











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






优化ChatGPT应用程序:利用Google Drive作为智能知识存储
2023年07月13日 由 Alex 发表
593486
0
介绍
很多文章都是关于使用ChatGPT与PDF文档进行对话的。问题是,大多数人不再把文件放在桌面上了。
创建了一种全新的基于云的工具来处理大量文档。Google Drive、Notion和Dropbox等应用程序成为存储和检索个人和企业使用文档的实际方式。
所以,不要把你的文档带到ChatGPT;相反,使用Google Drive、Notion和Dropbox等应用程序作为知识库,将ChatGPT应用到你的文档中。
你不需要建立一个新的知识库。你只需要使用你已经拥有的知识库。
我们将要建设什么
在本文中,我将向你展示如何使用Google Drive作为ChatGPT应用程序的知识库。
在本文结束时,我们将能够使用ChatGPT与Google Drive中的文档“聊天”。
以下是我们将介绍的内容:
1. 通过Python连接到Google Drive
2. 提取特定文件夹下的所有文档
3. 将文本数据存储在矢量数据库中
4. 使用ChatGPT查询数据
注意:本文假定你具有Python、api、OAuth和矢量数据库的实用知识。
第1步:Google Drive凭证
要连接到Google Drive,你需要必要的凭证。
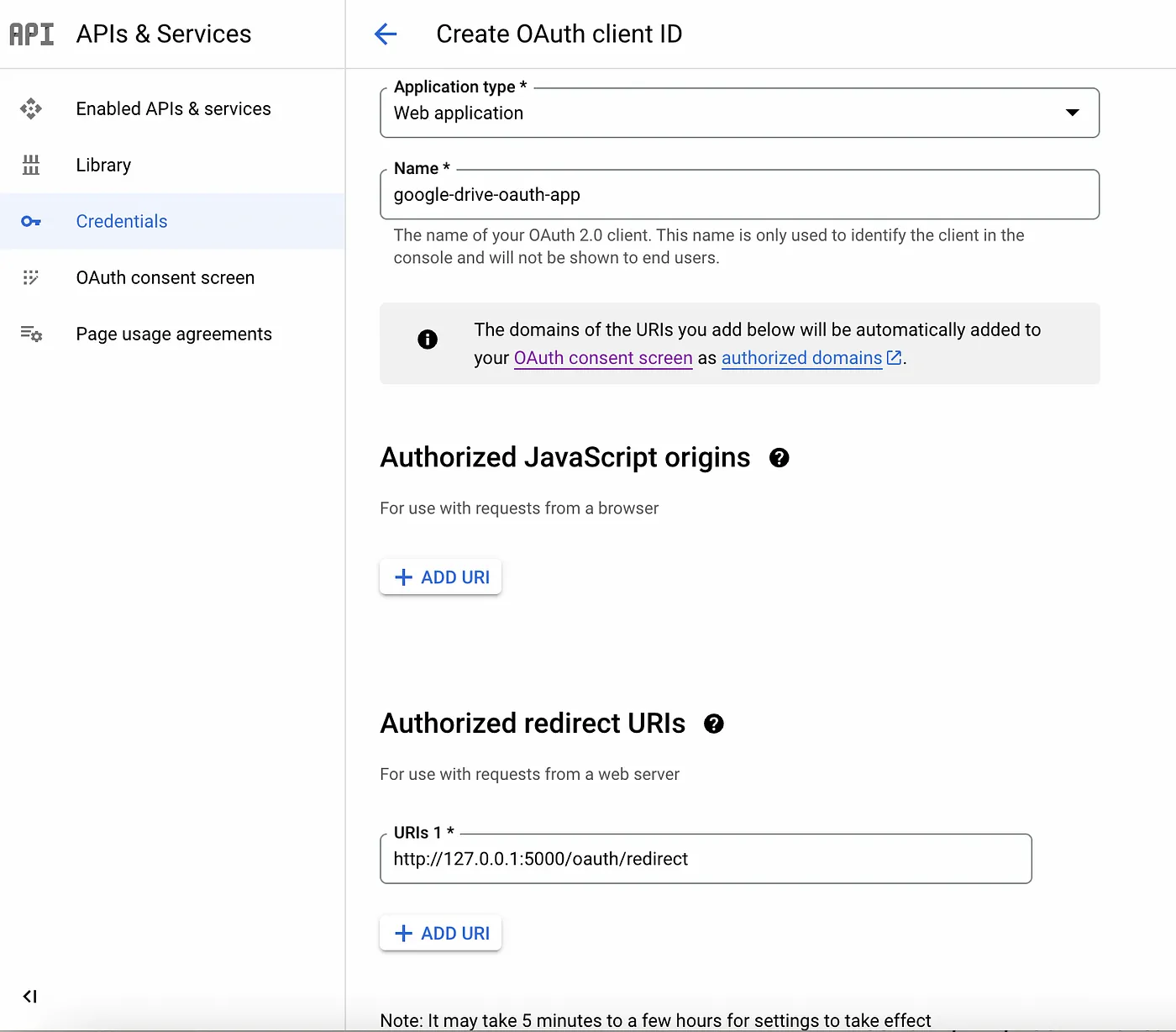
1. 转到https://console.cloud.google.com/apis/credentials并创建一个新的OAuth Client ID凭据
2. 选择Web应用程序作为应用程序类型
3. 给凭据起任何你想要的名字。你不需要为授权JavaScript来源添加任何内容
4. 在“授权重定向URI”下,添加以下URL: http://127.0.0.1:5000/oauth/redirect
5. 单击Create
6. 下载用于下一步的凭据JSON文件
第2步:连接到Google Drive
我们将使用Flask创建一个简单的API,通过Google Drive进行身份验证并加载文档。
这个API将有四个端点:
1. 授权端点
初始化连接到Google Drive的进程
2. 回调端点
验证用户标识并创建凭据
3. 加载数据端点
加载所有的文件从谷歌驱动器到矢量数据库
4. 查询端点
允许我们与文件聊天
安装这些Python包:
pip install Flask
pip install Flask-Cors
pip install google-api-python-client
pip install google-auth
pip install google-auth-httplib2
pip install google-auth-oauthlib
pip install PyPDF2==3.0.1
pip install tiktoken==0.3.3
pip install openai==0.27.0
import json
import io
import webbrowser
from flask import Flask, request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from googleapiclient.discovery import build
from urllib.parse import urlparse
from urllib.parse import parse_qs
from collections import deque
from PyPDF2 import PdfReader
from flask_cors import CORS
SCOPES = ['https://www.googleapis.com/auth/drive']
client_secrets = {"web":{"client_id":"72246653...", "project_id": ...}}
app = Flask(__name__)
CORS(app)
@app.route("/authorize", methods=['GET'])
def authorize_google_drive():
pass
@app.route("/oauth/redirect", methods=['POST', 'GET'])
def redirect_callback():
return "Google Drive Authorization Successful!"
