


















在机器学习中处理缺失数据的方法
数据中包含缺失值表示我们现实世界中的数据是混乱的。可能产生的原因有:数据录入过程中的人为错误,传感器读数不正确以及数据处理管道中的软件bug等。
一般来说这是令人沮丧的事情。缺少数据可能是代码中最常见的错误来源,也是大部分进行异常处理的原因。如果你删除它们,可能会大大减少可用的数据量,而在机器学习中数据不足的是最糟糕的情况。
但是,在缺少数据点的情况下,通常还存在隐藏的模式。它们可以提供有助于解决你正尝试解决问题的更多信息。
我们对待数据中的缺失值就如同对待音乐中的停顿一样 - 表面上它可能被认为是负面的(不提供任何信息),但其内部隐藏着巨大的潜力。
方法
注意:我们将使用Python和人口普查数据集(针对本教程的目的进行修改)
你可能会惊讶地发现处理缺失数据的方法非常多。这证明了这一问题的重要性,也这证明创造性解决问题的潜力很大。
你要做的第一件事是统计你有多少人,并试着想象他们的分布。为了使这一步正常工作,你应该手动检查数据(或者至少检查它的一个子集),以确定它们是如何被指定的(即确定它们是何种缺失)。可能的情况有哦:“NaN”,“NA”,“None”,“ ”,“?”等等。如果除了NaN以外,你应该使用np.nan来标准化它们。为了可视化,我们在这里使用missingno包。
import missingno as msno
msno.matrix(census_data)

缺失数据的可视化 白色的地方表示NA的字段
import pandas as pd
census_data.isnull().sum()
age 325
workclass 2143
fnlwgt 325
education 325
education.num 325
marital.status 325
occupation 2151
relationship 326
race 326
sex 326
capital.gain 326
capital.loss 326
hours.per.week 326
native.country 906
income 326
dtype: int64
我们从最简单的事情开始:删除。正如前面提到的,虽然这是一个快速的解决方案。但是,除非你的缺失值的比例相对较低(<10%),否则,在大多数情况下,删除会使你损失大量的数据。想象一下,仅仅因为你的某个特征中缺少值,你就要删除整个观察记录,即使其余的特征都完全填充并且包含大量的信息!
import numpy as np
census_data = census_data.replace('np.nan', 0)
第二糟糕的方法是用0(或-1)替换。虽然这能够帮助你顺利运行模型,但这种方法可能非常危险的。原因是有时候这个价可能会让人产生误解。设想在回归问题中出现负值(如预测温度),在这种情况下,这个值会成为一个实际的数据点。
现在我们已经有了这些,让我们变得更有创意。我们可以按其父数据类型拆分缺失值的类型:
数字NaN
一个标准的,通常非常好的方法是用均值,中位数或众数替换缺失值。对于数值,一半来说你应该使用平均值。如果有一些离群值的话,可以试试使用中位数(因为中位数对离群值的不那么敏感)。
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values=np.nan, strategy='median', axis=0)
census_data[['fnlwgt']] = imputer.fit_transform(census_data[['fnlwgt']])
分类NaN
分类值可能比较麻烦,所以在编辑之后,你一定要注意模型性能指标(比较之前和之后看看是否有异常情况)。标准的做法是用最常见的条目替换缺失的条目:
census_data['marital.status'].value_counts()
Married-civ-spouse 14808
Never-married 10590
Divorced 4406
Separated 1017
Widowed 979
Married-spouse-absent 413
Married-AF-spouse 23
Name: marital.status, dtype: int64
def replace_most_common(x):
if pd.isnull(x):
return most_common
else:
return x
census_data = census_data['marital.status'].map(replace_most_common)
结论
我想要表达的关键是,你需要寻找到不同的方法从缺失的数据中获得更多的信息,更重要的是培养你洞察力的机会,而不是烦恼。要快乐的编程。
高级方法和可视化
你可以理论上通过拟合一个回归模型(比如线性回归或kNN算法)来估算缺失值。剩下的实现是留给读者的示例。
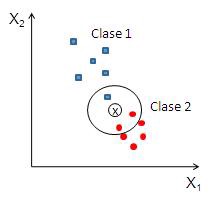
kNN可视化示例
下面是一些能在missingno包中找到的可视化的图像,它可以以相关矩阵或树状图的方式帮助你了解缺失值之间的关系:
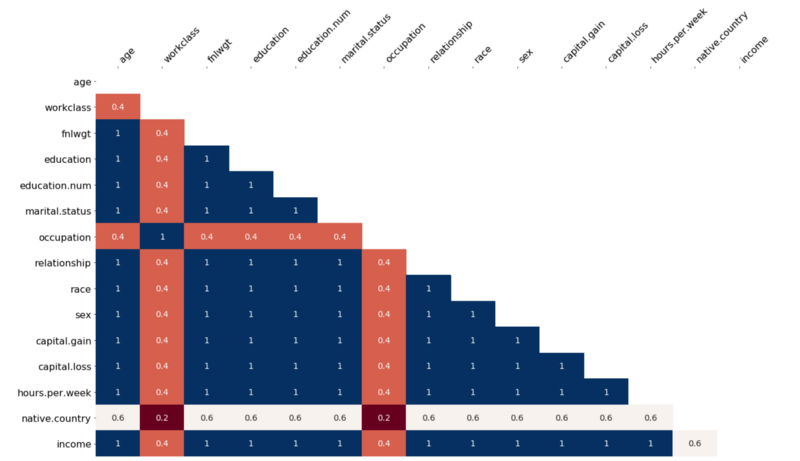
缺失值的相关矩阵 经常同时缺失的值可以帮助你解决问题
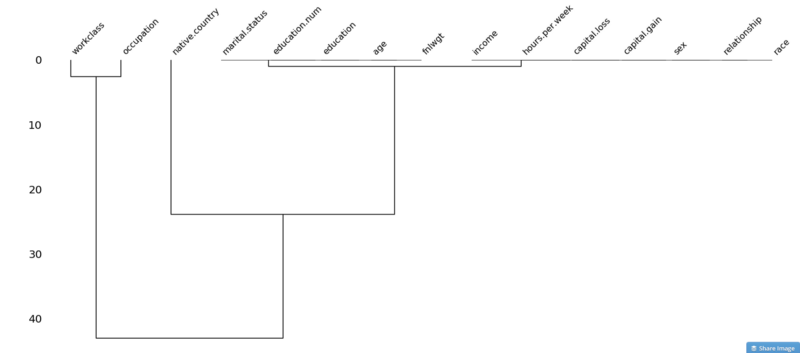
缺失值的树状图
或者,你也可以考虑选择一个处理缺失值的算法(例如,Boosting算法)。









