











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用机器学习来进行自动化文本分类
2018年01月16日 由 nanan 发表
299342
0
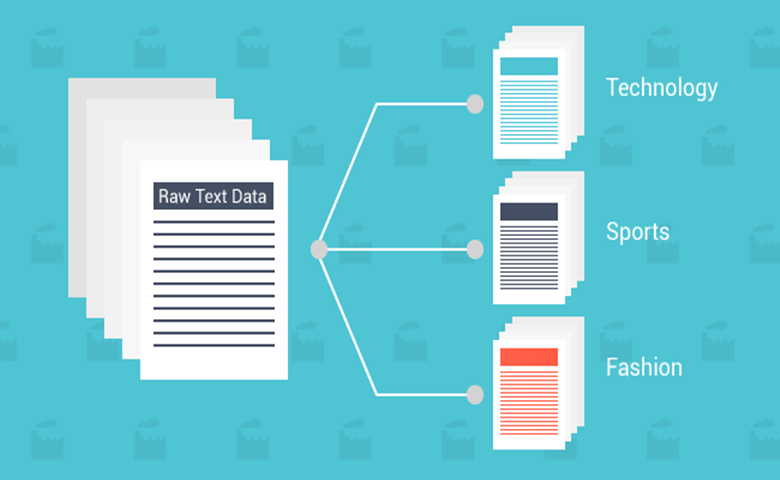
数字化已经改变了我们处理和分析信息的方式。信息的在线可用性呈指数增长。从网页到电子邮件、科学期刊、电子书、学习内容、新闻和社交媒体都充满了文本数据。其理念是快速创建、分析和报告信息。这是自动文本分类的步骤。
自动化文本分类是文本分类的一种智能分类,而且,使用机器学习来实现这些任务的自动化,会使整个过程变得非常快速和高效。人工智能和机器学习可以说是近年来最热门的技术,而且到处都能找到相关的应用。正如Jeff Bezos在他的年度股东信中所说:“在过去的几十年里,计算机有着广泛的自动化任务,程序员可以用清晰的规则和算法来描述这些任务。现在的机器学习技术也将允许我们在描述精确规则要困难的多的任务上也这样做。”
特别是关于自动化文本分类。在本文中,我们将讨论与自动化文本分类API相关的技术、应用程序、自定义和细分。
文本数据的意图、情感和情绪分析是文本分类中最重要的部分。这些用例已经在机器智能爱好者中引起了极大地轰动。我们已经为每个类别开发了单独的分类器,因为他们的研究本身就是一个巨大的课题。文本分类器可以在各种文本数据集进行操作。你可以使用带标记的数据对分类器进行训练,也可以对原始的非结构化文本进行操作。这两个类别都包含许多应用。
监督文本分类
当你定义分类类别时,将对文本进行监督分类。它的工作原理是训练和测试。我们为机器学习算法提供标签数据。该算法在标记的数据集上进行训练,并给出所需的输出(预定义的类别)。在测试阶段,该算法使用未观察到的数据,并根据训练阶段对其进行分类。
垃圾邮件过滤是监督分类的一个例子。收到的电子邮件会根据其内容自动分类。语言检测、意图、情感和情绪分析都是基于监督系统。它可以对特殊的用例进行操作,例如通过分析数百万在线信息来识别紧急情况。这真是大海捞针的问题。我们提出了一个智能公共交通系统来识别这种情况。为了识别数百万在线会话中的紧急情况,分类器必须进行高精度的训练。它需要特殊的损失函数,在训练时采样,以及建立一个多分类器堆栈的方法,每个分类器都细化了前一个的结果来解决这个问题。
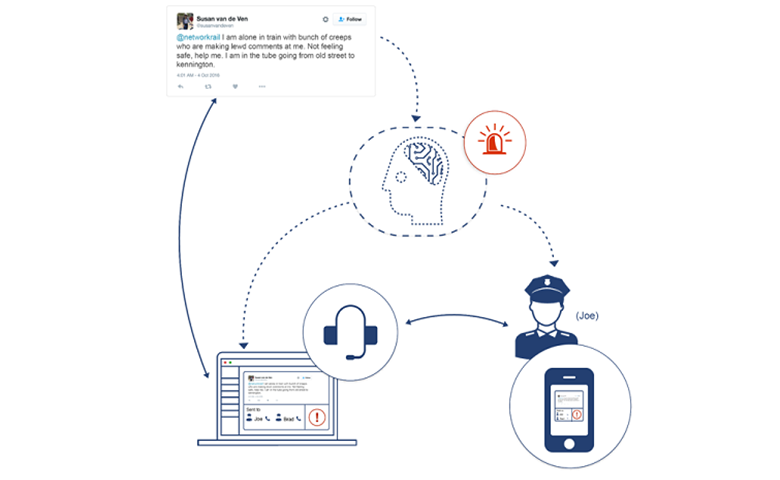
监督分类基本上是让电脑模仿人类。这些算法被赋予一组标记/分类文本(也称为训练集),基于它们生成AI模型,当进一步给定新的未标记文本时,这些模型可以自动对它们进行分类。我们的几个API,都是在监督系统下开发的。文本分类器目前训练了一套通用的150个类别。
无监督的文本分类
无监督分类是在不提供外部信息的情况下完成的。在这里,算法试图发现数据中的自然结构。请注意,自然结构可能不是人类所想象的逻辑划分。该算法在数据点中寻找相似的模式和结构,并将它们分组成簇。数据的分类是基于所形成的集群来完成的。以web搜索为例。该算法根据搜索词生成集群,并将其作为结果呈现给用户。
每个数据点都嵌入到超空间,你可以在TensorBoard上对其进行可视化。下图是我们在印度电信公司Reliance Jio上做的twitter研究。

数据挖掘是基于文本相似性来寻找相似的数据点。这些类似的数据点为最近的邻居群集。下面的图片显示了rs99上的“reliance jio prime会员”的最近邻居:这里是如何获得rs 100 cashback ...
