











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






机器学习为CAD插上一双翅膀(下)
2019年07月21日 由 sunlei 发表
787151
0
在昨天的文章中,我们主要讲述了在3个主要研究项目的基础上,这些项目最近构建了三维对象识别和分类领域。揭示了卷积作为理解和描述三维形状的理想工具的相关性。
传送门:机器学习为CAD插上一双翅膀(上)
我们在这个项目中的方法是识别用户正在绘制的对象,并通过简单地使用对象的形状作为代理来提供类似的对象。
简而言之,我们在这里设计的模型涉及两个主要任务:
(1)分类:识别用户正在绘制的对象类型,即为任何给定的图像输入找到适当的标签(“椅子”、“长椅”、“床”等),并结合预测置信度得分。
(2)匹配:在三维对象的数据库中,查询一些最符合用户建模输入方面的形状,即返回数据库中的对象列表,从最相似到最不相似排序。
[caption id="attachment_42178" align="aligncenter" width="1320"]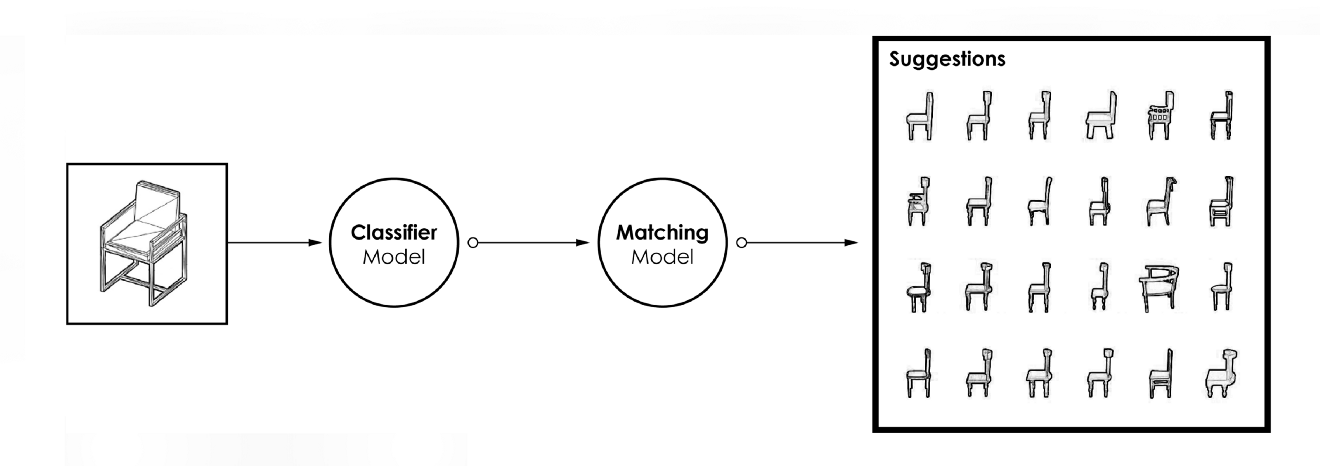 典型管道[/caption]
典型管道[/caption]
如上图所示,通过嵌套两个不同级别的模型(分类器和“匹配器”),我们可能能够执行这两步过程。每个模型将接受3D对象图像的训练,然后将在用户建模的对象图像上进行测试。
第一步是生成一个数据库来训练我们的模型。由于我们的方法论是要共享的,所以我们希望在这里详细说明这一关键步骤,并共享我们为实现这一点而使用和构建的资源。
我们首先从现有的公共3D对象仓库中提取信息,例如:
ShapeNet |链接
谷歌三维仓库|链接
ModelNet |链接
从ShapeNet数据库中,我们可以下载多达2.330个标记为3D models的14个特定类(下图)。
