











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






英伟达等研究人员开发新方法STEAL,使神经网络具有更精确的计算机视觉
2019年06月18日 由 马什么梅 发表
901112
0
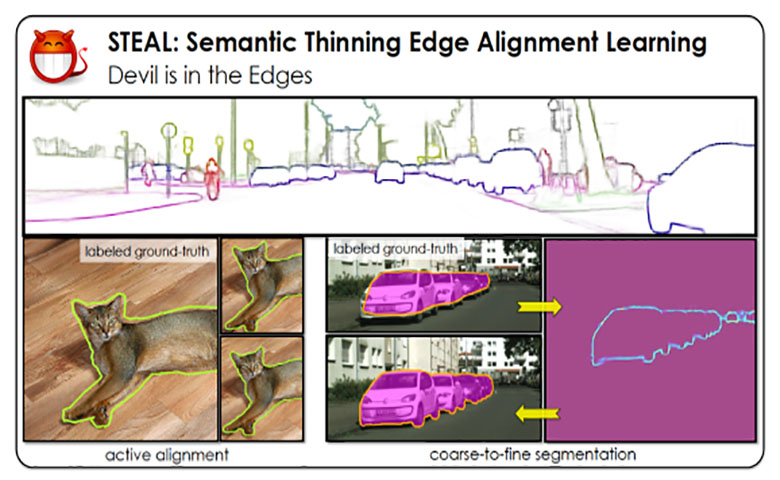 Nvidia,多伦多大学和Vector人工智能研究所的研究人员设计了一种方法,更精确地检测和预测物体开始和结束位置。这些知识可以改进对现有计算机视觉模型的推理,并为未来的模型标记训练数据。
Nvidia,多伦多大学和Vector人工智能研究所的研究人员设计了一种方法,更精确地检测和预测物体开始和结束位置。这些知识可以改进对现有计算机视觉模型的推理,并为未来的模型标记训练数据。在研究人员的实验中,语义细化边缘对齐学习(STEAL)能够将最先进的CASENet语义边界预测模型的精度提高4%。更精确地识别物体的边界可以应用于计算机视觉任务,包括图像生成,三维重建,目标检测。
STEAL可用于改进现有的CNN或边界检测模型,但研究人员还认为它可以更有效地标记或注释计算机视觉模型的数据。
为证明这一点,STEAL方法用于改进城市景观,这是2016年在计算机视觉和模式识别(CVPR)会议上首次引入的城市环境数据集。
现在,在GitHub上,STEAL框架以“主动对齐”的方法来学习和预测像素中的对象边缘。在训练期间对注释噪声进行显式推理,并为网络设置水平集,以便最终从错位标签中学习,也有助于产生结果。
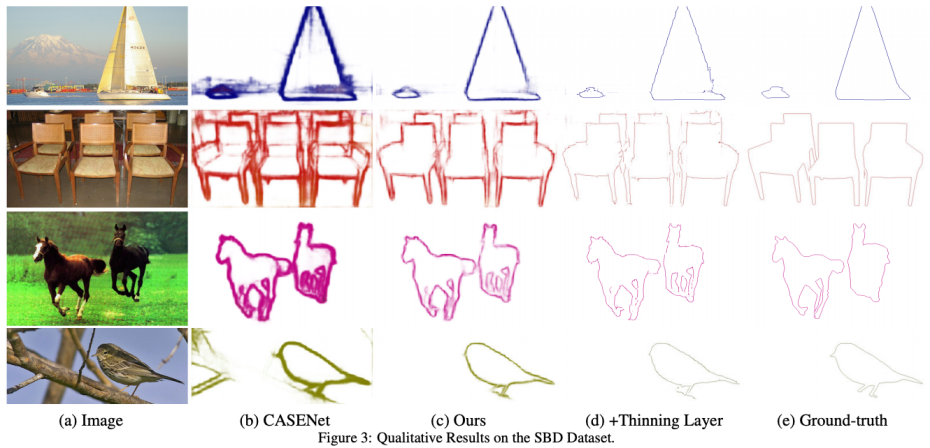 论文中写道,“我们进一步表明,我们预测的边界明显优于最新的DeepLab-v3分割输出,同时使用更轻量级的架构。”
论文中写道,“我们进一步表明,我们预测的边界明显优于最新的DeepLab-v3分割输出,同时使用更轻量级的架构。”“我们解决了语义边界预测问题,其目的是识别属于对象边界的像素。我们注意到,相关数据集包含大量的标签噪声,反映了这样一个事实:获得精确的注释非常困难,因此注释器需要权衡质量和效率。”
团队目标是通过在训练过程中对注释噪声进行显式推理来学习清晰而精确的语义边界。他们提出了一个简单的新层和损耗,可用于现有的基于学习的边界检测器。
在训练期间使用水平集公式进一步推理真实对象边界,这允许网络以端到端的方式从错位标签中学习。实验表明,就MF(ODS)而言,结果优于目前所有最先进的方法,包括那些处理对齐的方法。此外,学习网络可以显著提高粗分割标签,使其成为标记新数据的有效方式。
论文:
arxiv.org/abs/1904.07934
Github:
github.com/nv-tlabs/STEAL

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消