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
pass
@app.route("/query", methods=['POST'])
def query_knowledge_base():
pass
if __name__ == "__main__":
app.run()
为了简化操作,可以将client_secrets变量设置为前面保存的凭证文件中的JSON对象。
让我们从/authorize端点开始:
@app.route("/authorize", methods=['GET'])
def authorize_google_drive():
flow = InstalledAppFlow.from_client_config(
client_secrets,
SCOPES,
redirect_uri="http://127.0.0.1:5000/oauth/redirect"
)
authorization_url, state = flow.authorization_url(prompt='consent')
webbrowser.open(authorization_url)
return authorization_url发生了什么
1. 我们的应用程序正在请求访问Google硬盘内的数据
2. Google正在返回一个URL来选择一个Google帐户,并给予我们的应用程序许可
3. 一旦获得许可,Google将用户重定向回我们的应用程序
下面是访问/authorize端点的方法:
curl http://127.0.0.1:5000/authorize
结果
网页打开后,继续选择你的Google帐户,并允许应用程序访问。
如果一切顺利,你应该看到一个空白屏幕,并显示“Google Drive Authorization Successful!”,在左上角。
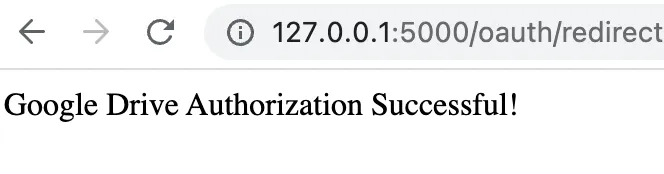
当然,这文字只是一个占位符,并不意味着我们已经连接到Google Drive。
要连接,我们需要定义/oauth/redirect端点。
@app.route("/oauth/redirect", methods=['POST', 'GET'])
def redirect_callback():
authorization_response = request.url
print("authorization response: ", authorization_response)
parsed_url = urlparse(authorization_response)
auth_code = parse_qs(parsed_url.query)['code'][0]
print("auth code: ", auth_code)
flow = InstalledAppFlow.from_client_config(
client_secrets,
SCOPES,
redirect_uri="http://127.0.0.1:5000/oauth/redirect"
)
flow.fetch_token(code=auth_code)
credentials = flow.credentials
credentials_string = credentials.to_json()
with open("gdrive_credentials.txt", "w") as text_file:
text_file.write(credentials_string)
return "Google Drive Authorization Successful!"发生了什么
1. 一旦用户登录到Google帐户,Google就会自动触发Oauth重定向端点
2. 在这个回调中,将发送带有代码的URL作为查询参数
3. 我们从URL中提取代码并获取用户的凭据,这只是一个JSON对象,其中包含令牌和刷新令牌等内容。
4. 我们希望将这些凭证保存在一个文本文件中,以便在将来调用Google Drive端点时重用它们,而无需通过这个授权流程重新进行身份验证。
你应该在工作区中看到一个包含这些凭证的gdrive_credentials.txt文件。
这就是我们连接到Google Drive所需要的。接下来,我们将获取数据。
第3步:从Google Drive中提取文档
为了从Google Drive获取文档,我们将填写/load端点。
首先,我们需要在Google Drive中找到一个文件夹的路径。我们不想让我们的应用访问Google Drive中的所有内容。我们希望限制对特定文件夹及其下所有子文件夹的访问。
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
data = request.json
google_drive_folder_path = data.get('folder_path')
if not google_drive_folder_path:
return {"msg": "A folder path must be provided in order to load google drive documents"}要获取文件夹的路径,导航到你的Google Drive。右键单击文件夹并复制链接。
链接应该是这样的:
https://drive.google.com/drive/folders/1b331p?usp=share_link
接下来,我们将加载在上一步中保存的JSON凭据:
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
data = request.json
google_drive_folder_path = data.get('folder_path')
if not google_drive_folder_path:
return {"msg": "A folder path must be provided in order to load google drive documents"}
with open('gdrive_credentials.txt') as f:
line = f.readline()
credentials_json = json.loads(line)
creds = Credentials.from_authorized_user_info(
credentials_json
)
if not creds.valid and creds.refresh_token:
creds.refresh(Request())
credentials_string = creds.to_json()
with open("gdrive_credentials.txt", "w") as text_file:
text_file.write(credentials_string)发生了什么
1. 首先,我们得到Google Drive文件夹的路径
2. 接下来,加载从上一步保存的JSON凭据
3. 我们验证凭据以确保它们没有过期
让我们调用Google Drive API并获取文档。
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
....
....
....
if not creds.valid and creds.refresh_token:
creds.refresh(Request())
credentials_string = creds.to_json()
with open("gdrive_credentials.txt", "w") as text_file:
text_file.write(credentials_string)
service = build('drive', 'v3', credentials=creds)
folder_id = get_folder_id_from_url(google_drive_folder_path)下面是帮助函数get_folder_id_from_url的代码:
def get_folder_id_from_url(url: str):
url_path = urlparse(url).path
folder_id = url_path.split("/")[-1]
return folder_id
我们不会手动调用Google Drive API。相反,我们将使用Google SDK为我们做这些。build()函数是Google SDK的一部分,它将代表我们正确调用驱动API。
首先,我们从文件夹路径获取文件夹ID。文件夹ID只是foldres/文件夹路径中 后面的随机字符串。
一个例子
如果文件夹路径为:https://drive.google.com/drive/folders/1b331p?usp=share_link
文件夹ID为:1b331p
现在我们有了文件夹ID,我们可以列出该文件夹下Google Drive中的所有文件。
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
....