[caption id="attachment_42179" align="aligncenter" width="1320"]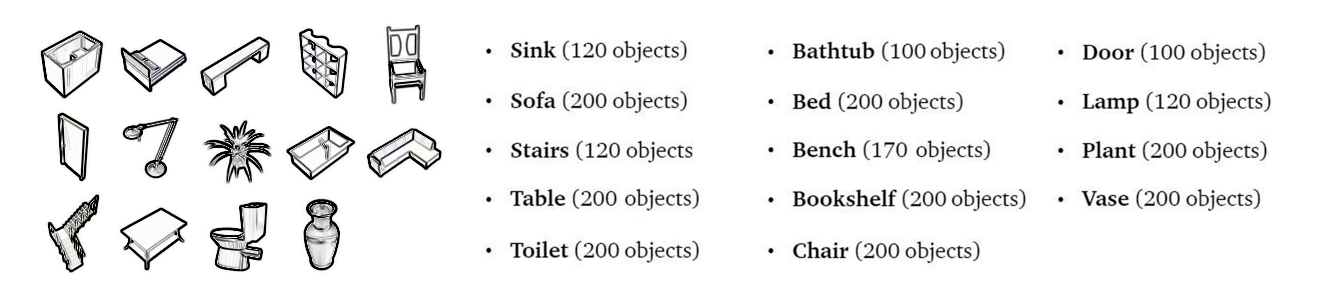 训练集的类[/caption]
训练集的类[/caption]
然后,我们使用Rhinoceros和Grasshopper编写脚本,创建一个工具来创建训练集和验证集。在这个脚本中,一个摄像机在每个连续的对象周围旋转,以特定的角度拍摄对象,并将JPG图像保存在给定的目录中。
下图显示了一个典型的相机路径(左侧)和所捕获的结果图像(右侧)。
[caption id="attachment_42180" align="aligncenter" width="1320"]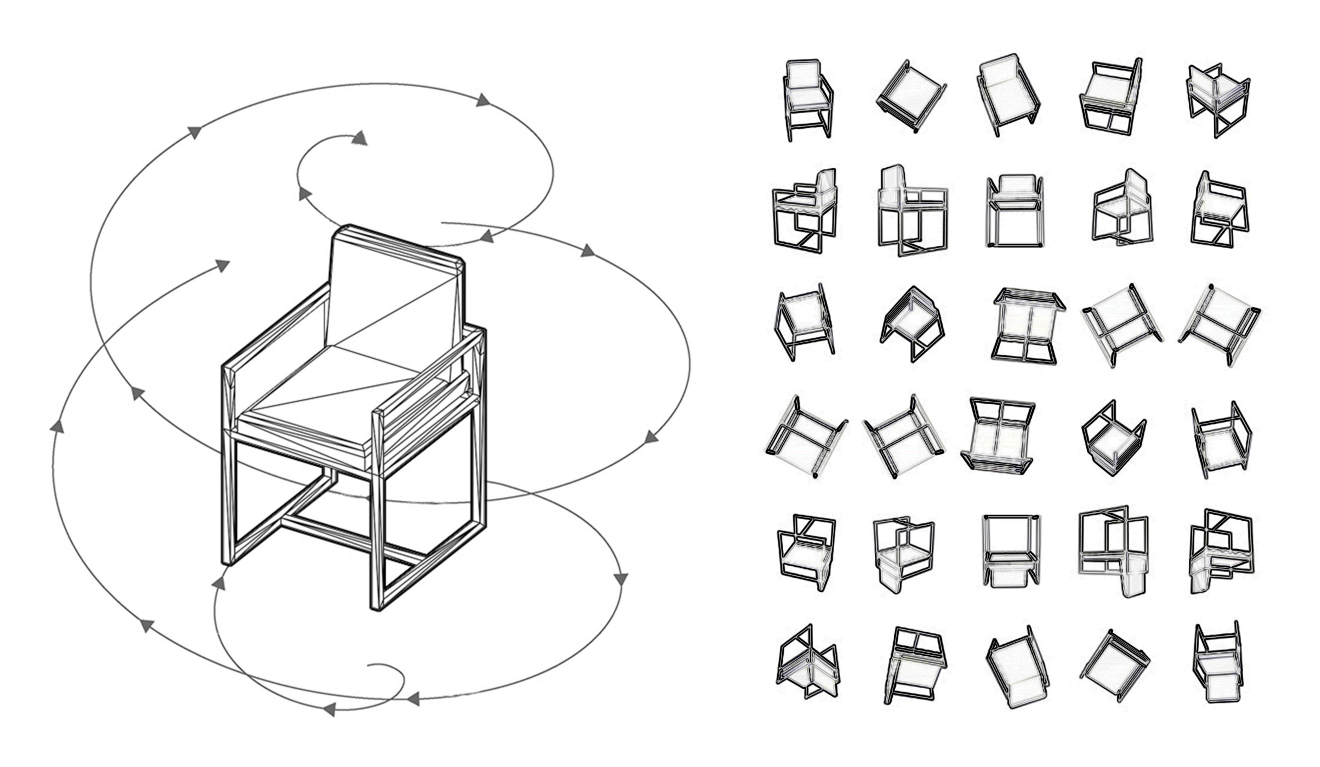 图像捕获路径,并生成图像[/caption]
图像捕获路径,并生成图像[/caption]
对于每个对象,我们使用30张图像进行训练,10张图像进行验证,同时保留白色背景/中性背景。
用于捕获图像的数据生成器可在以下地址下载。
我们最终获得了一个带标签的图像库,每个类对应10个对象,总共有14个不同的类。这里显示了一个子集,如下图所示。
[caption id="attachment_42181" align="aligncenter" width="2600"] 训练集的子集[/caption]
训练集的子集[/caption]
一旦我们的数据集准备好了,我们的目标就是训练我们的第一个模型,分类器,在大量的3D对象的图像上进行训练,同时验证它在属于类似类的其他对象的图像集上的性能。
几个参数严重影响经过训练的分类器的精度:
此时,我们在不同的选项之间进行迭代,目的是提高验证集上模型的整体准确性。由于资源有限,我们不能从头开始训练。使用一些转移学习是很方便的,因为它可以提高我们的模型的准确性,同时绕过几天的训练。我们在模型的第一层添加了一个VGG16预训练模型,这将使我们的准确率提高32%。
这个训练过程的一个关键要点是,摄像机的路径实际上会显著影响结果的准确性。在我们尝试过的许多版本中,我们在下面的图中演示了两种不同相机路径(圆形和球形)的比较性能。
