PyTorch默认使用32位浮点数)。在浮点表示中,数字以三部分的组合形式存储:符号、指数和有效位数(或尾数)。
一般来说,更大的比特数对应着更高的精度,这降低了计算过程中累积错误的机会。然而,如果我们想要加速我们的模型,我们可以将精度降低到,例如16位精度。这有什么帮助:
1. 减小内存大小。32位精度需要的GPU内存是16位精度的两倍,从而可以更有效地使用GPU内存。
2. 提高计算和速度。由于对低精度张量的操作需要更少的内存,GPU可以更快地处理它们。
Lit-GPT使用Fabric库,它允许我们在几行代码中更改精度。
混合精度训练是一项重要的技术,可以让我们显着提高现代GPU的训练速度。我们不会把所有的参数和操作都转移到16位浮点数上。相反,我们在训练期间在32位和16位操作之间切换,因此,术语“混合”精度。
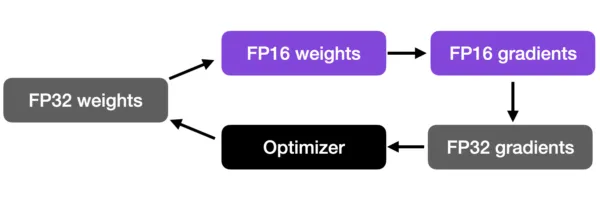
这种方法可以在保持神经网络的准确性和稳定性的同时进行有效的训练。
Bfloat16是Google提出的浮点数格式。这个名字代表“Brain Floating Point Format”,起源于谷歌的 Google Brain人工智能研究小组。
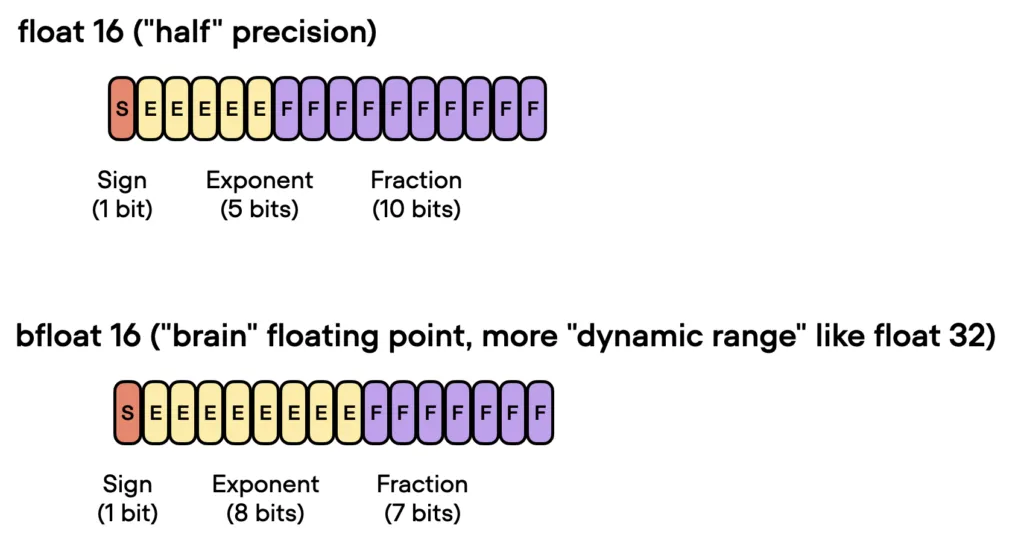
谷歌为机器学习和深度学习应用开发了这种格式,特别是在他们的张量处理单元(TPU)中。虽然bfloat16最初是为TPU开发的,但这种格式现在被几个NVIDIA GPU支持。
你可以通过下面的代码检查你的GPU是否支持bfloat16:
如果支持bfloat,可以执行如下命令:
以上结果总结如下图所示:
如果我们想在推理期间进一步提高模型性能,我们还可以超越较低的浮点精度并使用量化。量化将模型权重从浮点数转换为低位整数表示,例如8位整数(最近甚至是4位整数)。
在深度神经网络上应用量化有两种常见的方法:
1. 训练后量化(PTQ):首先对模型进行训练使其收敛,然后在不进行更多训练的情况下将其权重转换为较低的精度。与培训相比,它的实施通常相当便宜。
2. 量化感知训练(QAT):量化在预训练或进一步微调期间应用。QAT可以表现得更好,但需要额外的计算资源和对代表性训练数据的访问。
由于我们想加快现有模型的速度,我们将使用训练后量化。
由于Falcon模型的4位和8位精度尚未实现,因此我将展示一个使用Lit-LLaMA的LLaMA 7B示例。
虽然微调可能不是加速最终模型推理过程的直接方法,但有一些技巧可以用来优化其性能:
1. 预训练和量化:首先在特定领域问题上预训练模型,然后对其进行量化。量化通常会导致模型质量略有下降,但初始的预训练可以减轻这种情况。
2. 小型适配器:另一种方法涉及针对不同的任务合并小型适配器。适配器通过向现有模型层添加紧凑的附加层并单独训练它们来操作。这些适配器层具有轻量级参数,使模型能够快速适应和学习。
结合使用这些方法,可以提高模型的有效性。
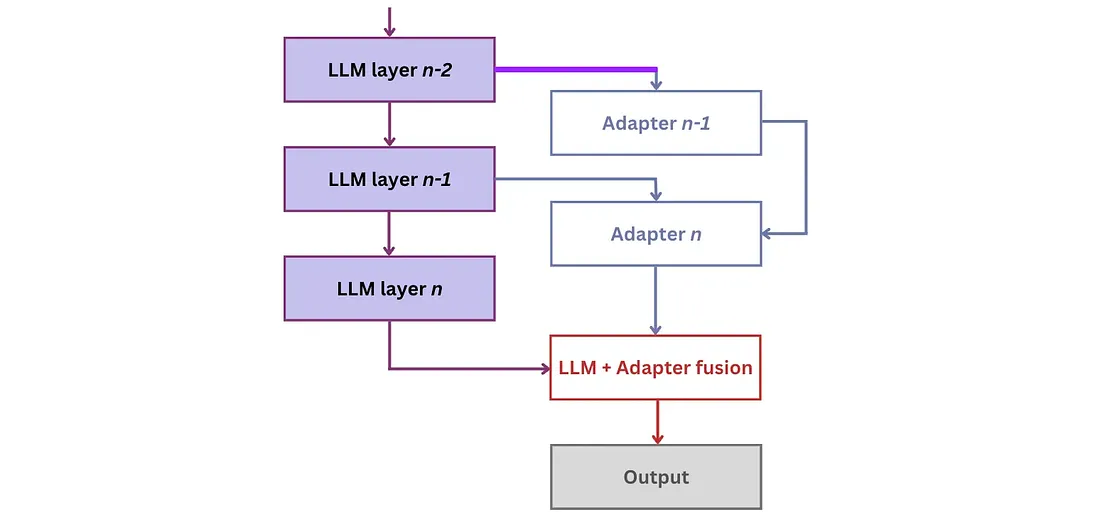
在适配器领域中,出现了几种变体,包括LLaMA-Adapter (v1、v2)、LoRa和QLoRa。其中,低阶适应(Low-Rank Adaptation, LoRA)尤为突出。LoRA将少量可训练参数(称为适配器)引入到LLM的每一层。同时,它冻结所有原始参数。这种方法通过只更新适配器权重来简化微调,从而显著减少内存消耗。
QLoRA方法为LoRA添加了量化和其他一些优化,彻底改变了我们在Google Colab实例上微调模型的方式!
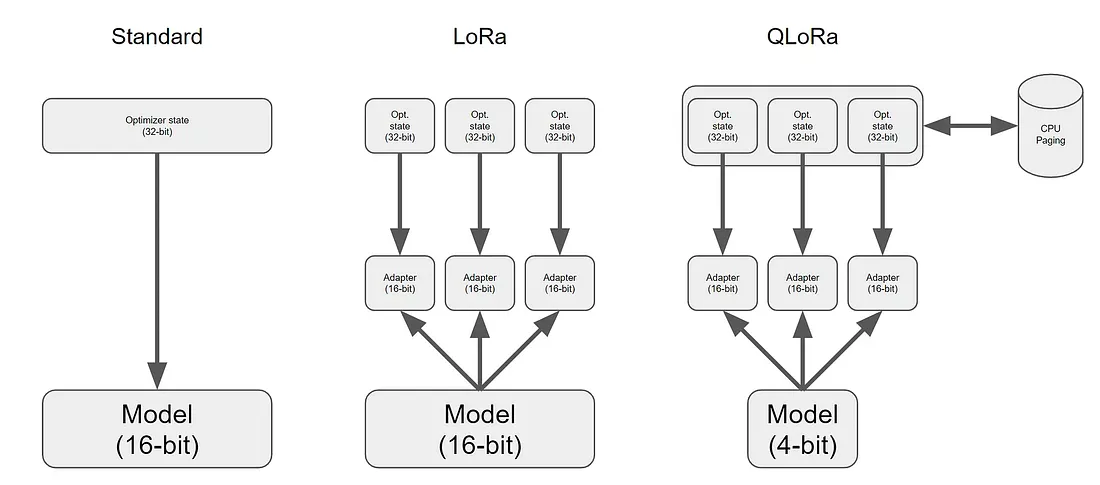
微调LLM可能是资源密集型的,需要大量的时间和计算能力投资。例如,在8个A100 GPU上执行微调Falcon-7B可能需要大约半小时,而在使用单个GPU时大约需要三个小时。此外,最佳结果需要对数据集进行适当的准备。虽然我没有亲自执行模型的微调过程,但如果您希望自己开始,您可以通过运行以下命令启动该过程:
网络修剪通过在保持模型容量的同时修剪不重要的模型权值或连接来减小模型的大小。
新方法LLM- pruner采用基于梯度信息选择性去除非关键耦合结构的结构性剪枝,最大限度地保留LLM的大部分功能。
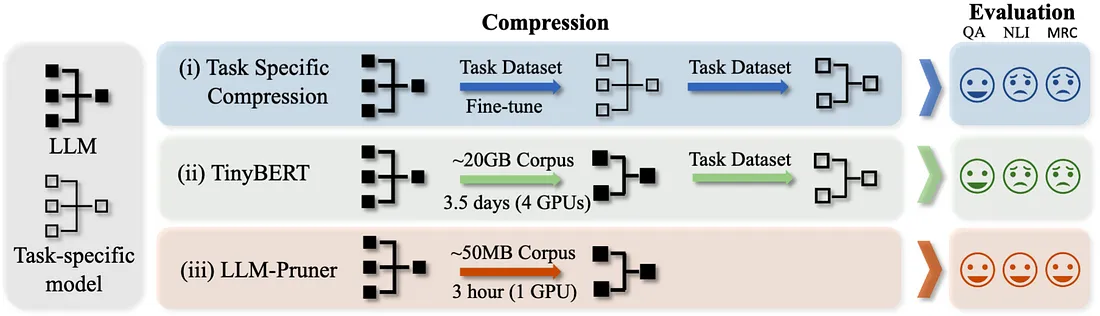
这是另一个有趣的修剪器——Wanda(按权重和激活修剪)。这种方法在每个输出的基础上用最小的值乘以相应的输入激活来修剪权重。
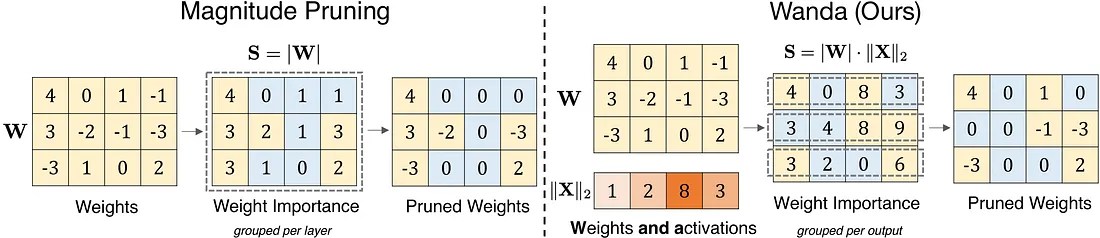
值得注意的是,Wanda不需要再训练和权重更新,修剪后的LLM可以原样使用。同时,它允许我们将LLM人数减少到50%。
GPU以其大规模并行计算架构而闻名,拥有惊人的计算速度,如A100的计算速度为每秒万亿次浮点运算,H100的计算速度甚至达到每秒千万亿次浮点运算。尽管LLM具有巨大的计算能力,但由于加载模型参数消耗了芯片内存带宽的很大一部分,LLM通常难以充分利用其潜力。
减轻这种限制的一种有效方法是批处理。批处理不是为每个输入序列加载新的模型参数,而是允许一次加载参数并利用它们来处理多个输入序列。这种优化策略有效地利用了芯片的内存带宽,从而提高了计算利用率,提高了吞吐量,并提高了LLM推理的成本效益。通过采用批处理技术,LLM的整体性能可以得到显著提高。
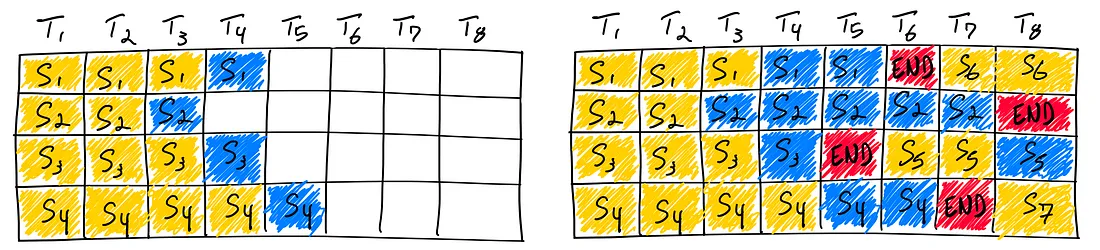
最近提出的一种优化是连续批处理。Orca没有等到批处理中的每个序列都完成生成,而是实现了迭代级调度,其中每次迭代确定批处理大小。结果是,一旦批处理中的序列完成生成,就可以在其位置插入新序列,从而产生比静态批处理更高的GPU利用率。
有多种框架可以使用此算法:
1. 文本生成推理-用于文本生成推理的服务器。
2. 用于LLM的推理和服务引擎。
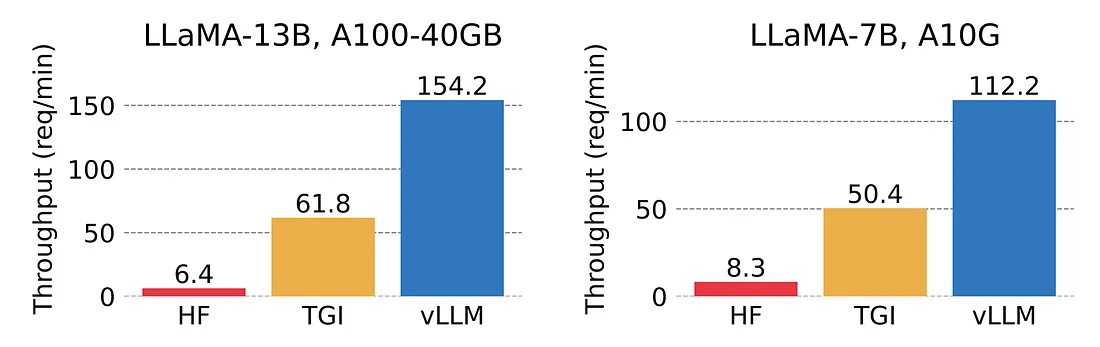
经过仔细的评估,我选择了vLLM作为我的首选。vLLM利用PagedAttention,新的注意力算法,有效地管理注意力键和值:它的吞吐量比 HuggingFace Transformers 高出 24 倍,而不需要任何模型架构的变化。
考虑到在vLLM中无法获得对Falcon的支持,我决定使用LLaMA-7B。
它运转的速度之快,给我留下了深刻的印象。此外,该框架促进了API服务器的无缝设置,从而实现了快速部署。启动该进程,执行如下命令:
然后你可以用下面的代码检查功能:
您还可以使用全分片数据并行(FSDP)分布式策略来利用多个设备来执行推理。重要的是要明白,使用多个GPU设备并不会加快推理速度,但允许您通过将它们分散到多个设备上来运行无法在单个卡上运行的模型。
例如,falcon-40b将需要约80gb的GPU内存才能在单个设备上运行。我们可以在2倍A6000 (48 GB)上运行它,仍然使用lite - gpt,只添加几个参数:
这将占用46 GB内存,并以每秒0.60个令牌的速度运行。

或者,我们可以使用vLLM,只需将tensor_parallel_size设置为2,它就可以更快地生成文本。
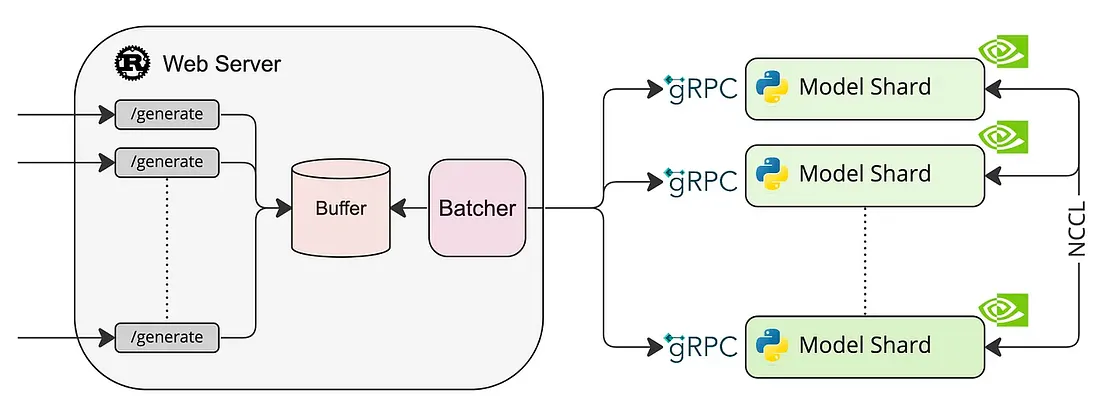
由于vLLM不支持Falcon,所以我决定向您展示如何使用Text Generation Inference轻松部署模型。
为了遵循框架作者推荐的最佳实践,建议执行所提供的命令并在Docker容器中运行应用程序。运行docker容器:
注意:Falcon-7B不支持张量并行。因此,将参数num_shard设置为1以确保正确的功能是至关重要的。
你可以用下面的命令检查API:
LLM推理的其他替代库:
1. Accelerate允许您将部分模型卸载到CPU上。卸载可以帮助您优化推理服务的吞吐量,即使整个模型适合GPU。
2. DeepSpeed Inference可以帮助您更有效地服务基于变压器的模型。
3. DeepSpeed MII是一个库,可以快速设置推理模型的GRPC端点,可选择使用ZeRO-Inference或DeepSpeed inference技术。
4. OpenLLM是一个用于在生产环境中运行大型语言模型(LLM)的开放平台。轻松地微调、服务、部署和监视任何LLM。
5. Aviary——新的开源项目,它简化并支持多个LLM模型的自托管服务.
LLM加速领域是一个复杂的领域,仍处于起步阶段。注意,并不是所有的加速方法都可以不妥协地工作。有些方法可能会降低模型的质量。因此,不经过仔细考虑就盲目地接受和应用所有加速建议是不明智的。你必须保持警惕,控制加速模型的质量。
理想情况下,实现软件优化和模型架构之间的平衡是实现高效LLM加速的关键。
来源:https://betterprogramming.pub/speed-up-llm-inference-83653aa24c47
加速模型推理是开发人员面临的一个重要挑战。这与降低计算资源费用和应用程序响应速度有关。
“在未来,LLM推理每加快1%,其经济价值就相当于 Google 搜索基础设施加速 1%。"——Jim Fan, NVIDIA高级人工智能科学家
简短的总结
这篇文章有点长,所以这里总结一下要点:
1. 使用精度降低:float16或bfloat16。这将使模型的速度提高约20%,并将内存消耗降低2倍。
2. 使用8位或4位量化可以将内存消耗减少2倍或3倍。当在内存有限的小型设备上运行时,这是最好的。注意:量化会降低预测的质量。
3. 使用适配器(LoRA、QLoRA)进行微调,以提高数据的预测准确性。可以很好地与之后的量化相结合。
4. 使用张量并行性在多个GPU上进行更快的推理以运行大型模型。
模型
我选择了Falcon——Technology Innovation Institute发布的最新开源大型语言模型。它是一个只有解码器的自回归模型,有两个变体:70亿参数模型和400亿参数模型。40B模型变体在AWS上的384个GPU上进行了两个月的训练。
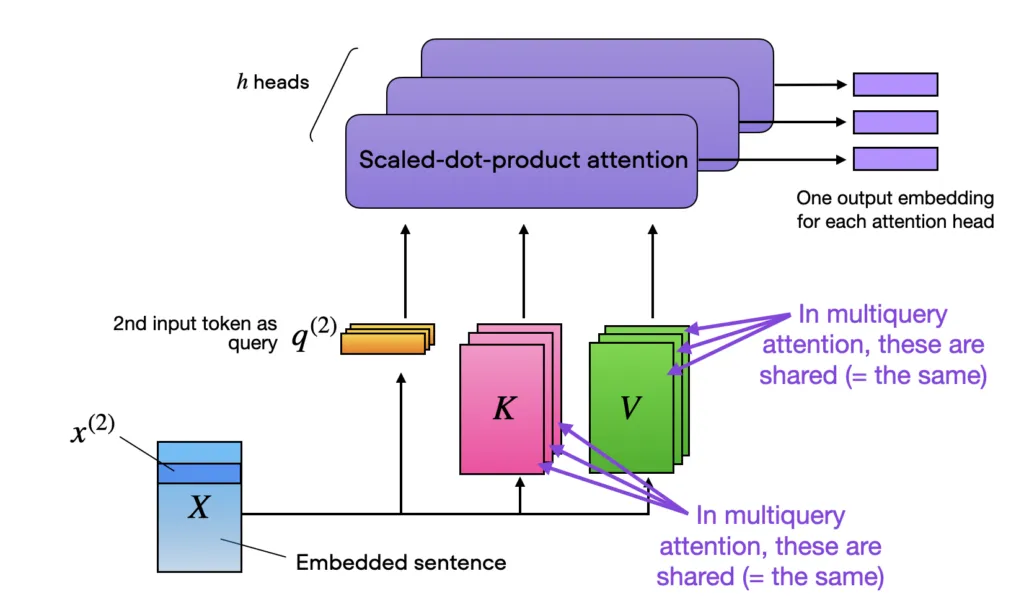
根据对模型的了解,Falcon架构与GPT-3和LLaMA非常相似,除了使用多查询注意力(Shazeer 2019)和RefinedWeb语料库作为训练数据集(这可能是成功的关键)。
多查询注意是一个概念,在不同的注意头之间共享相同的键和值张量以提高效率,如下面的多头注意块所示。
基本用法
为了进行我的实验,我使用了Lit-GPT库,它包括一个开源LLM的实现,并由Lightning Fabric提供支持。至于硬件设置,我使用了单个A100 GPU,内存容量为40GB。
要启动实验,第一步包括下载模型权重并将其转换为lit-gpt格式。使用以下脚本很容易做到这一点:
python scripts/download.py --repo_id tiiuae/falcon-7b
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7b
要执行模型,只需运行以下命令:
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "32-true"
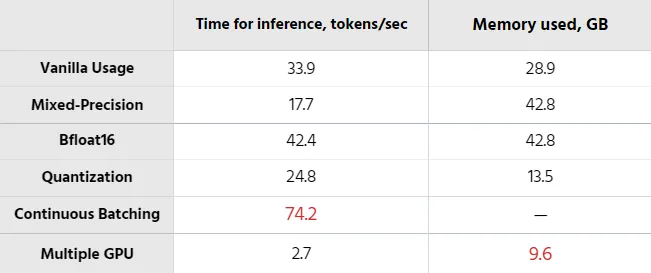
# Time for inference: 1.47 sec total, 33.92 tokens/sec
# Memory used: 28.95 GB
加速LLM推理的方法
使用16位精度
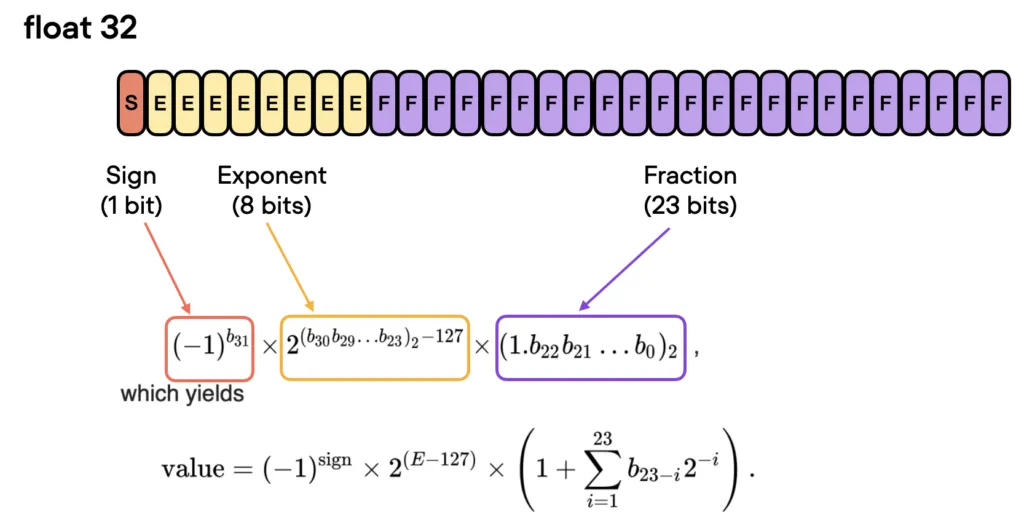
在GPU上训练深度神经网络时,我们通常使用低于最大精度,即32位浮点运算(实际上,PyTorch默认使用32位浮点数)。在浮点表示中,数字以三部分的组合形式存储:符号、指数和有效位数(或尾数)。
一般来说,更大的比特数对应着更高的精度,这降低了计算过程中累积错误的机会。然而,如果我们想要加速我们的模型,我们可以将精度降低到,例如16位精度。这有什么帮助:
1. 减小内存大小。32位精度需要的GPU内存是16位精度的两倍,从而可以更有效地使用GPU内存。
