











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌云重大更新:Text-to-Speech现已支持26种WaveNet语音
2018年08月29日 由 浅浅 发表
741349
0

如果你是谷歌云客户,并且正在使用该公司的AI套件来进行文字转语音或语音转文本服务,这有个好消息:谷歌今天宣布了这些方面的重大更新,包括云文本到语音的普遍可用性,优化声音以便在不同设备上播放的新音频配置文件,多声道识别的增强功能等等。
首先在列表中:改进了谷歌的云文本到语音转换中的语音合成。从本周开始,它将提供多语言访问使用WaveNet生成的语音,WaveNet是Alphabet子公司DeepMind开发的机器学习技术。它会通过识别音调模式模仿语音中的重音和语调(语言学中称为韵律)。除了比以前的型号产生更有说服力的语音片段之外,它还更高效——在Google的云TPU硬件上运行,WaveNet可以在50毫秒内生成一秒钟的样本。
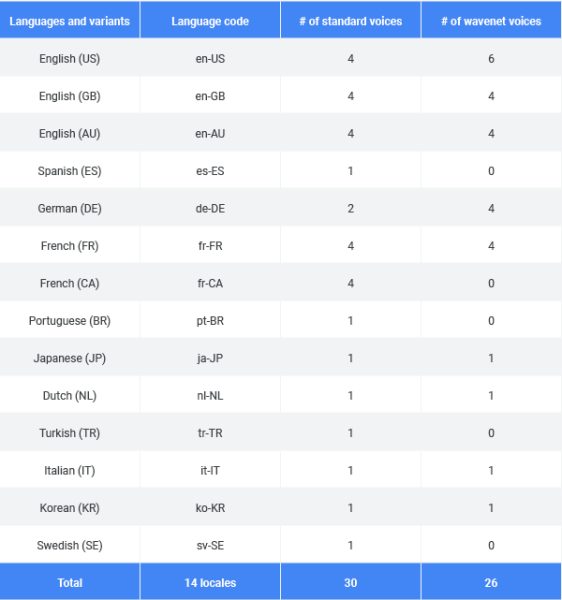
Cloud Text-to-Speech现在提供17种新的WaveNet语音,并支持14种语言和变体。总共有56种声音:30种标准声音和26种WaveNet语音(获取完整列表:cloud.google.com/text-to-speech/docs/voices)。
扩展的WaveNet支持并不是Cloud Text-to-Speech客户唯一的新功能。以前在测试版中提供的音频配置文件正在推出。
简而言之,音频配置文件可让您优化Cloud Text-to-Speech的API生成的语音,以便在不同类型的硬件上播放。例如,你可以为具有较小扬声器的可穿戴设备创建配置文件,或者专门为汽车扬声器和耳机创建配置文件。对于不支持特定频率的设备,它特别方便;Cloud Text-to-Speech可以自动将超出范围的音频移至听觉范围内,从而提高其清晰度。

云文本到语音的音频配置文件在实践中是如何工作的
Google Cloud团队表示,“每个设备的物理特性以及它们所处的环境都会影响它们产生的频率范围和细节水平(例如,低音,高音和音量),音频样本(由音频配置文件产生)实际上可能听起来比笔记本电脑扬声器上的原始样本更糟糕,但用电话线听起来会更好。”
启动时支持八个设备配置文件:
- 可穿戴设备(例如可穿戴OS设备)
- 听筒
- 头戴耳机
- 小型蓝牙音箱(Google Home mini)
- 中型蓝牙音箱(谷歌首页)
- 家庭娱乐系统(Google Home Max)
- 汽车扬声器
- 交互式语音应答(IVR)系统
这是听筒配置文件:
[audio wav="https://www.atyun.com/uploadfile/2018/08/handset-profile.wav"][/audio]
这是手机配置文件:
[audio wav="https://www.atyun.com/uploadfile/2018/08/phone-profile.wav"][/audio]
语音到文本更新
谷歌在今年7月的Google Cloud Next开发者大会上宣布了少量新的云语音到文本功能,今天又为其中的三个功能提供了更多的信息:
- 多通道识别
- 语言自动检测
- 词级置信度
通过自动表示每个单词的单独通道,多通道识别提供了一种简单的方法来转录多个音频通道。(谷歌指出,实现最佳转录质量通常需要使用多个通道)。对于未单独录制的音频样本,Cloud Speech-to-Text提供了diarization,它使用机器学习通过识别扬声器标记每个单词数。谷歌表示,标签的准确性会随着时间的推移而提高。

谷歌云的Speech-to-Text diarization特征
这一切都很有用处,但如果你是一个拥有大量双语用户的开发人员呢?输入语言自动检测功能,可让你在查询云语音到文本时一次最多发送四个语言代码。该API将自动决定使用哪种语言,并返回一份文字记录,就像谷歌助手如何检测语言并以某种方式做出回应一样(用户还可以选择手动选择语言)。
最后,在云语音到文本的前沿是词级置信度,它为开发人员提供了对谷歌语音识别引擎的细粒度控制。如果你这样选择,你可以将置信度分数与应用程序中的触发器相关联,例如,用户说话含糊或过于轻柔时,鼓励用户进行重复。
多通道识别、语言自动检测和词级置信度现在是可以使用的。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消