[caption id="attachment_42182" align="aligncenter" width="2600"]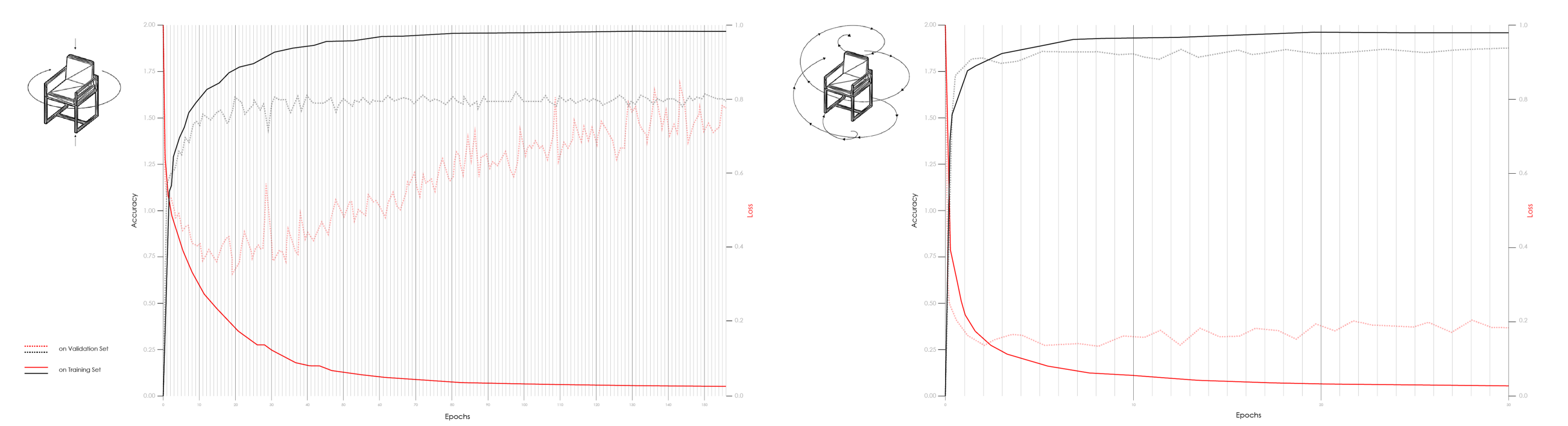 不同图像采集技术下的训练性能[/caption]
不同图像采集技术下的训练性能[/caption]
最后,我们用200*200像素的图像作为分类器,球形摄像机路径,每个对象30个图像用于训练,10个图像用于验证。经过30个周期的验证,我们最终得到了93%的验证集。现在看来,以下参数对整体模型的性能影响很大:
增加图像大小可以提高精度。在我们的机器上,速度和精度之间的平衡在200x200px左右。
相机的拍摄路径也直接影响着拍摄的准确性。通过使用球形捕获路径,而不是圆形路径(请参见图上图),我们显著地提高了模型性能:在更少的周期之后,精确度要高得多。使用球面路径似乎是一种更全面的方法来捕捉给定形状的外观。
上图显示了四个不同用户输入的分类器的典型结果。
[caption id="attachment_42183" align="aligncenter" width="1320"]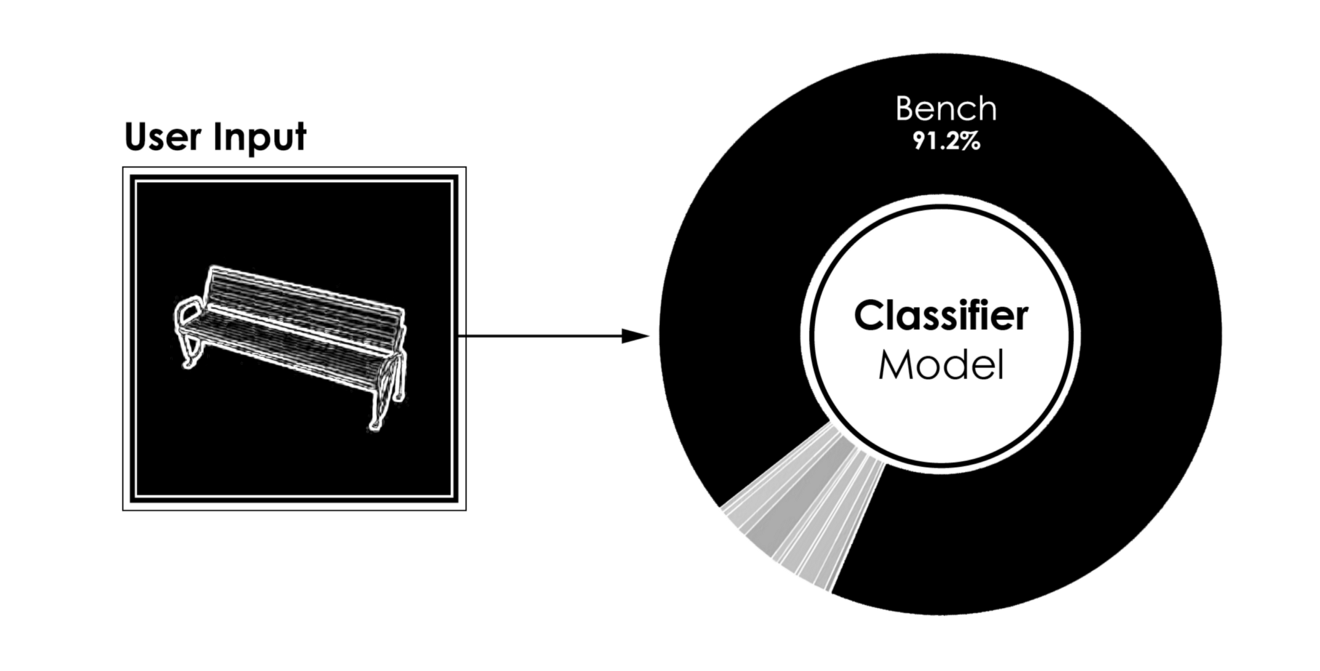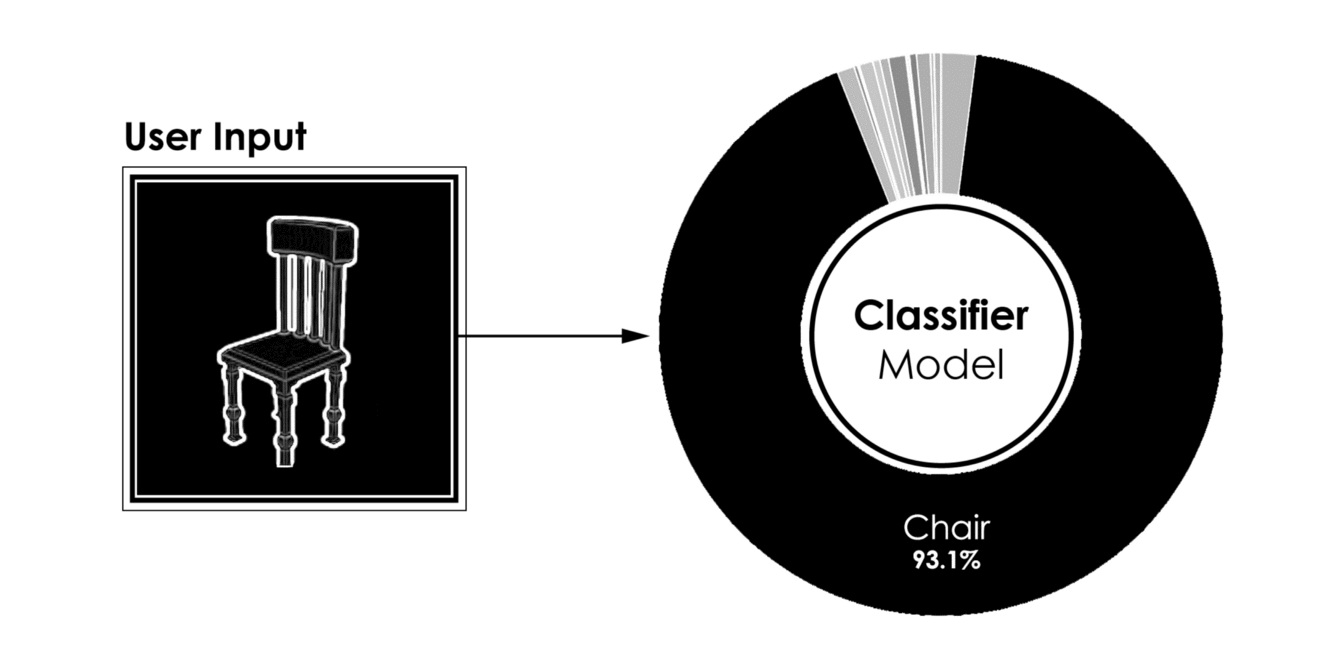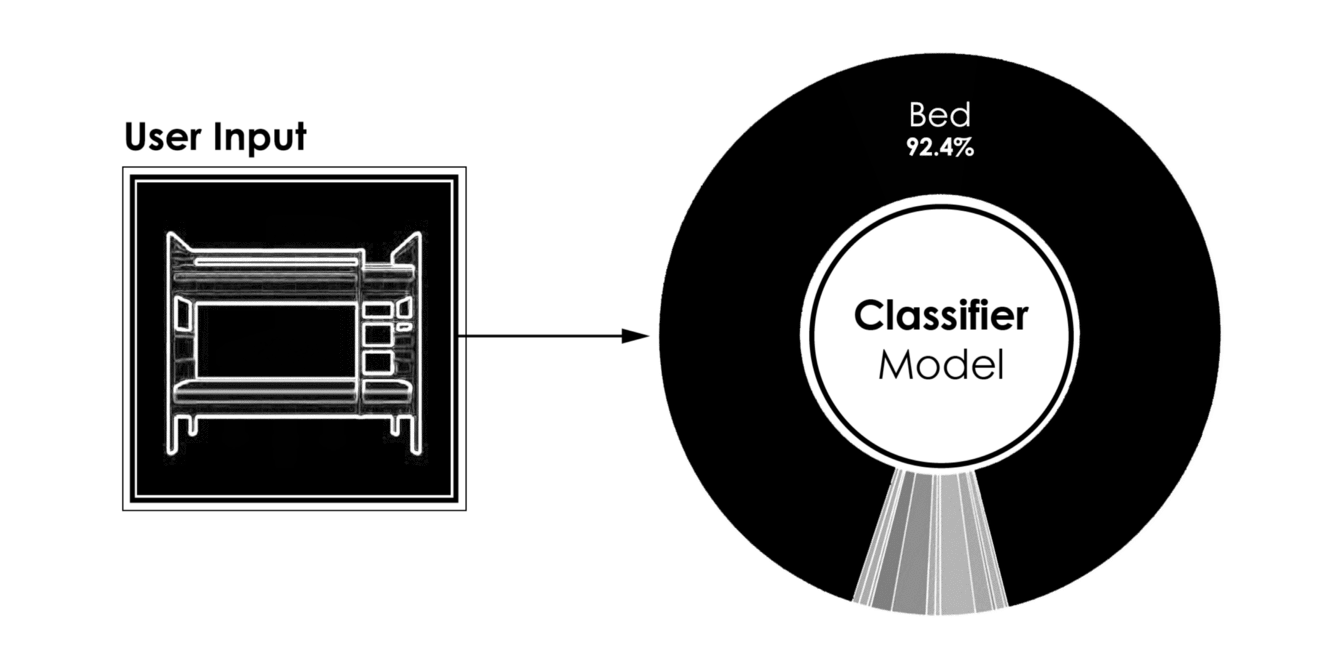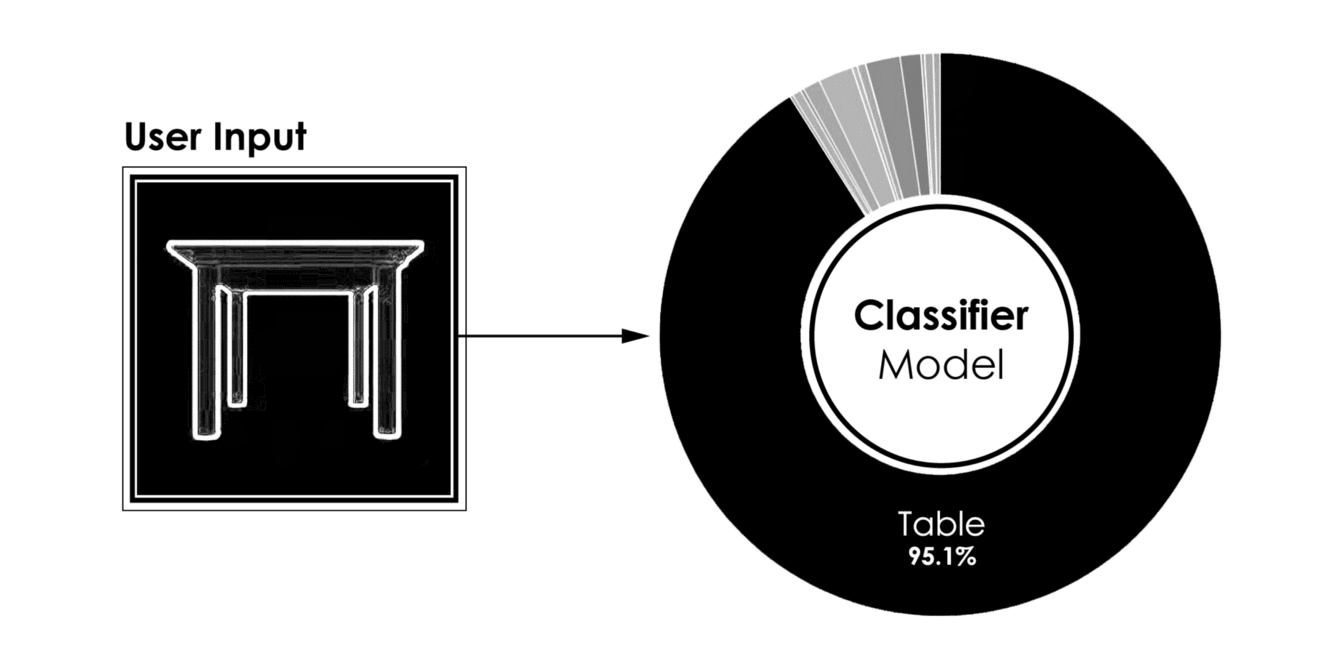 分类器模型的结果,用户输入(左)到预测类(右)[/caption]
分类器模型的结果,用户输入(左)到预测类(右)[/caption]
[caption id="attachment_42184" align="aligncenter" width="1320"]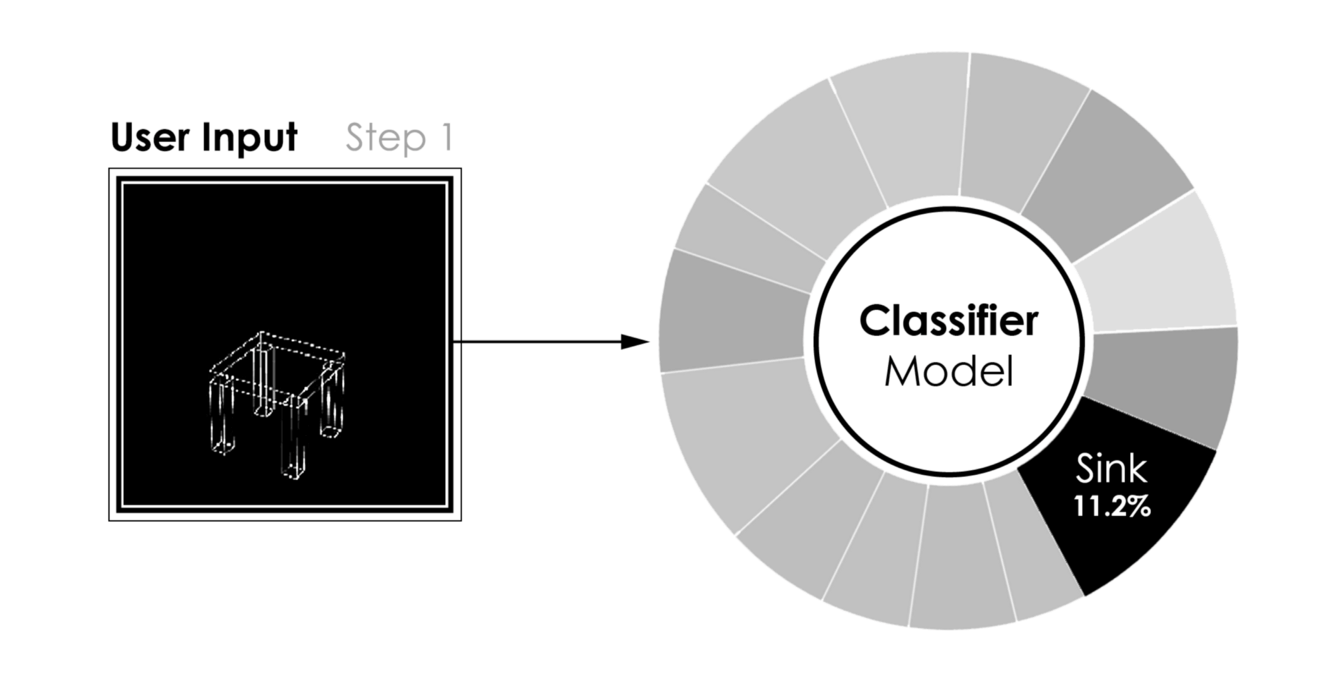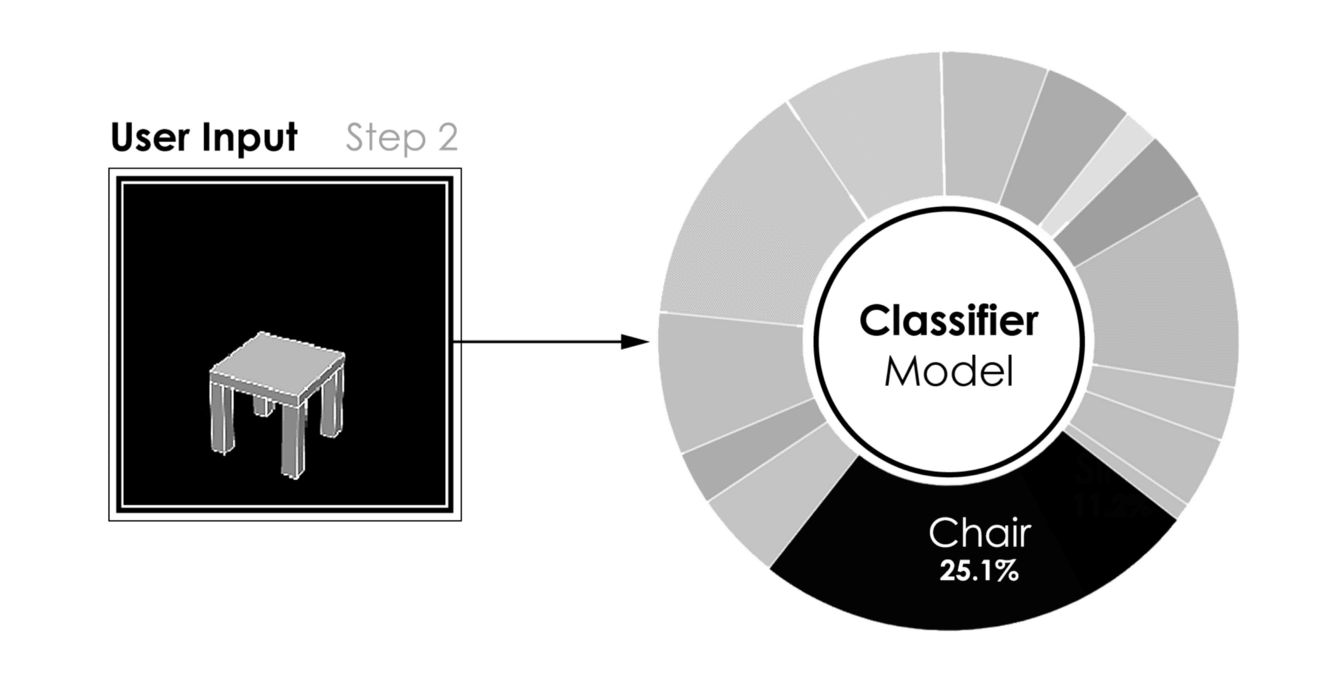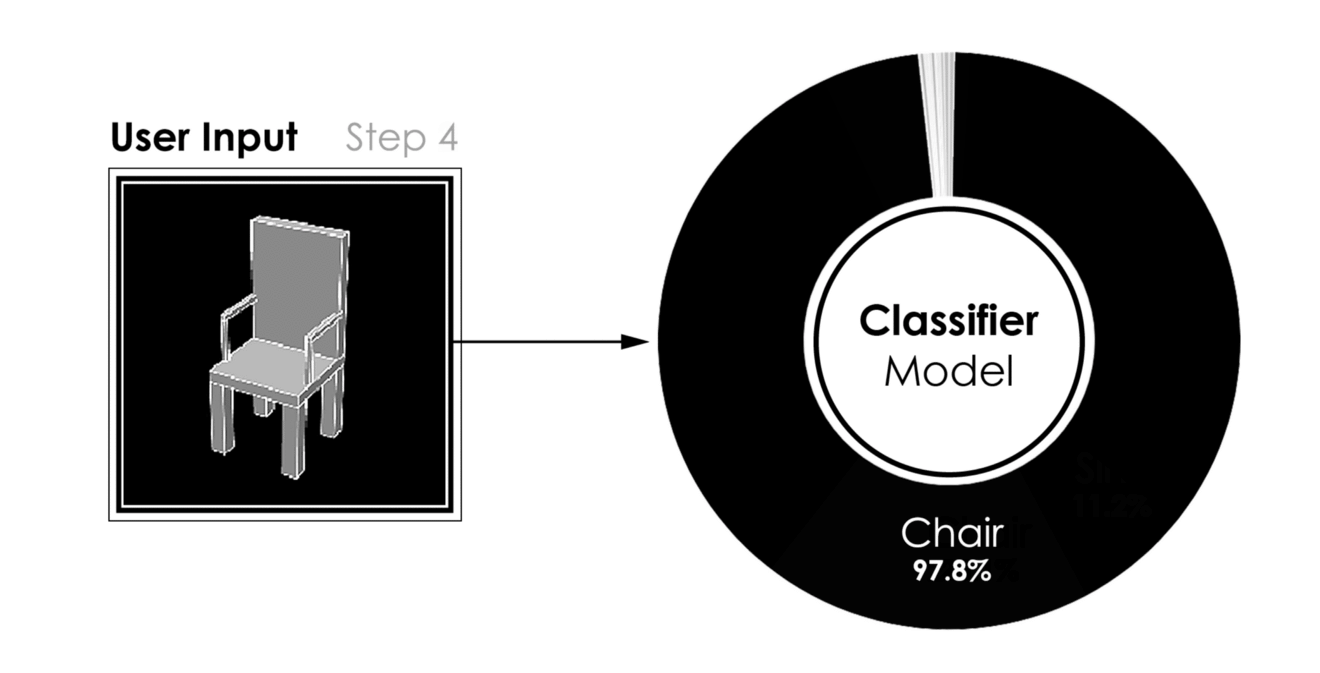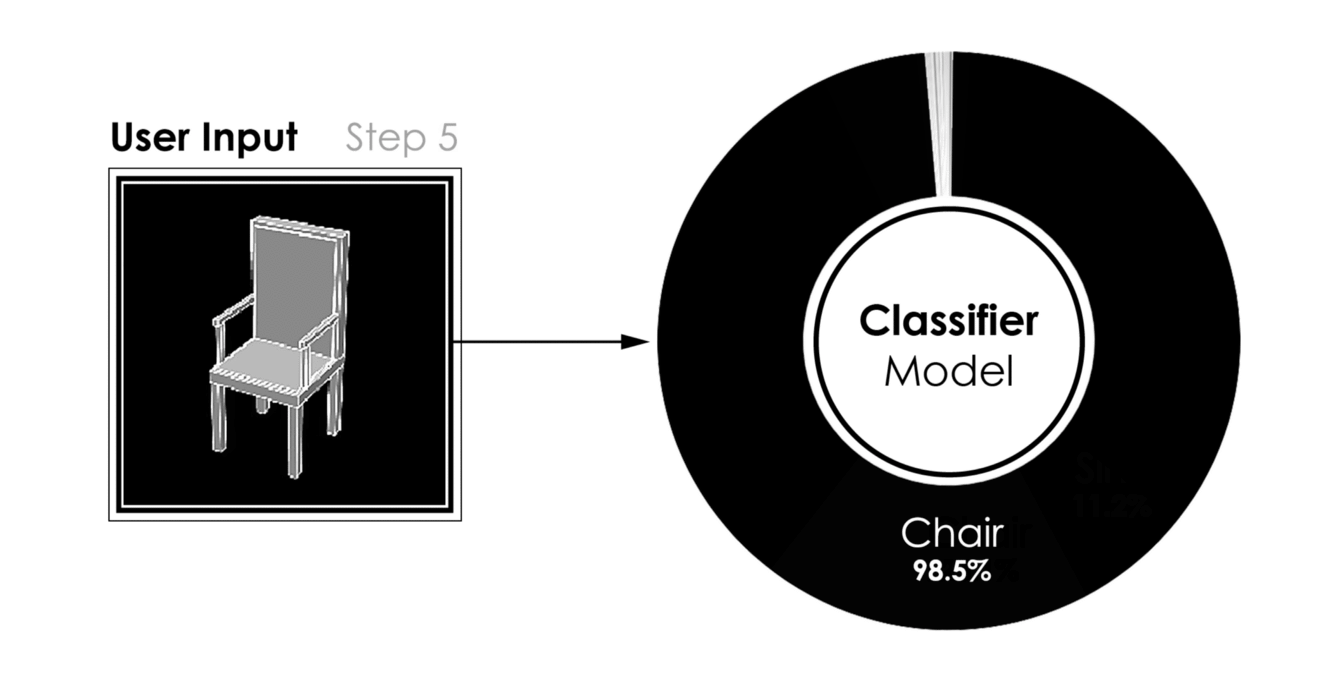 建模过程中的分类[/caption]