2. 提高计算和速度。由于对低精度张量的操作需要更少的内存,GPU可以更快地处理它们。
Lit-GPT使用Fabric库,它允许我们在几行代码中更改精度。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-true"
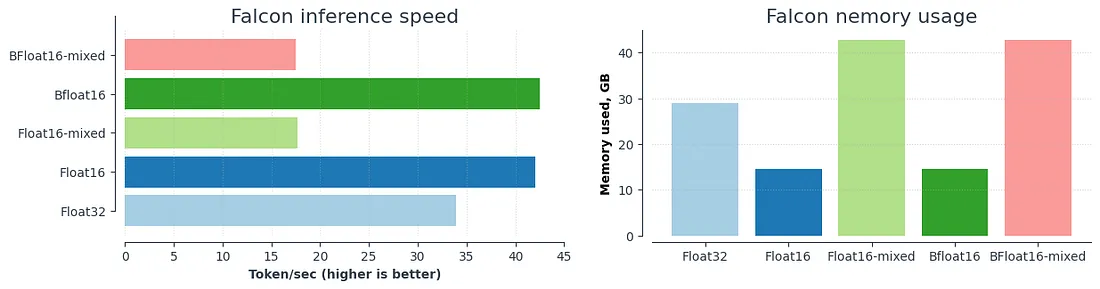
# Time for inference: 1.19 sec total, 42.03 tokens/sec
# Memory used: 14.50 GB
混合精度训练
混合精度训练是一项重要的技术,可以让我们显着提高现代GPU的训练速度。我们不会把所有的参数和操作都转移到16位浮点数上。相反,我们在训练期间在32位和16位操作之间切换,因此,术语“混合”精度。
这种方法可以在保持神经网络的准确性和稳定性的同时进行有效的训练。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-mixed"
# Time for inference 1: 2.82 sec total, 17.70 tokens/sec
# Memory used: 42.84 GB
脑浮点
Bfloat16是Google提出的浮点数格式。这个名字代表“Brain Floating Point Format”,起源于谷歌的 Google Brain人工智能研究小组。
谷歌为机器学习和深度学习应用开发了这种格式,特别是在他们的张量处理单元(TPU)中。虽然bfloat16最初是为TPU开发的,但这种格式现在被几个NVIDIA GPU支持。
你可以通过下面的代码检查你的GPU是否支持bfloat16:
python -c "import torch; print(torch.cuda.is_bf16_supported())"
如果支持bfloat,可以执行如下命令:
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "bf16-true"
# Time for inference: 1.18 sec total, 42.47 tokens/sec
# Memory used: 14.50 GB
以上结果总结如下图所示:
量化
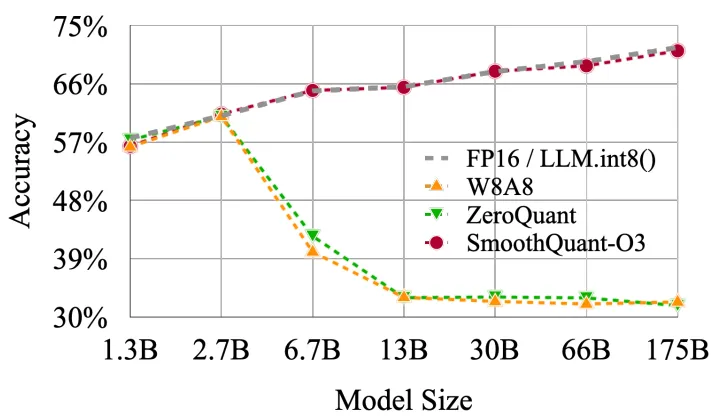
如果我们想在推理期间进一步提高模型性能,我们还可以超越较低的浮点精度并使用量化。量化将模型权重从浮点数转换为低位整数表示,例如8位整数(最近甚至是4位整数)。
在深度神经网络上应用量化有两种常见的方法:
1. 训练后量化(PTQ):首先对模型进行训练使其收敛,然后在不进行更多训练的情况下将其权重转换为较低的精度。与培训相比,它的实施通常相当便宜。
2. 量化感知训练(QAT):量化在预训练或进一步微调期间应用。QAT可以表现得更好,但需要额外的计算资源和对代表性训练数据的访问。
由于我们想加快现有模型的速度,我们将使用训练后量化。
由于Falcon模型的4位和8位精度尚未实现,因此我将展示一个使用Lit-LLaMA的LLaMA 7B示例。
python generate.py \
--prompt "I am so fast that I can" \
--quantize llm.int8
# Time for inference: 2.01 sec total, 24.83 tokens/sec
# Memory used: 13.54 GB
使用适配器进行微调
虽然微调可能不是加速最终模型推理过程的直接方法,但有一些技巧可以用来优化其性能:
1. 预训练和量化:首先在特定领域问题上预训练模型,然后对其进行量化。量化通常会导致模型质量略有下降,但初始的预训练可以减轻这种情况。
2. 小型适配器:另一种方法涉及针对不同的任务合并小型适配器。适配器通过向现有模型层添加紧凑的附加层并单独训练它们来操作。这些适配器层具有轻量级参数,使模型能够快速适应和学习。
结合使用这些方法,可以提高模型的有效性。
在适配器领域中,出现了几种变体,包括LLaMA-Adapter (v1、v2)、LoRa和QLoRa。其中,低阶适应(Low-Rank Adaptation, LoRA)尤为突出。LoRA将少量可训练参数(称为适配器)引入到LLM的每一层。同时,它冻结所有原始参数。这种方法通过只更新适配器权重来简化微调,从而显著减少内存消耗。
QLoRA方法为LoRA添加了量化和其他一些优化,彻底改变了我们在Google Colab实例上微调模型的方式!