....
....
service = build('drive', 'v3', credentials=creds)
folder_id = get_folder_id_from_url(google_drive_folder_path)
documents = get_documents_from_folder(service, folder_id)这里,我们将调用一个辅助函数get_documents_from_folder,它将从文件夹中的每个文档中获取所有内容。
def get_documents_from_folder(service, folder_id):
folders_to_process = deque([folder_id])
documents = []
while folders_to_process:
current_folder = folders_to_process.popleft()
items = list_files_in_folder(service, current_folder)
for item in items:
mime_type = item.get("mimeType", "")
if mime_type == "application/vnd.google-apps.folder":
folders_to_process.append(item["id"])
elif mime_type in ["application/vnd.google-apps.document", "application/pdf"]:
# Retrieve the full metadata for the file
file_metadata = service.files().get(fileId=item["id"]).execute()
mime_type = file_metadata.get("mimeType", "")
if mime_type == "application/vnd.google-apps.document":
doc = service.files().export(fileId=item["id"], mimeType="text/plain").execute()
content = doc.decode("utf-8")
elif mime_type == "application/pdf":
pdf_file = download_pdf(service, item["id"])
content = extract_pdf_text(pdf_file)
if len(content) > 0:
documents.append(content)
return documents
发生了什么
1. 我们创建一个队列来保存当前目录中的所有文件和文件夹
2. 当队列不为空时,我们弹出一个对象。如果对象是一个文件,我们提取内容。如果对象是一个目录,我们将所有对象的子对象添加到队列中
3. 如果我们试图提取的文件是PDF,我们需要特殊的工具来提取内容。我们将使用PyPDF2包处理PDF文件
以下是使get_documents_from_folder函数正常工作的所有辅助函数:
def list_files_in_folder(service, folder_id):
query = f"'{folder_id}' in parents"
results = service.files().list(q=query, fields="nextPageToken, files(id, name, mimeType, webViewLink)").execute()
items = results.get("files", [])
return items
def download_pdf(service, file_id):
request = service.files().get_media(fileId=file_id)
file = io.BytesIO(request.execute())
return file
def extract_pdf_text(pdf_file):
reader = PdfReader(pdf_file)
text = ''
for page_num in range(len(reader.pages)):
text += reader.pages[page_num].extract_text()
return text
第4步:上传数据到矢量数据库
这一步你需要一个OpenAI开发者账户,因为我们将使用他们的嵌入式API。
我们还需要一个矢量数据库。
想法是:我们将上传所有的文本从我们的文档到一个矢量数据库。每当用户查询时,我们都会在数据库中找到类似的内容,并将其作为上下文来回答用户的问题。
我将在本文中使用Qdrant,因为它易于设置和使用。
在将数据加载到矢量数据库之前,我们必须将文本分割成大小相等的块。因为我们不想一次上传一个20页的PDF !
将以下导入添加到Python脚本的顶部:
import tiktoken
from qdrant_test import QdrantVectorStore
import openai
openai.api_key = "YOUR-OPENAI-API-KEY"
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
....
....