建模过程中的分类[/caption]
关于Github的更多信息。
[caption id="attachment_42185" align="aligncenter" width="660"]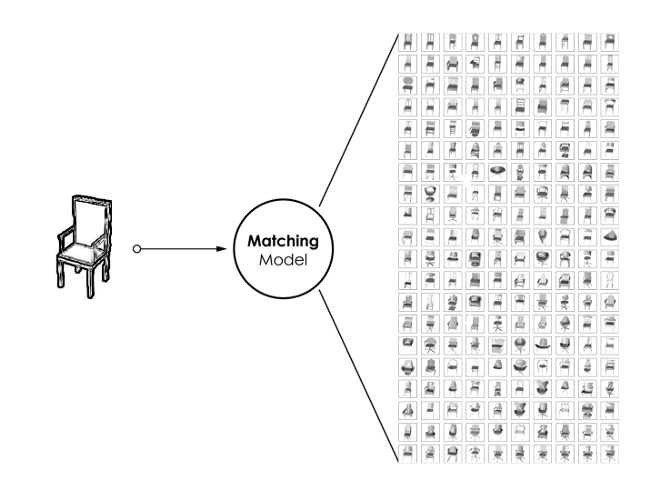 匹配:通过卷积模型查找数据库之间的最佳匹配[/caption]
匹配:通过卷积模型查找数据库之间的最佳匹配[/caption]
在第二步中,我们的模型尝试在大量的3D模型数据库中找到理想的匹配。如果分类模型有助于缩小搜索范围,则匹配模型将给定类中的所有三维模型从“最相似”排列到“最不相似”。
关于Github的更多信息。
我们的匹配模型是另一个卷积神经网络,在给定类对象的图像上进行训练,并在相同的对象上进行验证,从不同的角度进行观察。为了测试,我们的输入将是一个用户建模的3D对象的图像,输出将是我们数据库中已识别类的所有对象的列表,按相似性的顺序排列。
当我们为每个类训练匹配模型时,我们现在能够将分类模型和匹配模型嵌套为一个单独的管道。我们现在可以处理一个输入图像,它将首先被分类,最后与数据库中存在的类似对象相匹配。同时,我们的模型输出一些预测置信度,以帮助我们判断原始模型与实际匹配之间的相似性有多强。
已经为7个不同类的对象运行了测试,如下图所示。
关于Github的更多信息。
[caption id="attachment_42186" align="aligncenter" width="2600"]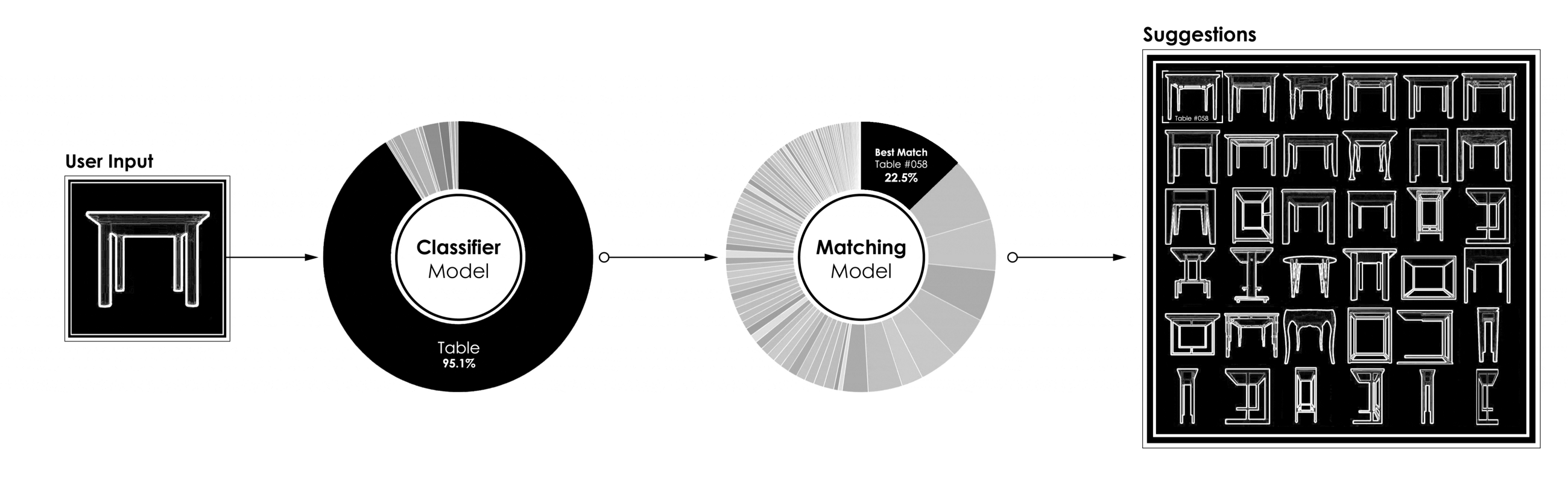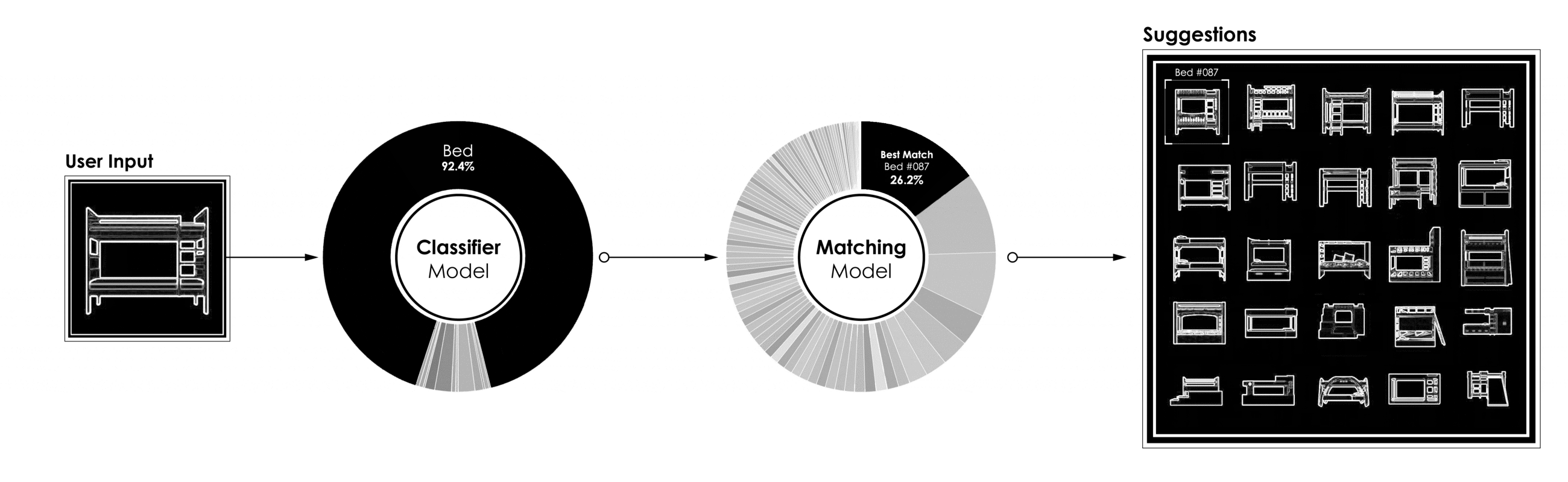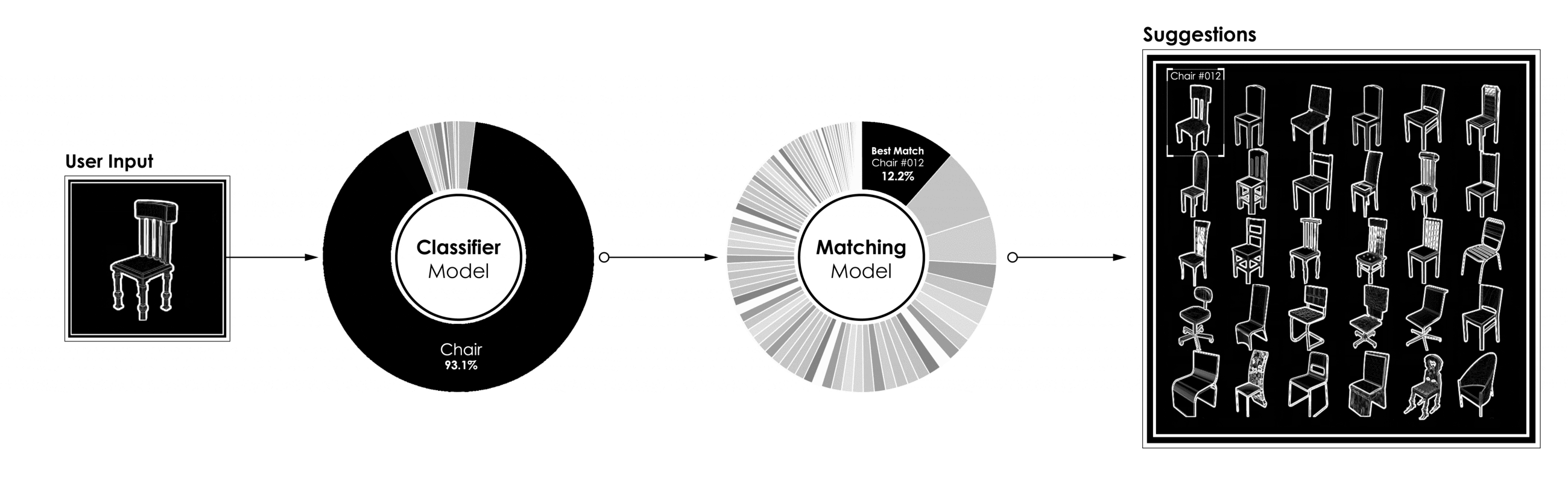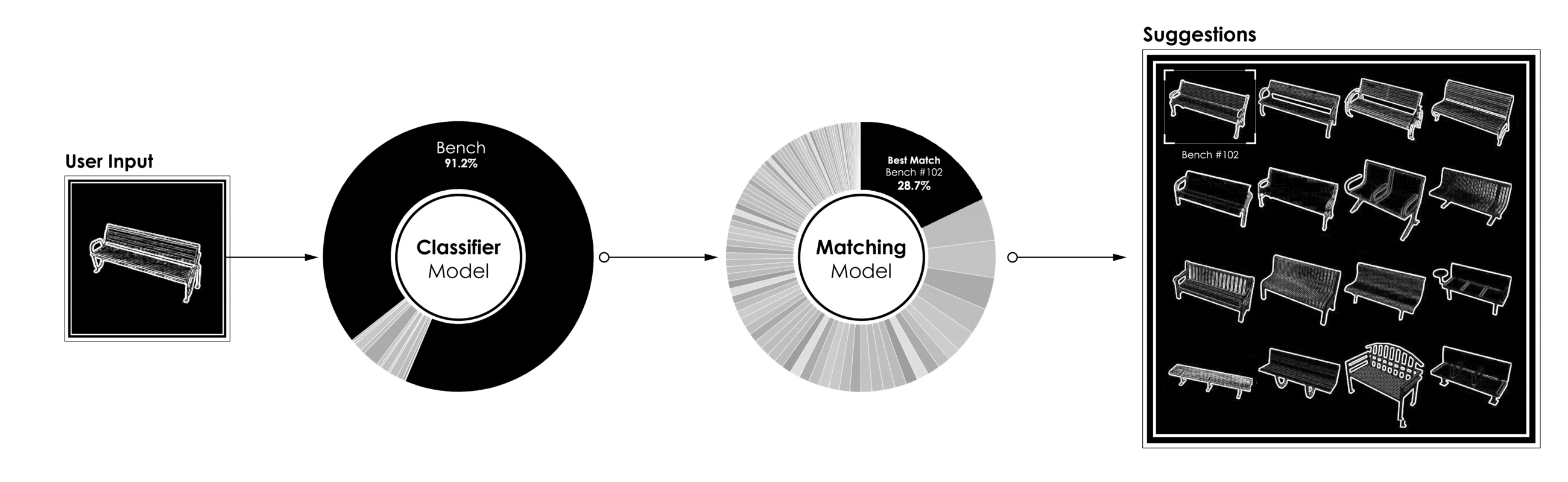 功能分类匹配模型的完整管道[/caption]