微调LLM可能是资源密集型的,需要大量的时间和计算能力投资。例如,在8个A100 GPU上执行微调Falcon-7B可能需要大约半小时,而在使用单个GPU时大约需要三个小时。此外,最佳结果需要对数据集进行适当的准备。虽然我没有亲自执行模型的微调过程,但如果您希望自己开始,您可以通过运行以下命令启动该过程:
python finetune/adapter_v2.py \
--data_dir data/alpaca \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--out_dir out/adapter/alpaca
修剪
网络修剪通过在保持模型容量的同时修剪不重要的模型权值或连接来减小模型的大小。
新方法LLM- pruner采用基于梯度信息选择性去除非关键耦合结构的结构性剪枝,最大限度地保留LLM的大部分功能。
这是另一个有趣的修剪器——Wanda(按权重和激活修剪)。这种方法在每个输出的基础上用最小的值乘以相应的输入激活来修剪权重。
值得注意的是,Wanda不需要再训练和权重更新,修剪后的LLM可以原样使用。同时,它允许我们将LLM人数减少到50%。
批量推理
GPU以其大规模并行计算架构而闻名,拥有惊人的计算速度,如A100的计算速度为每秒万亿次浮点运算,H100的计算速度甚至达到每秒千万亿次浮点运算。尽管LLM具有巨大的计算能力,但由于加载模型参数消耗了芯片内存带宽的很大一部分,LLM通常难以充分利用其潜力。
减轻这种限制的一种有效方法是批处理。批处理不是为每个输入序列加载新的模型参数,而是允许一次加载参数并利用它们来处理多个输入序列。这种优化策略有效地利用了芯片的内存带宽,从而提高了计算利用率,提高了吞吐量,并提高了LLM推理的成本效益。通过采用批处理技术,LLM的整体性能可以得到显著提高。
最近提出的一种优化是连续批处理。Orca没有等到批处理中的每个序列都完成生成,而是实现了迭代级调度,其中每次迭代确定批处理大小。结果是,一旦批处理中的序列完成生成,就可以在其位置插入新序列,从而产生比静态批处理更高的GPU利用率。
有多种框架可以使用此算法:
1. 文本生成推理-用于文本生成推理的服务器。
2. 用于LLM的推理和服务引擎。
经过仔细的评估,我选择了vLLM作为我的首选。vLLM利用PagedAttention,新的注意力算法,有效地管理注意力键和值:它的吞吐量比 HuggingFace Transformers 高出 24 倍,而不需要任何模型架构的变化。
考虑到在vLLM中无法获得对Falcon的支持,我决定使用LLaMA-7B。
from vllm import LLM, SamplingParams
prompts = [
"I am so fast that I can",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="huggyllama/llama-7b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
# I am so fast that I can travel around the world in two hours. My first stop: the Southeast
# The capital of France is one of the most beautiful cities in the world. And it is no secret that
# The future of AI is in a future\nThis might sound like a depressing conclusion, but it
它运转的速度之快,给我留下了深刻的印象。此外,该框架促进了API服务器的无缝设置,从而实现了快速部署。启动该进程,执行如下命令:
python -m vllm.entrypoints.api_server --model huggyllama/llama-7b
然后你可以用下面的代码检查功能:
time curl http://localhost:8000/generate \
-d '{
"prompt": "I am so fast that I can",
"temperature": 0,
"use_beam_search": true,
"n": 4,
}'
