



















机器学习黑客系列:模型比较与选择
训练机器学习并生成模型以供将来预测的科学被广泛使用。为了更好地解决我们的问题,我们引入了不会太复杂的代码,更高级的学习算法和统计方法。
模型的比较和选择在我关于“机器学习101和线性回归”的论文中广泛讨论,我们尝试使用机器学习来解决的问题可以主要分为两种类型:监督机器学习与无监督机器学习。监督学习从标记的数据中学习,例如,房屋特征的数据,其中还包括房价,房价预测。换句话说,监督机器学习学习标记的数据点,并预计未来的标记数据点。
而无监督学习则从无标记的数据中学习,不能预测未来数据点的标签。它通常用于数据的维度缩减,数据的聚类等等。
在这篇文章中,我们将讨论有监督的学习相关问题,模型和方法。这需要你熟悉一些机器学习方法,如线性回归,岭回归和Lasso并且知道如何使用这些方法来训练模型。
这个系列被称为“机器学习黑客”,目的是强调开发人员就算不是数据科学家也可以训练模型和使用机器学习,并充分利用它。虽然有大量的工具和库可以在10行代码下训练机器学习模型,但作为一个数据黑客你需要熟悉的不仅仅是培训模型。你需要知道如何评估,比较和选择最适合你的特定数据集。
通常,在使用给定数据集的机器学习问题时,我们尝试不同的模型和技术来解决优化问题,并适应最精确的模型,既不会过度使用也不能降低成本。
在处理现实世界的问题时,我们的数据集中通常有几十个特征。其中一些可能是描述性的,有些可能会重叠,有些甚至增加的噪音强过给我们的数据信号。
使用之前关于我们所从事的行业的知识来选择特性是也很好的,但有时我们需要一个分析工具,更好地选择我们的特性,并比较使用不同算法训练的模型。
我的目标是为你介绍最常用的技术和标准比较你训练的模型,以便为你的问题选择最准确的模型。
具体来说,我们将看到如何在使用相同算法训练的不同模型之间进行选择。假设我们有一个数据集,每个数据点的一个特征,我们想要使用线性回归拟合。我们的目标是根据8个不同的假设,选择最佳的拟合模型的多项式次数。
实际问题与数据集
我们被要求根据面积预测房价。提供给我们的数据集包含纽约1200个房屋的面积和价格。当先前的知识几乎没有给我们关于模型替代选择的假设时,我们尝试使用线性回归来配置一个预测未来房价的模型:
Ŷ1 = β0+β1X
Ŷ2 = β0+β1X+β1X2
Ŷ3 = β0+β1X+β2X2+β3X3
Ŷ4 = β0+β1X+β2X2+β3X3+β4X4
Ŷ5 = β0+β1X+β2X2+β3X3+β4X4+β5X5
Ŷ6 = β0+β1X+β2X2+β3X3+β4X4+β5X5+β6X6
Ŷ7 = β0+β1X+β2X2+β3X3+β4X4+β5X5+β6X6+β7X7
Ŷ8 = β0+β1X+β2X2+β3X3+β4X4+β5X5+β6X6+β7X7+β8X8
其中X表示房屋面积。
考虑到8种模型替代选择,我们被要求使用一些标准来比较模型,并选择最适合我们的数据集来预测未来房价的多项式次数。
如我之前的文章所述,复杂的模型容易过拟合。因此,我们在选择我们的模型时要小心,这样它将为我们提供对当前数据集和未来数据点的良好预测。
什么是训练与测试分离,以及我们为什么需要它
在处理现实的机器学习问题时,我们的数据集的大小有限。使用相对较小的数据集,我们要训练我们的模型以及评估它的准确性。这就需要用到训练与测试分离。
训练与测试分离是一种将我们的数据集分为两组的方法,一组用于训练模型的训练组,一组用于测试模型的测试组。我们通常不会将它们平均分离,因为训练模型通常需要尽可能多的数据点。
训练与测试分离的常见分离比例是70/30或80/20。
如何比较模型
评估训练机器学习模型的最基本指标是MSE。MSE代表均方误差,由误差平方的平均值求出。换句话说,MSE是预测值和实际值之间的差值,所以我们希望在训练模型时将其最小化:
MSE =Σ(ŶŶ)2 / n
其中n是数据点的数量。
应谨慎使用MSE。因为MSE可以在训练数据点或测试数据点上计算。使用MSE的去评估模型的正确方法是使用我们的训练数据训练我们的模型,然后使用我们的测试数据集计算MSE 。
如果没有对我们的数据进行训练与测试分离,我们将被迫在同一数据集上训练模型和计算MSE。这种情况会引起过拟合。那么为什么会这样呢?
