











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在Keras中展示深度学习模式的训练历史记录
2017年07月29日 由 yuxiangyu 发表
921509
0
通过观察神经网络和深度学习模型在训练期间的表现,你可以得知很多有用的信息。
Keras是Python中强大的库,为创建深度学习模型提供了一个简单的接口,并包装了更为技术性的TensorFlow和Theano后端。
在这篇文章中,你将发现在训练时如何使用Python中的Keras对深入学习模型的性能进行评估和可视化。
让我们开始吧。
Keras提供了在训练深度学习模型时记录回调的功能。
训练所有深度学习模型时都会使用历史记录回调,这种回调函数被记为系统默认的回调函数。它记录每个时期的训练权重,包括损失和准确性(用于分类问题中)。
历史对象从调用fit()函数返回来训练模型。权重存储在返回的对象的历史词典中。
例如,你可以在训练模型后,使用以下代码段列出历史记录对象中收集的指标:
例如,对于使用验证数据集对分类问题进行训练的模型,可能会产生:
我们可以使用历史对象中收集的数据来绘制平面图。
这些图可以提供对模型训练有帮助的信息,如:
或者更多。
我们可以用收集的历史数据创建图。
在下面的例子中,我们创建了一个小型网络来建模Pima印第安人糖尿病二分类问题。这是一个可从UCI机器学习存储库获取的小型数据集。你可以下载数据集并将其保存到当前工作目录中,文件名为:pima-indians-diabetes.csv。
该示例收集了从训练模型返回的历史记录,并创建了两个图表:
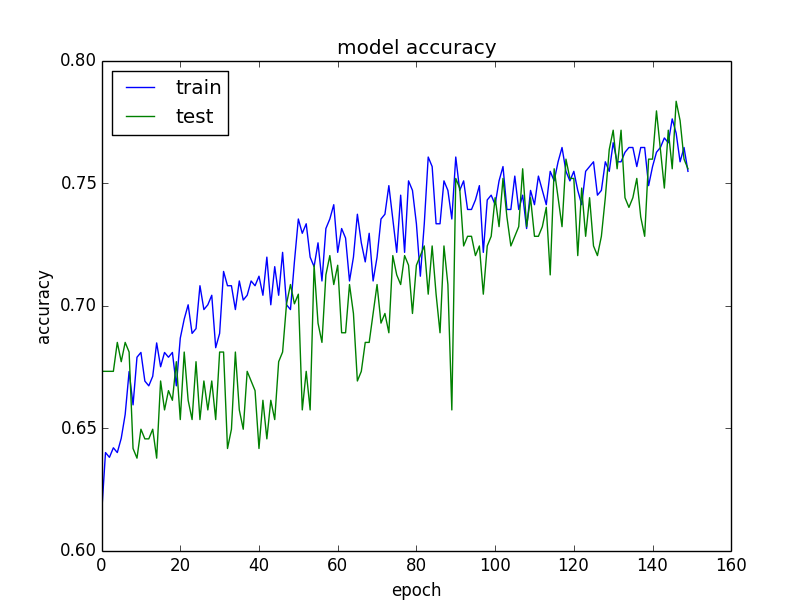
如下图所示,验证数据集的历史被标记为test,因为它实际上是模型的一个测试数据集。
从图中可以看出,模型可以受到更多的训练,两个数据集的准确性趋势在最后几个周期仍然在上升。我们还可以看到,该模型尚未过度学习训练数据集,两种数据集显示出相似的模型技巧。
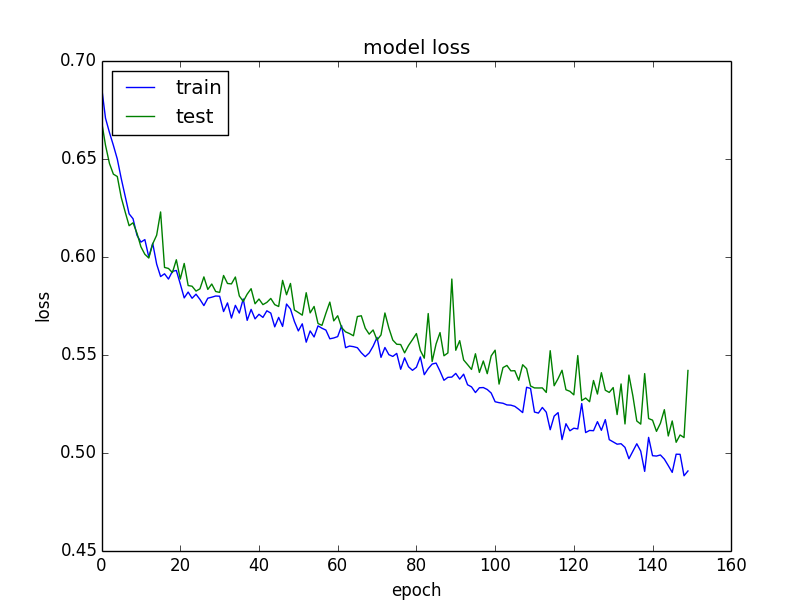
从下面损失图中,我们可以看到该模型在训练和验证数据集(test)上都具有类似的性能。如果图中后面线开始平行,这可能意味着过早的停止了训练。
在这篇文章中,你发现在深入学习模式的训练期间收集和评估权重的重要性。
你了解了Keras中的历史记录回调,以及如何调用fit()函数来训练你的模型。以及学习了如何用训练期间收集的历史数据绘图。
原文:http://machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/
Keras是Python中强大的库,为创建深度学习模型提供了一个简单的接口,并包装了更为技术性的TensorFlow和Theano后端。
