Google AI发布“视觉任务适应基准”
2019年11月07日 由 KING 发表
64135
0
深度学习彻底改变了计算机视觉的工作方式,先进的深度学习网络直接从原始数据学习有用的元素,从而在许多视觉任务上达到了空前的高度。但是,从头开始学习这些元素通常需要成千上万的训练样本。虽然可以通过使用预训练的元素来减轻这种负担,但是它们普遍存在一个障碍。例如,对于从图像提取特征的任务,可以有100多个模型可供选择。很难知道哪种方法可以达到最好的表示效果,因为不同的子字段使用不同的评估协议,这些协议并不总是反映新任务的最终性能。为了减少所有视觉任务的数据需求,研究界必须有一个统一的基准,可以据此评估现有和未来的方法。 为了解决这个问题,Google AI发布了““视觉任务适应基准 ”(VTAB,可在GitHub上获得),它是一种基于一个原则的多样化且具有挑战性的基准,可以在域内数据有限的情况下针对看不见的任务达到更好的性能。相对于推动机器学习(ML)其他领域进步的基准,例如用于自然图像分类的ImageNet,用于自然语言处理的GLUE和用于强化学习的Atari,VTAB遵循类似的准则:
为了解决这个问题,Google AI发布了““视觉任务适应基准 ”(VTAB,可在GitHub上获得),它是一种基于一个原则的多样化且具有挑战性的基准,可以在域内数据有限的情况下针对看不见的任务达到更好的性能。相对于推动机器学习(ML)其他领域进步的基准,例如用于自然图像分类的ImageNet,用于自然语言处理的GLUE和用于强化学习的Atari,VTAB遵循类似的准则:
- 对解决方案的最小限制以鼓励创造力;
- 一个焦点上的实际情况;
- 具有挑战性的任务评价的基准。
VTAB是一种评估协议,旨在衡量向通用和有用的视觉元素迈进的标准,由学习算法必须解决的一组评估视觉任务组成。这些算法可能使用预先训练的视觉表示来辅助它们,并且必须仅满足两个要求:
- 不得对下游评估任务中使用的任何数据(标签或输入图像)进行预训练。
- 它们不得包含硬编码的,特定于任务的逻辑。换句话说,必须将评估任务视为测试集。
这些限制条件确保了成功应用于VTAB的解决方案将来能够推广到其它的任务。
[caption id="attachment_46548" align="aligncenter" width="525"]
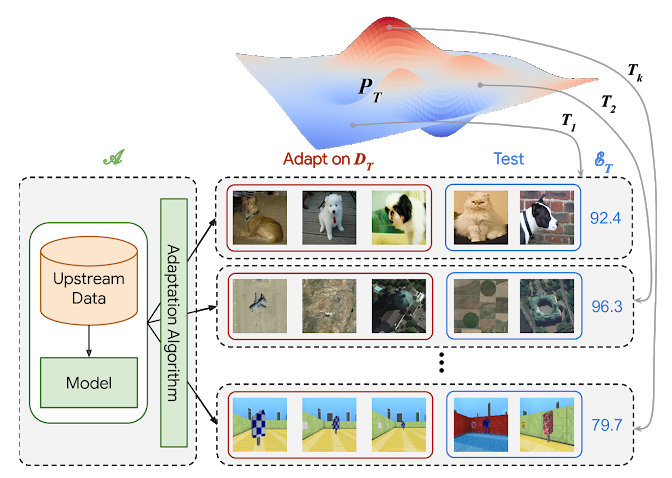
VTAB协议。算法的应用到许多任务T,从视力问题P上广泛分布绘制。在示例中,显示了宠物分类,遥感和迷宫定位。[/caption]
VTAB协议从将算法(A)应用到许多独立的任务开始,这些任务是从视觉问题的广泛分布中得出的。可以在上游数据上对该算法进行预训练,以生成一个包含可视元素的模型,但是它还必须定义一种适应策略,该策略会为每个下游任务消耗少量的训练集,并返回进行特定任务预测的模型。该算法的最终分数是其在各个任务中的平均测试分数。VTAB包括19个评估任务,这些任务跨越多个领域,分为三类: 自然、专业和结构化。自然图像任务包括通过标准相机捕获的自然世界图像,它们代表通用对象,细粒度类或抽象概念。专业任务利用通过专业设备捕获的图像,例如医学图像或遥感图像。结构化的任务通常从人工环境推导出的图像之间的具体变化,例如预测到物体的距离在3D场景(例如,目标理解DeepMind实验),计数对象(例如CLEVR)或检测方向(例如dSprites)。
