











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






MIT研究:看到即知晓触感,凭触觉想象物体,让机器人识别物体更容易
2019年06月18日 由 张江 发表
441554
0
 先有触觉,后有言语。它是最初的语言,也是最后的语言,它总是讲真话。虽然触觉给了我们一个感受物理世界的通道,但眼睛帮助我们立即理解这些触觉信号的全貌。
先有触觉,后有言语。它是最初的语言,也是最后的语言,它总是讲真话。虽然触觉给了我们一个感受物理世界的通道,但眼睛帮助我们立即理解这些触觉信号的全貌。被编程为看到或感觉到的机器人使用这些信号时不能互换。为了更好地弥合这种感觉差距,CSAIL的研究人员提出了一种预测性AI,可以通过触摸了解看到的,并通过视觉了解触感。
团队的系统可以从视觉输入创建逼真的触觉信号,并直接从那些触觉输入预测哪个对象和哪个部分被触摸。他们使用KUKA机器人手臂和一个名为GelSight的特殊触觉传感器。
该团队使用简单的网络摄像头记录了近200件物品,如工具,家用产品,织物等,触摸次数超过12000次。将这12000个视频片段分解为静态帧,该团队编制了“VisGel”,这是一个包含300多万个视觉和触觉配对图像的数据集。
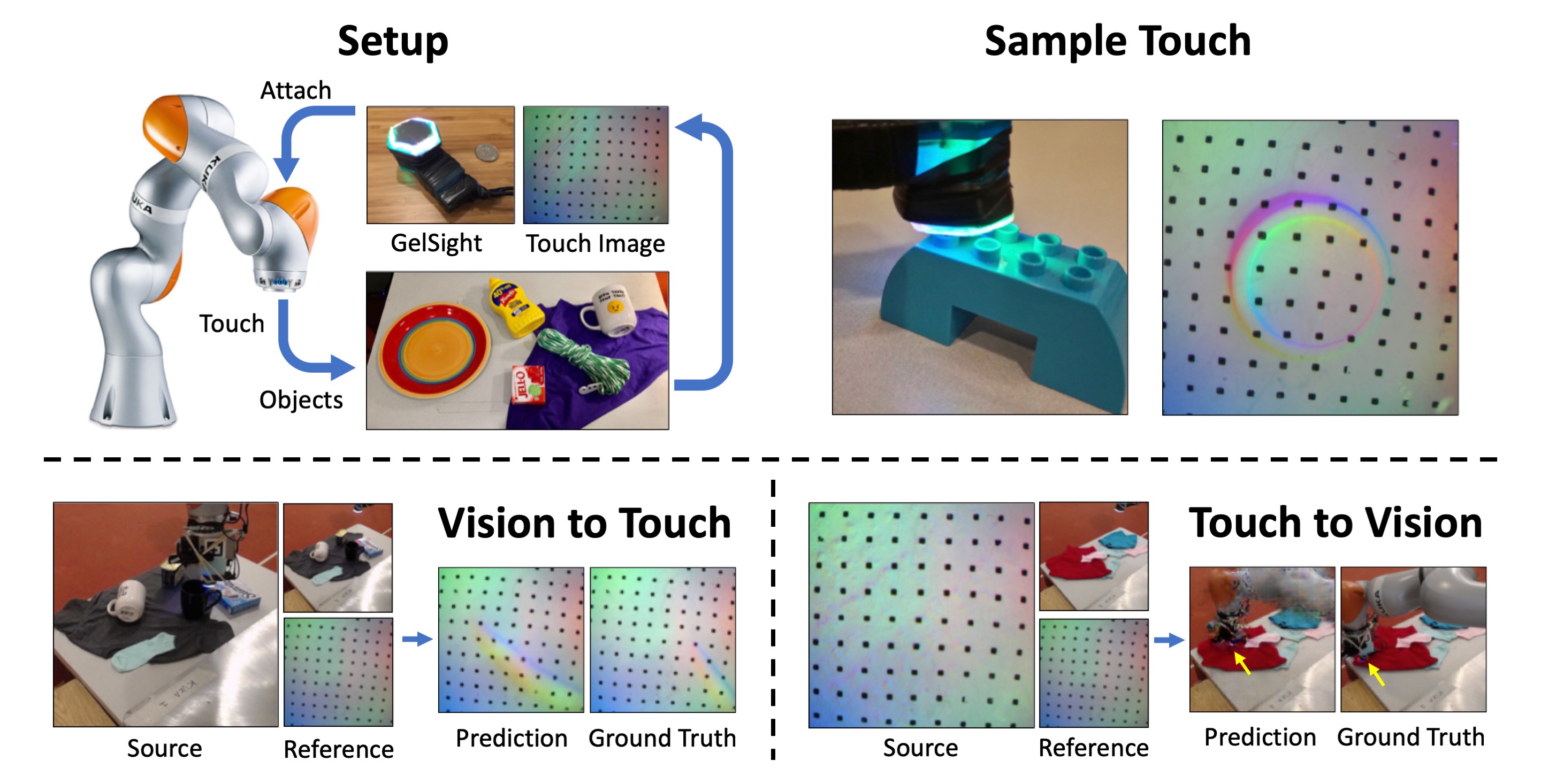 “通过观察现场,我们的模型可以想象触摸平坦表面或锋利边缘的感觉”,主要作者Yunzhu Li在论文中说。“通过盲目地触摸,我们的模型可以纯粹从触觉中预测与环境的相互作用。将这两种感官结合在一起,可以增强机器人的能力并减少我们在涉及操纵和抓取物体的任务时可能需要的数据。“
“通过观察现场,我们的模型可以想象触摸平坦表面或锋利边缘的感觉”,主要作者Yunzhu Li在论文中说。“通过盲目地触摸,我们的模型可以纯粹从触觉中预测与环境的相互作用。将这两种感官结合在一起,可以增强机器人的能力并减少我们在涉及操纵和抓取物体的任务时可能需要的数据。“团队的技术通过使用VisGel数据集以及GAN来解决这个问题。
由视觉到触觉
人类可以通过观察物体来推断触摸物体的感受。为了更好地为机器提供这种能力,系统首先必须定位触摸的位置,然后推断出有关该区域的形状和感觉的信息。
