











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






占用网络:通过学习粒子动力学进行4D重建
2020年01月13日 由 KING 发表
796630
0
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2020/01/Occupancy-Flow-4D-Reconstruction-by-Learning-Particle-Dynamics.mp4"][/video]


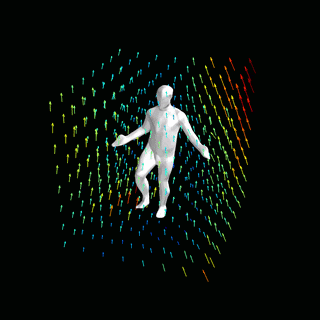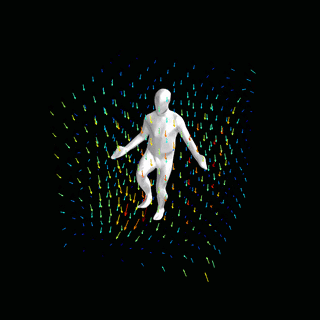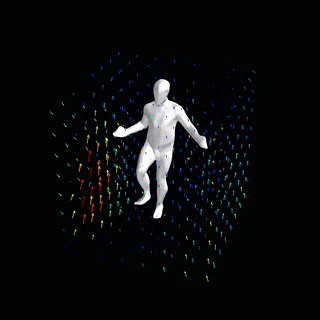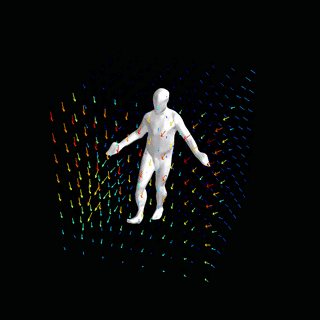


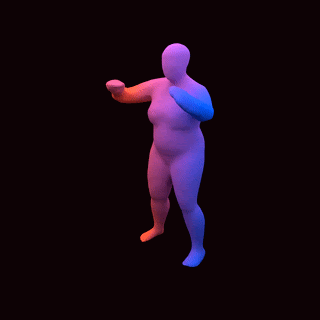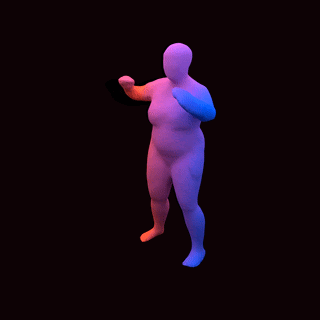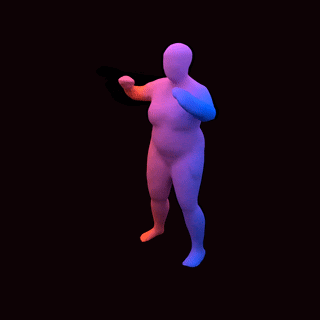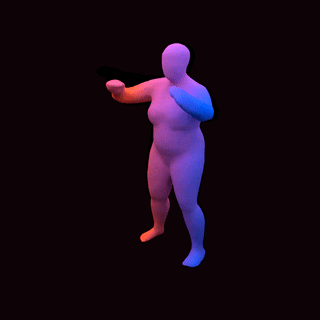
![]()

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
美国的面部识别“危机”








广告


写评论取消
回复取消