












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伯克利人工智能研究新实践:从单一的彩色图像中重建高质量的三维物体
2017年08月24日 由 yining 发表
19140
0
从图像上数字化重建三维几何图形是计算机视觉中的一个核心问题。它包含了各种各样的应用,比如电影制作,视频游戏的内容生成,虚拟现实和增强现实,3D打印等等。本文所讨论的任务是如何从一个物体的单一彩色图像中重建高质量的三维几何图形,如下图所示。
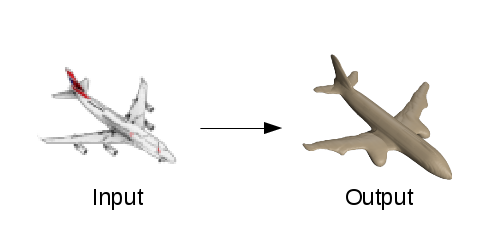
人类有能力毫不费力地推理出物体的形状和场景,即使我们只看到了一个单一的图像。我们的眼睛使我们能够感知深度,即使我们只看到一个物体的照片,我们也能很好地理解它的形状。此外,我们还能推理出物体看不到的部分,如背面,这是理解物体形状的重要能力。但问题是,人类是如何从单一的图像中推理出它的几何形状的? 就人工智能而言:我们怎么能教会机器这种能力呢?
从模棱两可的输入中重建几何图形的基本原则是,形状不是任意的,因此有一些形状是合适的,而有些不是。一般来说,这些形状表面是光滑的。在人造环境中,它们往往呈现出一种分段的平面。例如,飞机通常都有一个机身,两侧各有两个主机翼,背面则是垂直尾翼。在计算机视觉中,形状不是随意的。这一事实允许我们将单个或多个对象类的所有可能的形状描述为一个低维度的形状空间,它是从大量的示例图形中获得的。
一个最新的3D行业重建工作[Choy et al. ECCV 2016, Girdhar et al. ECCV 2016],利用卷积神经网络(CNNs)来预测物体的形状,以预测3D图形的体积。3D输出量被细分为体积元素,称为体素,每个体素的赋值都是被占用的或是空闲的空间,也就是物体的内部或外部。输入通常作为一个单独的彩色图像来描述物体,而卷积神经网络则通过一个升级的卷积解码结构来预测物体所占用的体积。该网络经过了端对端的训练,并对已知的地面实况占用体积进行了全程监控,这些数据都是从合成的CAD模型数据集中获得的。使用这种三维表达和卷积神经网络可以学习各种对象类的模型。
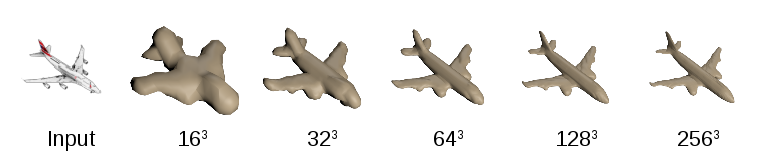
利用卷积神经网络预测物体体积的主要缺点是,输出空间是三维的,因此在提高分辨率方面有立方的增长。这个问题阻止了上面提到的高质量几何体的预测,因此被限制为低分辨率的体素网格,例如上图的323。这是一个不必要的限制,因为表面实际上只是二维空间。仅在预测低分辨率表面的情况下,我们利用表面的二维性质,通过分层来预测高分辨率体素。其基本理念与八叉树模型表示法密切相关,这种表示法常用于立体视觉和深度图融合,以表示高分辨率的几何图形。
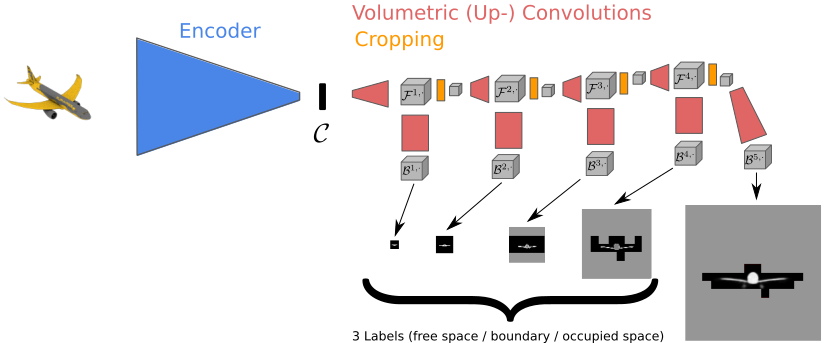
基本的3D预测管道采用彩色图像作为输入,它使用卷积编码器被编码成一个低维度表示。这个低维度表示被解码成一个3D占用体积。我们的方法主要采用分层面预测(HSP),它是通过预测低分辨率的体素来解码。然而,与标准方法不同的是,每一个体素都被划分为自由空间或被占用的空间,我们使用的三个类:自由空间、占用空间和边界。这使我们能够分析低分辨率下的输出,并且只预测有证据表明它包含了表面的部分的更高分辨率。通过迭代细化过程,我们可以分层地预测高分辨率的体素网格(见下图)。有关该方法的更多细节,请参阅技术报告[Häne et al. arXiv 2017]。
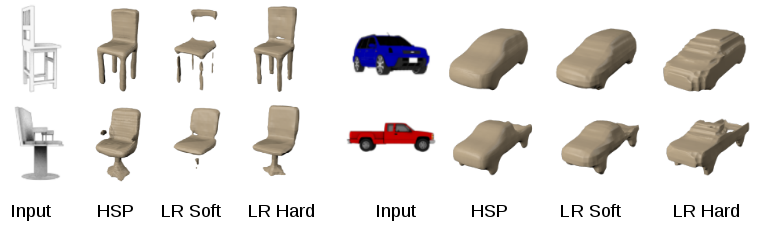
实验主要在合成的ShapeNet数据集[Chang et al. arXiv 2015]上进行。研究的主要任务是通过单一的彩色图像预测高分辨率的几何图形。我们将我们的方法与两条基线比较,这两条基线分别称之为低分辨率坚硬(LR hard)和低分辨率柔软(LR soft)。这些基线预测的低分辨率是323,但在训练数据的生成方式上有所不同。LR hard基线为体素使用二进制赋值。如果至少有一个相应的高分辨率的体素被占用的话,那么所有的体素都被标记为被占用。LR soft基线使用分数赋值反映了在相应的高分辨率的体素中所占的百分比。我们的方法HSP预测的分辨率为 2563。下面的数据显示了与低分辨率基线相比,高分辨率预测的优点和完整性。