# 🚀 real 0m0.277s
# I am so fast that I can take through a story three get back before I started.
# I am so fast that I can turn around a Earth in come back for lunch.
# I am so fast that I can finish on the earth, still be for lunch.\nI am so fast
# I am so fast that I can run around the world and grab my own feet start.
多个GPU设备
您还可以使用全分片数据并行(FSDP)分布式策略来利用多个设备来执行推理。重要的是要明白,使用多个GPU设备并不会加快推理速度,但允许您通过将它们分散到多个设备上来运行无法在单个卡上运行的模型。
例如,falcon-40b将需要约80gb的GPU内存才能在单个设备上运行。我们可以在2倍A6000 (48 GB)上运行它,仍然使用lite - gpt,只添加几个参数:
python generate/base.py \
--checkpoint_dir checkpoints/tiiuae/falcon-40b \
--strategy fsdp \
--devices 2 \
--prompt "I am so fast that I can"
# Time for inference: 83.40 sec total, 0.60 tokens/sec
# Memory used: 46.10 GB
这将占用46 GB内存,并以每秒0.60个令牌的速度运行。
或者,我们可以使用vLLM,只需将tensor_parallel_size设置为2,它就可以更快地生成文本。
prompts = [
"I am so fast that I can",
"The capital of France is",
"The future of AI is",
]
llm = LLM(model="huggyllama/llama-30b", tensor_parallel_size=2)
output = llm.generate(prompts, sampling_params)
# 🚀 It takes only 0.140 seconds!
# I am so fast that I can travel back in time and eat my breakfast before I eat my breakfast!
# The future of AI is up to you.
为 LLM 模特提供服务
由于vLLM不支持Falcon,所以我决定向您展示如何使用Text Generation Inference轻松部署模型。
为了遵循框架作者推荐的最佳实践,建议执行所提供的命令并在Docker容器中运行应用程序。运行docker容器:
docker run --gpus all --shm-size 1g -p 8080:80 \
-v $PWD/data:/data ghcr.io/huggingface/text-generation-inference:0.8 \
--model-id tiiuae/falcon-40b --num-shard 1 --quantize bitsandbytes
注意:Falcon-7B不支持张量并行。因此,将参数num_shard设置为1以确保正确的功能是至关重要的。
你可以用下面的命令检查API:
time curl http://localhost:8080/generate \
-X POST \
-d '{"inputs":"I am so fast that I can","parameters":{"max_new_tokens":50}}' \
-H 'Content-Type: application/json'
# real 0m3.148s
# I am so fast that I can do two things at the same time.
LLM推理的其他替代库:
1. Accelerate允许您将部分模型卸载到CPU上。卸载可以帮助您优化推理服务的吞吐量,即使整个模型适合GPU。
2. DeepSpeed Inference可以帮助您更有效地服务基于变压器的模型。
3. DeepSpeed MII是一个库,可以快速设置推理模型的GRPC端点,可选择使用ZeRO-Inference或DeepSpeed inference技术。
4. OpenLLM是一个用于在生产环境中运行大型语言模型(LLM)的开放平台。轻松地微调、服务、部署和监视任何LLM。
5. Aviary——新的开源项目,它简化并支持多个LLM模型的自托管服务.
结论
LLM加速领域是一个复杂的领域,仍处于起步阶段。注意,并不是所有的加速方法都可以不妥协地工作。有些方法可能会降低模型的质量。因此,不经过仔细考虑就盲目地接受和应用所有加速建议是不明智的。你必须保持警惕,控制加速模型的质量。
理想情况下,实现软件优化和模型架构之间的平衡是实现高效LLM加速的关键。
来源:https://betterprogramming.pub/speed-up-llm-inference-83653aa24c47

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消