....
documents = get_documents_from_folder(service, folder_id)
chunks = []
for doc in documents:
document_chunks = chunk_tokens(doc)
chunks.extend(document_chunks)
def chunk_tokens(document: str, token_limit: int = 200):
tokenizer = tiktoken.get_encoding(
"cl100k_base"
)
chunks = []
tokens = tokenizer.encode(document, disallowed_special=())
while tokens:
chunk = tokens[:token_limit]
chunk_text = tokenizer.decode(chunk)
last_punctuation = max(
chunk_text.rfind("."),
chunk_text.rfind("?"),
chunk_text.rfind("!"),
chunk_text.rfind("\n"),
)
if last_punctuation != -1:
chunk_text = chunk_text[: last_punctuation + 1]
cleaned_text = chunk_text.replace("\n", " ").strip()
if cleaned_text and (not cleaned_text.isspace()):
chunks.append(
{"text": cleaned_text}
)
tokens = tokens[len(tokenizer.encode(chunk_text, disallowed_special=())):]
return chunks
chunk_tokens函数在做什么:
1. 标记文本
2. 按令牌限制拆分令牌(你可以将令牌限制视为字数计数)
3. 分割文本,找到最近的标点符号,然后把它分开。
结束时你会得到一个字符串列表,其中包含大小大致相等的文本块。
然后把这些数据上传到矢量数据库了。
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
....
....
....
documents = get_documents_from_folder(service, folder_id)
chunks = []
for doc in documents:
document_chunks = chunk_tokens(doc)
chunks.extend(document_chunks)
vector_store = QdrantVectorStore(collection_name="google-drive-docs")
vector_store.upsert_data(chunks)
return "docs loaded"我们需要稍微修改一下upsert_data函数。
def upsert_data(self, data: List[dict]):
points = []
for item in data:
text = item.get("text")
text_vector = get_embedding(text, engine="text-embedding-ada-002")
text_id = str(uuid.uuid4())
point = PointStruct(id=text_id, vector=text_vector, payload=item)
points.append(point)
operation_info = self.client.upsert(
collection_name=self.collection_name,
wait=True,
points=points)
if operation_info.status == UpdateStatus.COMPLETED:
print("Data inserted successfully!")
else:
print("Failed to insert data")
我们终于完成了/load端点。以下是该函数的完整代码供你参考:
@app.route("/load", methods=['POST'])
def load_docs_from_drive():
data = request.json
google_drive_folder_path = data.get('folder_path')
if not google_drive_folder_path:
return {"msg": "A folder path must be provided in order to load google drive documents"}
with open('gdrive_credentials.txt') as f:
line = f.readline()
credentials_json = json.loads(line)
creds = Credentials.from_authorized_user_info(
credentials_json
)
if not creds.valid and creds.refresh_token:
creds.refresh(Request())
credentials_string = creds.to_json()
with open("gdrive_credentials.txt", "w") as text_file:
text_file.write(credentials_string)
service = build('drive', 'v3', credentials=creds)
folder_id = get_folder_id_from_url(google_drive_folder_path)
documents = get_documents_from_folder(service, folder_id)
chunks = []
for doc in documents:
document_chunks = chunk_tokens(doc)
chunks.extend(document_chunks)
vector_store = QdrantVectorStore(collection_name="google-drive-docs")
vector_store.upsert_data(chunks)
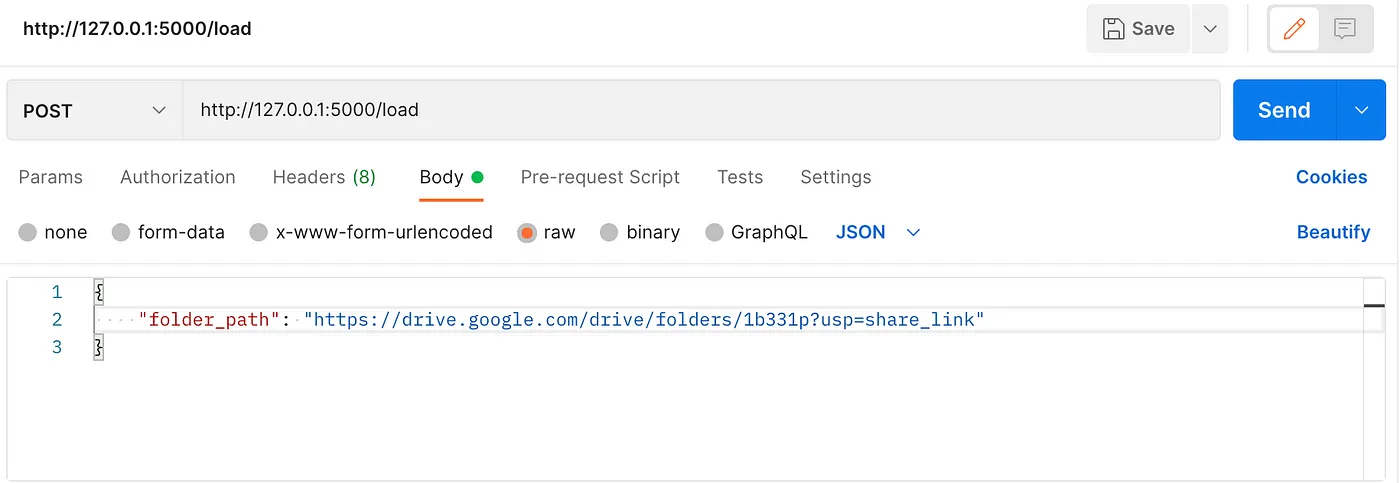
return "docs loaded"点击/load端点,找到你的Google Drive文件夹的路径,上传你的文档。
下面是到达/load端点的curl命令:
curl -X POST 'http://127.0.0.1:5000/load' \
-H 'Content-Type: application/json' \
-d '{"folder_path": "https://drive.google.com/drive/folders/1b331p?usp=share_link"}'
我使用Postman而不是curl来到达端点:
第5步:连接ChatGPT与我们的矢量数据库
这是最后一步!
我们必须创建一个简单的API端点,它接受用户查询,并根据知识库(Google Drive docs)中的信息输出响应。
我们执行向量搜索来查找与查询匹配的文本片段,并只检索这些文本片段。这些文本片段将作为我们的上下文,ChatGPT将使用它们来回答我们的问题。
@app.route("/query", methods=['POST'])
def query_knowledge_base():
data = request.json
query = data.get('query')
vector_store = QdrantVectorStore(collection_name="google-drive-docs")
results = vector_store.search(query)
context = ""
for entry in results:
text = entry.get('text')
context += text
llm_answer = chatgpt_answer(query, context)
print(llm_answer)
return llm_answer同样,我们需要修改Qdrant搜索功能。
def search(self, input_query: str, limit: int = 3):
input_vector = get_embedding(input_query, engine="text-embedding-ada-002")
search_result = self.client.search(
collection_name=self.collection_name,
query_vector=input_vector,
limit=limit
)
result = []
for item in search_result:
similarity_score = item.score
payload = item.payload
data = {"id": item.id, "similarity_score": similarity_score, "text": payload.get("text")}
result.append(data)
return result
一旦我们执行了向量搜索,我们就可以将上下文提供给ChatGPT并得到我们的答案。
def chatgpt_answer(question, context):
prompt = f"""
Use ONLY the context below to answer the question. If you do not know the answer, simply say I don't know.
Context:
{context}
Question: {question}
Answer:"""
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a question answering chatbot"},
{"role": "user", "content": prompt}
]
)
return res['choices'][0]['message']['content']
点击/query端点,对知识库中的某项内容提出问题。
我在我的谷歌驱动器文件夹中有一个与私人API相关的文档,所以这是我的查询:
“摄入API的要求是什么?”