本文基于科技报告:三维物体重建的分层表面预测,C. Häne, S.Tulsiani, J.Malik, ArXiv 2017。
人类有能力毫不费力地推理出物体的形状和场景,即使我们只看到了一个单一的图像。我们的眼睛使我们能够感知深度,即使我们只看到一个物体的照片,我们也能很好地理解它的形状。此外,我们还能推理出物体看不到的部分,如背面,这是理解物体形状的重要能力。但问题是,人类是如何从单一的图像中推理出它的几何形状的? 就人工智能而言:我们怎么能教会机器这种能力呢?
形状空间
从模棱两可的输入中重建几何图形的基本原则是,形状不是任意的,因此有一些形状是合适的,而有些不是。一般来说,这些形状表面是光滑的。在人造环境中,它们往往呈现出一种分段的平面。例如,飞机通常都有一个机身,两侧各有两个主机翼,背面则是垂直尾翼。在计算机视觉中,形状不是随意的。这一事实允许我们将单个或多个对象类的所有可能的形状描述为一个低维度的形状空间,它是从大量的示例图形中获得的。
使用卷积神经网络预测体素
一个最新的3D行业重建工作[Choy et al. ECCV 2016, Girdhar et al. ECCV 2016],利用卷积神经网络(CNNs)来预测物体的形状,以预测3D图形的体积。3D输出量被细分为体积元素,称为体素,每个体素的赋值都是被占用的或是空闲的空间,也就是物体的内部或外部。输入通常作为一个单独的彩色图像来描述物体,而卷积神经网络则通过一个升级的卷积解码结构来预测物体所占用的体积。该网络经过了端对端的训练,并对已知的地面实况占用体积进行了全程监控,这些数据都是从合成的CAD模型数据集中获得的。使用这种三维表达和卷积神经网络可以学习各种对象类的模型。
分层的表面预测
利用卷积神经网络预测物体体积的主要缺点是,输出空间是三维的,因此在提高分辨率方面有立方的增长。这个问题阻止了上面提到的高质量几何体的预测,因此被限制为低分辨率的体素网格,例如上图的323。这是一个不必要的限制,因为表面实际上只是二维空间。仅在预测低分辨率表面的情况下,我们利用表面的二维性质,通过分层来预测高分辨率体素。其基本理念与八叉树模型表示法密切相关,这种表示法常用于立体视觉和深度图融合,以表示高分辨率的几何图形。
方法
基本的3D预测管道采用彩色图像作为输入,它使用卷积编码器被编码成一个低维度表示。这个低维度表示被解码成一个3D占用体积。我们的方法主要采用分层面预测(HSP),它是通过预测低分辨率的体素来解码。然而,与标准方法不同的是,每一个体素都被划分为自由空间或被占用的空间,我们使用的三个类:自由空间、占用空间和边界。这使我们能够分析低分辨率下的输出,并且只预测有证据表明它包含了表面的部分的更高分辨率。通过迭代细化过程,我们可以分层地预测高分辨率的体素网格(见下图)。有关该方法的更多细节,请参阅技术报告[Häne et al. arXiv 2017]。
实验
实验主要在合成的ShapeNet数据集[Chang et al. arXiv 2015]上进行。研究的主要任务是通过单一的彩色图像预测高分辨率的几何图形。我们将我们的方法与两条基线比较,这两条基线分别称之为低分辨率坚硬(LR hard)和低分辨率柔软(LR soft)。这些基线预测的低分辨率是323,但在训练数据的生成方式上有所不同。LR hard基线为体素使用二进制赋值。如果至少有一个相应的高分辨率的体素被占用的话,那么所有的体素都被标记为被占用。LR soft基线使用分数赋值反映了在相应的高分辨率的体素中所占的百分比。我们的方法HSP预测的分辨率为 2563。下面的数据显示了与低分辨率基线相比,高分辨率预测的优点和完整性。
本文基于科技报告:三维物体重建的分层表面预测,C. Häne, S.Tulsiani, J.Malik, ArXiv 2017。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消