功能分类匹配模型的完整管道[/caption]
首先,我们鼓励在我们的行业内进一步发展和改进上述理念。这一领域已经做了很多工作,并为相邻领域带来了解决方案。让这些技术渗透到我们的学科中,将真正有利于我们的日常建筑实践。此外,像我们一样嵌套CNN模型只是一个更大概念的可能版本:3D形状识别和建议。可以部署其他方法和模型,使架构师和设计人员能够获得公开可用数据的广度和丰富性。
实际上,除了本文开发的简单管道之外,还有一个更基本的概念:架构形式的限定。我曾经的一篇文章所述,能够构建包含现有形状的异质性和复杂性的框架,将很快对我们的学科至关重要。随着数字数据量的增加和在大型公共存储库中的汇集,我们对这些共享知识的访问将只取决于查询的智能程度。正如我们在这里演示的,我们可以在一定程度上依赖于机器学习来找到一种共同的语言,从而能够比较各种复杂的形状。
在一个更基本的层面上,这项工作仅仅展示了暗示设计的潜力。通过在创意过程中为设计师带来相关的替代品,我们有机会扩大他们的工作范围。当这种方法扩展到比简单的离散对象更大的分类法时,它最终将把被动的集体知识变成一种积极的灵感来源。
[1]多视图卷积神经网络用于三维形状识别,Hang Su, Subhransu Maji, Evangelos Kalogerakis, Erik learreid - miller,马萨诸塞大学,Amherst |链接
[2] VoxNet:一个用于实时对象识别的三维卷积神经网络,Daniel Maturana和Sebastian Scherer |链接
[3]重新混合和重新采样三维对象在设计中使用体积表示和机器学习,NJ Namju Lee,哈佛GSD, 2017年|链接
传送门:机器学习为CAD插上一双翅膀(上)
二.模型定义
我们在这个项目中的方法是识别用户正在绘制的对象,并通过简单地使用对象的形状作为代理来提供类似的对象。
简而言之,我们在这里设计的模型涉及两个主要任务:
(1)分类:识别用户正在绘制的对象类型,即为任何给定的图像输入找到适当的标签(“椅子”、“长椅”、“床”等),并结合预测置信度得分。
(2)匹配:在三维对象的数据库中,查询一些最符合用户建模输入方面的形状,即返回数据库中的对象列表,从最相似到最不相似排序。
[caption id="attachment_42178" align="aligncenter" width="1320"]
典型管道[/caption]如上图所示,通过嵌套两个不同级别的模型(分类器和“匹配器”),我们可能能够执行这两步过程。每个模型将接受3D对象图像的训练,然后将在用户建模的对象图像上进行测试。
A.数据来源和生成
第一步是生成一个数据库来训练我们的模型。由于我们的方法论是要共享的,所以我们希望在这里详细说明这一关键步骤,并共享我们为实现这一点而使用和构建的资源。
我们首先从现有的公共3D对象仓库中提取信息,例如:
ShapeNet |链接
谷歌三维仓库|链接
ModelNet |链接
从ShapeNet数据库中,我们可以下载多达2.330个标记为3D models的14个特定类(下图)。
[caption id="attachment_42179" align="aligncenter" width="1320"]
训练集的类[/caption]然后,我们使用Rhinoceros和Grasshopper编写脚本,创建一个工具来创建训练集和验证集。在这个脚本中,一个摄像机在每个连续的对象周围旋转,以特定的角度拍摄对象,并将JPG图像保存在给定的目录中。
下图显示了一个典型的相机路径(左侧)和所捕获的结果图像(右侧)。
[caption id="attachment_42180" align="aligncenter" width="1320"]
图像捕获路径,并生成图像[/caption]对于每个对象,我们使用30张图像进行训练,10张图像进行验证,同时保留白色背景/中性背景。
用于捕获图像的数据生成器可在以下地址下载。