假设没有对我们的数据进行训练与测试分离,训练了8个模型(如上所述),并计算了每个模型的MSEtrain。哪个型号将为我们提供最低的MSEtrain?最有可能的是模型8,因为它是最复杂的一个,不是学习数据而是过拟合数据。
因为我们使用完全相同的数据集来训练和测试模型,MSEtrain将会下降,于是我们使用更复杂的更大程度拟合训练数据的模型(不要忘了我们尝试解决的优化问题是让预测和实际的误差最小化)。
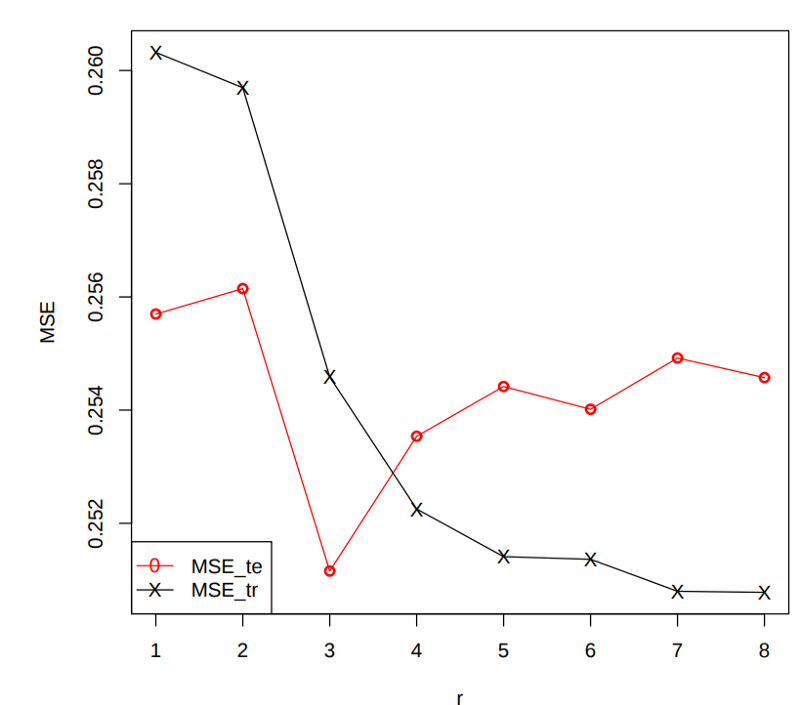
所以我们了解到,在我们分离数据集之后,我们会更好地使用MSE来测试它。但是有更先进的标准替代常用的单纯使用MSE的标准评估我们的模型(基于MSE)。
我们可以使用哪些标准
在了解为什么我们需要将数据分离训练和测试,以及MSE的含义后,我们将介绍3个主要标准用于比较我们8种不同模型。这些标准让你了解如何处理过拟以及合如何为数据集选择最好的模型。
1:Mallows's Cp
Cp是1973年Mallows提出的一种统计方法用于计算期望的偏差。假设我们有一个非常小的数据集,以至于将其分成训练和测试没有意义,我们就可以使用Cp,以便使用在训练数据集上计算的MSEtrain来估计MSEtest。
Cp标准或MSEtest的估计由下式给出:
Cp = MSEtrain +2σ2P/ n
其中σ2是基于完整模型(8号模型)的误差方差,P是预测值的数量。
为了使用Mallows's Cp来比较我们的模型,我们需要在完整数据集上训练每个模型,为每个训练模型计算Mallows's Cp估计量,并选择具有最低Cp结果的模型。