 没有任何机器人与物体交互的参考图像帮助系统对物体和环境的细节进行编码。然后,当机器人手臂工作时,模型可以简单地将当前帧与其参考图像进行比较,识别出触摸的位置和尺度。
没有任何机器人与物体交互的参考图像帮助系统对物体和环境的细节进行编码。然后,当机器人手臂工作时,模型可以简单地将当前帧与其参考图像进行比较,识别出触摸的位置和尺度。这看起来就像给系统输入电脑鼠标的图像,然后看到模型预测的物体应该被触摸的区域,以便拾取,这将极大地帮助机器计划更安全、更有效的行动。
由触觉到视觉
对于触觉到视觉,模型的目标是基于触觉数据产生视觉图像。该模型分析了一个触觉图像,然后计算出接触位置的形状和材料。然后回顾参考图像,产生互动的视觉。
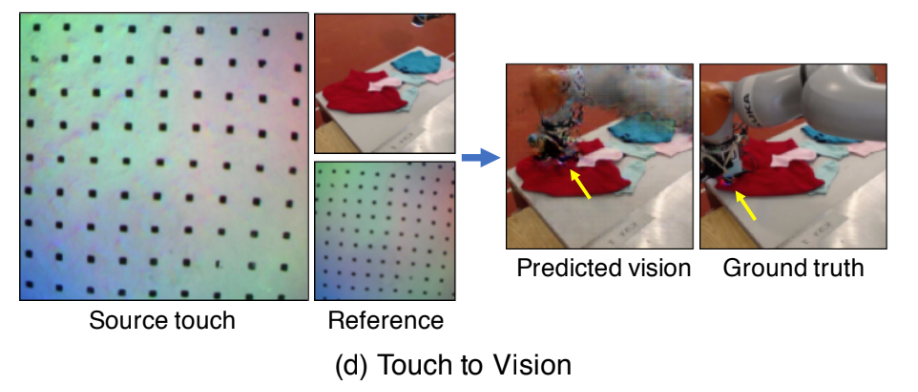 例如,如果在测试过程中给模型输入鞋子的触觉数据,它就能生成鞋子最可能被触碰的位置的图像。
例如,如果在测试过程中给模型输入鞋子的触觉数据,它就能生成鞋子最可能被触碰的位置的图像。在没有视觉数据的情况下,比如比如光线不足或工人在对容器内容不知情的情况下需要把手伸进去时,这种能力可以帮助完成任务。
展望未来
当前数据集仅包含受控环境中的交互示例。该团队希望通过在更多非结构化区域收集数据,或使用新的麻省理工学院设计的触觉手套来改善这一点,从而更好地增加数据集的大小和多样性。
还有一些细节是很难从切换模式中推断出来的,比如仅仅通过触摸就能知道一个物体的颜色,或者不用实际按压就能知道沙发有多软。研究人员表示,这可以通过创建更健壮的不确定性模型来改善,从而扩大可能结果的分布。
在未来,这种类型的模型可以帮助实现视觉和机器人之间更加和谐的关系,特别是对象识别,抓取,更好的场景理解,以及帮助在辅助或制造环境中进行无缝的人机集成。
像这样的方法有可能对机器人非常有用,你需要回答的问题是这个物体是硬的还是软的?或者,如果我提起这个杯子的把手,我的握力会有多好?这是一个非常具有挑战性的问题,因为信号是如此不同,所以这个模型具有巨大的潜力。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消