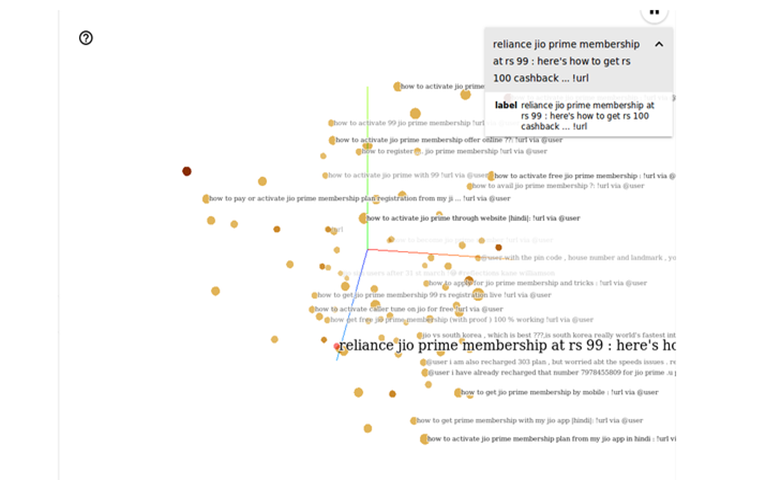
正如你所看到的,随附的推文与标签相似。这个集群如果有一类相似的tweet,无监督的分类在生成文本数据的洞察力时很有用。它是高度可定制的,因为不需要标记。它可以在任何文本数据上运行而无需进行训练和标记。因此,无监督分类是语言不可知的。
自定义文本分类
很多时候,使用机器学习的最大障碍是数据集的不可用性。有很多人想用人工智能来对数据进行分类,但这需要做一个数据集,从而产生类似于先有鸡还是先有蛋的问题。自定义文本分类是在没有任何数据集的情况下构建自己的文本分类器的最佳方法之一。
在ParallelDots的最新研究工作中,我们提出了一种对文本进行零点学习的方法,在这种方法中,训练学习在大型噪声数据集上学习句子及其类别之间关系的算法可以推广到新的类别,甚至是新的数据集。我们称这种模式为“一次训练,可在任何地方进行测试”。我们还提出了多种神经网络算法,可以利用这种训练方法,在不同的数据集上得到很好的结果。最好的方法是使用LSTM模型来完成学习关系。这个想法是,如果人们能够在句子和类之间建立“归属”的概念,那么这个知识对于看不见的类,甚至是看不见的数据集都很有用。
如何构建自定义文本分类器?
要构建自己的自定义文本分类器,你需要先注册一个ParallelDots帐户并登录到你的仪表板。
你可以通过点击仪表板上的“+”图标来创建你的第一个分类器。接下来,定义你想要对数据进行分类的一些类别。请注意,为了达到最好的效果,请保持你的类别互斥。
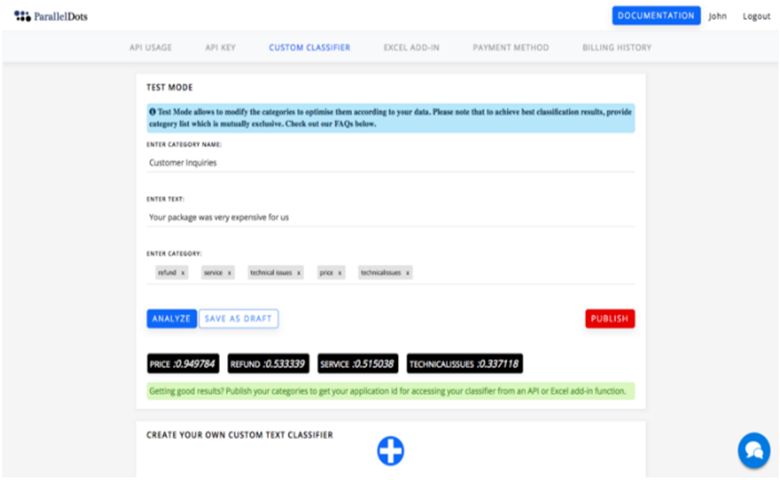
你可以通过分析文本的样本来检查分类的准确性,并在发布之前调整你的分类列表。一旦类别发布,你将获得一个应用程序ID,这将允许你使用自定义分类API。
考虑到数据标记和准备可能是一种限制,自定义分类器可以作为一种很好的工具,来构建文本分类器而无需大量的投资。我们也相信,这将降低构建实用的机器学习模型的门槛,这种机器学习模型可以跨行业应用于解决各种使用案例。文本分类就是这样一个有巨大潜力的技术。随着越来越多的信息被倾倒在互联网上,智能机器算法可以很容易地分析和表达这些信息。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消