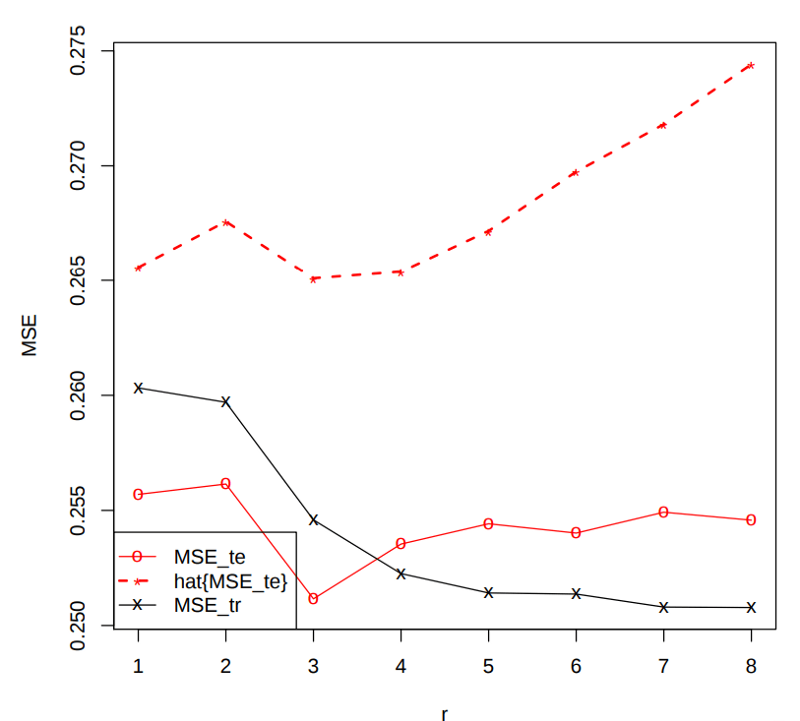
我们可以看到,MSEtrain随着多项式次数的增加(更复杂的模型)而减少时,我们不能指出该选择哪个模型,MSEtest和Mallows的Cp标准都将选择模型3为基于数据集的最佳模型。
注意:Mallows's Cp没有被开发成评估没有使用线性回归训练的模型。因此,你不得将其与使用其他机器学习算法训练的模型一起使用。
2:BIC
我们已经提到,当拟合模型时,添加参数并使模型更加复杂可能导致过拟合。BIC是试图通过为模型中的参数数量引入惩罚项来解决此问题的统计标准。
BIC(Bayesian Information Criterion)即贝叶斯信息准则,假设提出的模型中存在正确的模型,我们的目标是选择它。
数学公式非常类似于Mallows's Cp,如下:
BIC = MSEtrain + log(n)σ2P/ n
具有最低BIC的模型是首选。
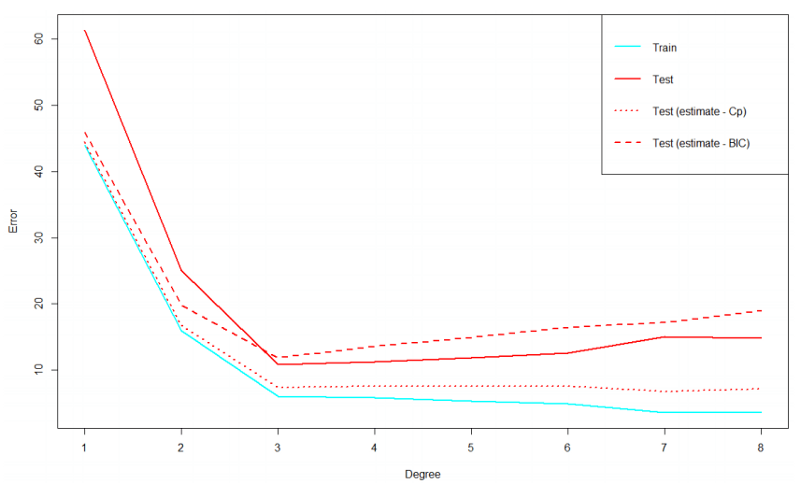
MSEtrain的值先不看,所有其他的标准都选择模型3最佳拟合数据。
注意:当我们不确定建议模型中是否存在正确模型时,BIC可能以出人意料的方式表现。因此,在实际应用中,我们应该谨慎使用。
3:交叉验证
处理机器学习问题需要很好地理解交叉验证(CV)。在机器学习中交叉验证以很多不同的方式被应用,即所有有关比较或选择参数和模型。
交叉验证基于训练与测试分离方法的延伸。它的优点是,它任意分割数据集多次,并且每次在一个稍微不同的数据集上对训练模型的进行测试。
通过这样做,我们确定我们不会基于异常值或不正确表示信号的数据来评估模型的错误。接着我们为这个基于多个训练与测试分离的模型每个分离的评估平均这个MSEtest:
CV(n)=ΣMSEi,test / n
优先选择CV(n)最低的模型。这里有一个关键点要理解 - 在比较使用交叉验证的模型时会有一个嵌套迭代 - 对于每个模型,我们随机分割数据集,计算MSEi,测试然后将它们平均为CV指标。因此,我们提出了每个模型的CV指标,在此基础上我们选择了首选模型。
交叉验证分割有两个主要实现:
- LOO交叉验证(Leave one out cross validation)
- K折交叉验证(最受欢迎)
LOO交叉验证,并且每次迭代从训练集中取出一个不包含在训练集的数据点,用于测试模型的性能。
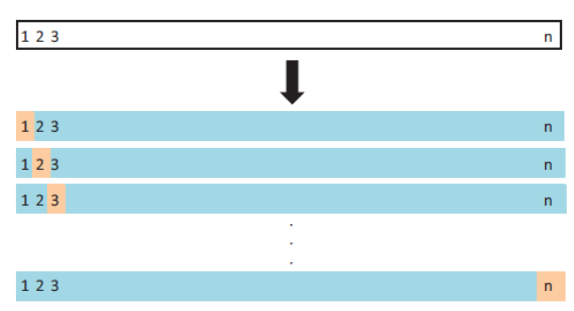
K折交叉验证获得K参数作为输入,将数据集分为K个部分,对每个部分进行迭代,每次迭代都将第k个部分排除在训练之外,并将其作为测试集使用。
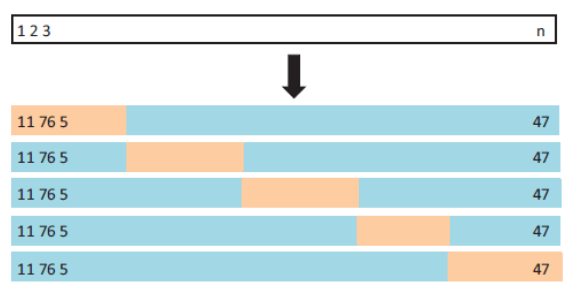
选择K参数是折叠次数有时可能是棘手的,因为它影响了我们的数据的偏差—方差权衡。一般选择5或10(取决于数据集的大小)。
交叉验证是机器学习和统计中使用的一个极好的工具。在下图中,我们可以看到不同的指标如何估计模型的误差。
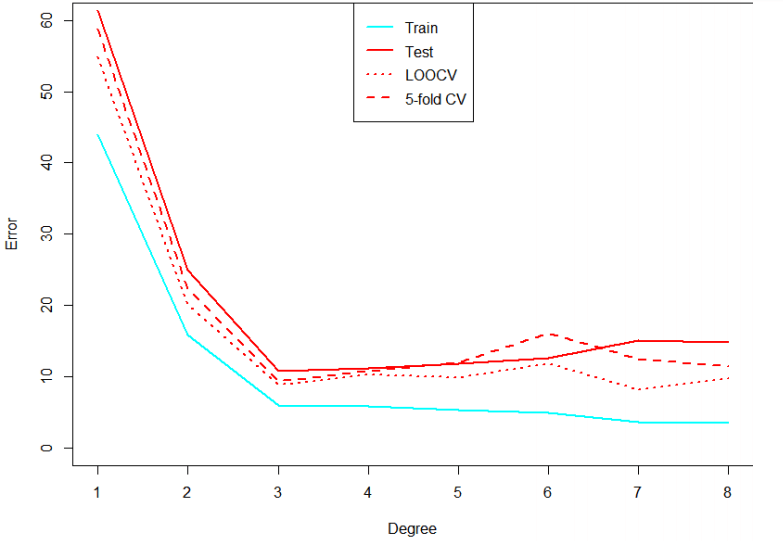
与Cp或BIC不同的是交叉验证在大多数机器学习算法中运行良好,并且不需要假设有一个正确的模型。
我也鼓励你查看Lasso方法。Lasso具有内置的正则化机制,可以从我们的模型中消除多余的特征,这是我们在比较不同型号时经常需要实现的功能。