VTAB中的所有任务虽然种类繁多,但都具有一个共同的功能:人们只需训练几个样本,就可以相对轻松地解决它们。为了评估对数据有限的新任务的算法概括,每个任务仅使用1000个示例来评估性能。
Google的研究人员进行了一项大规模研究,测试了针对VTAB的多种流行的视觉表示学习算法。该研究包括生成模型(GAN和VAE),自我监督模型,半监督模型和监督模型。所有算法都在ImageNet数据集上进行了预训练。我们还比较了未使用预训练表示(即“从头开始”训练)的每种方法。下图总结了结果的主要模式。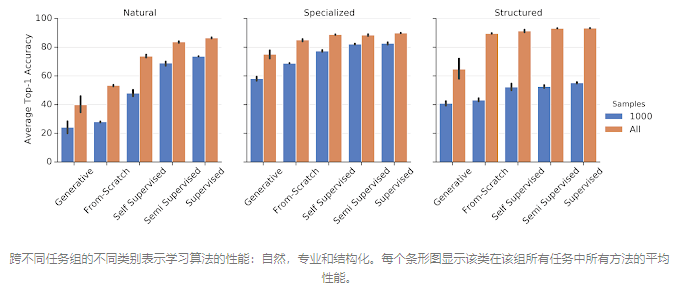
总的来说,我们发现生成模型的性能不如其他方法,甚至比从头训练更差。但是,自我监督模型的性能要好得多,明显优于从零开始的训练。更好的是使用ImageNet标签进行有监督的学习。有趣的是,尽管在自然任务组上监督学习要好得多,但在其他两个领域的自我监督学习却很接近,而这两个领域的范围与ImageNet更为不同。
[caption id="attachment_46550" align="aligncenter" width="424"]
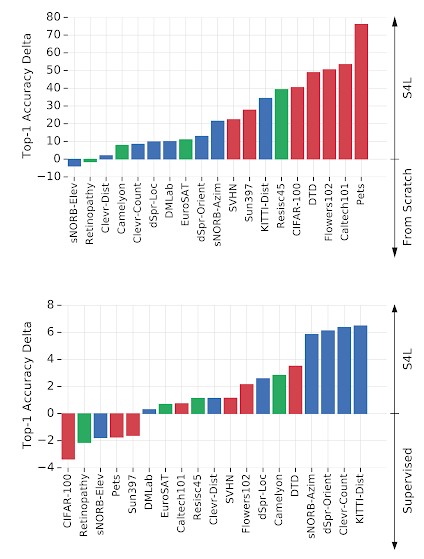
页首: S4L的性能与从头开始的培训。每个栏对应一个任务。正值条形表示S4L从零开始表现出色的任务。负条表示从头开始执行效果更好。下: S4L与ImageNet上的监督培训。正条表示S4L性能更好。条形颜色表示任务组:红色=自然,绿色=专业,蓝色=结构。我们可以看到,除了使用ImageNet标签之外,附加的自我监督还有助于结构化任务。[/caption]
在我们测试的算法中,表现最好的表示学习算法是S4L,它结合了监督和自我监督的预训练损失。下图将S4L与标准监督的ImageNet预训练进行了对比。S4L似乎可以改善性能,尤其是在结构化任务。但是,与自然任务以外的从零开始的训练相比,表示学习的收益要小得多,这表明要实现通用的视觉表示,还需要很大的进步。
运行VTAB的代码在GitHub上可用,包括19个评估数据集和精确的数据拆分。拥有一组公开可用的基准可以确保结果的可重复性。使用公共排行榜跟踪进度,将评估的模型上载到TF Hub以供开发者使用和复制。提供了一个Shell脚本来执行所有任务的调整和评估,并具有标准化的评估协议,从而使VTAB易于在整个行业中访问。由于VTAB可以在TPU和GPU上执行,因此非常高效。只需几个小时,便可以使用单个NVIDIA Tesla P100加速器获得可比的结果。
视觉任务适应基准已经帮助我们更好地理解了哪些视觉表示可以广泛适用于广泛的视觉任务,并为将来的研究提供了方向。我们希望这些资源有助于推动通用和实用的视觉表示方法的发展,从而通过有限的标记数据为视觉问题提供深度学习。
GitHub链接: https://github.com/google-research/task_adaptation





