我们最终获得了一个带标签的图像库,每个类对应10个对象,总共有14个不同的类。这里显示了一个子集,如下图所示。
[caption id="attachment_42181" align="aligncenter" width="2600"]
训练集的子集[/caption]B.分类
一旦我们的数据集准备好了,我们的目标就是训练我们的第一个模型,分类器,在大量的3D对象的图像上进行训练,同时验证它在属于类似类的其他对象的图像集上的性能。
迭代
几个参数严重影响经过训练的分类器的精度:
- 培训和验证集的大小
- 班级数量
- 每个类的对象数
- 每个对象的图像数
- 两组图像的大小
- 相机在物体周围的捕获路径
此时,我们在不同的选项之间进行迭代,目的是提高验证集上模型的整体准确性。由于资源有限,我们不能从头开始训练。使用一些转移学习是很方便的,因为它可以提高我们的模型的准确性,同时绕过几天的训练。我们在模型的第一层添加了一个VGG16预训练模型,这将使我们的准确率提高32%。
这个训练过程的一个关键要点是,摄像机的路径实际上会显著影响结果的准确性。在我们尝试过的许多版本中,我们在下面的图中演示了两种不同相机路径(圆形和球形)的比较性能。
[caption id="attachment_42182" align="aligncenter" width="2600"]
不同图像采集技术下的训练性能[/caption]结果
最后,我们用200*200像素的图像作为分类器,球形摄像机路径,每个对象30个图像用于训练,10个图像用于验证。经过30个周期的验证,我们最终得到了93%的验证集。现在看来,以下参数对整体模型的性能影响很大:
增加图像大小可以提高精度。在我们的机器上,速度和精度之间的平衡在200x200px左右。
相机的拍摄路径也直接影响着拍摄的准确性。通过使用球形捕获路径,而不是圆形路径(请参见图上图),我们显著地提高了模型性能:在更少的周期之后,精确度要高得多。使用球面路径似乎是一种更全面的方法来捕捉给定形状的外观。
上图显示了四个不同用户输入的分类器的典型结果。