在这篇文章中,你将发现在训练时如何使用Python中的Keras对深入学习模型的性能进行评估和可视化。
让我们开始吧。
- 更新2017/03:更新Keras 2.0.2,TensorFlow 1.0.1,Theano 0.9.0的示例。

照片版权:Gordon Robertson
在Keras中访问模型训练的历史记录
Keras提供了在训练深度学习模型时记录回调的功能。
训练所有深度学习模型时都会使用历史记录回调,这种回调函数被记为系统默认的回调函数。它记录每个时期的训练权重,包括损失和准确性(用于分类问题中)。
历史对象从调用fit()函数返回来训练模型。权重存储在返回的对象的历史词典中。
例如,你可以在训练模型后,使用以下代码段列出历史记录对象中收集的指标:
# list all data in history
print(history.history.keys())
例如,对于使用验证数据集对分类问题进行训练的模型,可能会产生:
['acc', 'loss', 'val_acc', 'val_loss']
我们可以使用历史对象中收集的数据来绘制平面图。
这些图可以提供对模型训练有帮助的信息,如:
- 它的收敛速度。(斜度)
- 模型是否已经收敛(线的高度)。
- 模式是否过度学习训练数据验证线的拐点(验证线的变化)。
或者更多。
可视化Keras的模型训练历史
我们可以用收集的历史数据创建图。
在下面的例子中,我们创建了一个小型网络来建模Pima印第安人糖尿病二分类问题。这是一个可从UCI机器学习存储库获取的小型数据集。你可以下载数据集并将其保存到当前工作目录中,文件名为:pima-indians-diabetes.csv。
该示例收集了从训练模型返回的历史记录,并创建了两个图表:
- 训练和验证数据集在训练周期的准确性图。
- 训练和验证数据集在训练周期的损失图。
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
如下图所示,验证数据集的历史被标记为test,因为它实际上是模型的一个测试数据集。
从图中可以看出,模型可以受到更多的训练,两个数据集的准确性趋势在最后几个周期仍然在上升。我们还可以看到,该模型尚未过度学习训练数据集,两种数据集显示出相似的模型技巧。
从下面损失图中,我们可以看到该模型在训练和验证数据集(test)上都具有类似的性能。如果图中后面线开始平行,这可能意味着过早的停止了训练。
总结
在这篇文章中,你发现在深入学习模式的训练期间收集和评估权重的重要性。
你了解了Keras中的历史记录回调,以及如何调用fit()函数来训练你的模型。以及学习了如何用训练期间收集的历史数据绘图。
原文:http://machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消