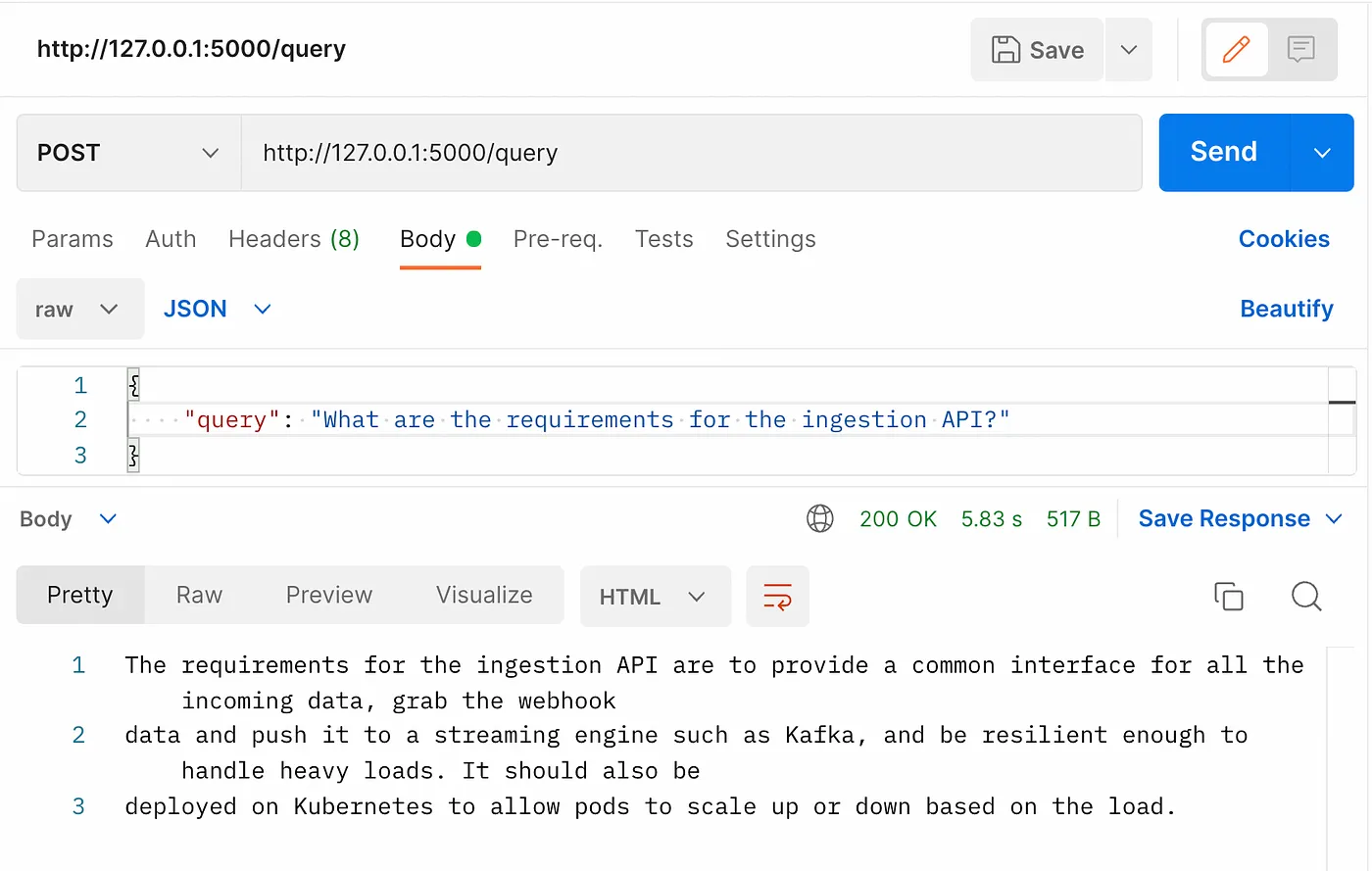
你应该直接从你的Google Drive知识库中得到答案,而不仅仅是ChatGPT随机训练的东西。
总结
这看起来可能需要大量的工作,但这是使用LLM交付实际价值的开始。我相信LLM的真正力量会在你将其与现有应用程序集成时显现出来。
对于企业来说,将LLM与SaaS应用程序连接起来可能是在短期内为客户创造价值的最快方式。我们已经在ChatGPT插件中看到了这一点,但是这些工具非常灵活,你可以构建自己的集成。
在这个例子中,我展示了如何与Google Drive连接。但是想象一下,一个应用程序可以让你连接到Notion、Salesforce、Zendesk、Dropbox、Slack、Gmail、ripple……并使用自然语言与你的数据聊天!
像这样的应用已经存在,而我们仍处于发现这项技术真正潜力的早期阶段。
来源:https://medium.com/better-programming/using-google-drive-as-a-knowledge-base-for-your-chatgpt-application-805962812547

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消