[caption id="attachment_42183" align="aligncenter" width="1320"]
分类器模型的结果,用户输入(左)到预测类(右)[/caption]- 更有趣的是,在给定用户的三维建模过程中运行的相同模型的性能。当一个对象被建模时,只要很少的曲面就足以将分类器推向正确的方向。因此,在建模过程的早期,我们能够识别建模对象的类。作为回报,我们可以向用户推荐数据库中的模型,如果用户在建议中找到匹配项,可能会缩短3D建模时间。下图显示了分类器在建模过程的五个不同步骤中的结果。
[caption id="attachment_42184" align="aligncenter" width="1320"]
建模过程中的分类[/caption]关于Github的更多信息。
C.匹配
[caption id="attachment_42185" align="aligncenter" width="660"]
匹配:通过卷积模型查找数据库之间的最佳匹配[/caption]在第二步中,我们的模型尝试在大量的3D模型数据库中找到理想的匹配。如果分类模型有助于缩小搜索范围,则匹配模型将给定类中的所有三维模型从“最相似”排列到“最不相似”。
关于Github的更多信息。
我们的匹配模型是另一个卷积神经网络,在给定类对象的图像上进行训练,并在相同的对象上进行验证,从不同的角度进行观察。为了测试,我们的输入将是一个用户建模的3D对象的图像,输出将是我们数据库中已识别类的所有对象的列表,按相似性的顺序排列。
结果
当我们为每个类训练匹配模型时,我们现在能够将分类模型和匹配模型嵌套为一个单独的管道。我们现在可以处理一个输入图像,它将首先被分类,最后与数据库中存在的类似对象相匹配。同时,我们的模型输出一些预测置信度,以帮助我们判断原始模型与实际匹配之间的相似性有多强。
已经为7个不同类的对象运行了测试,如下图所示。
关于Github的更多信息。
[caption id="attachment_42186" align="aligncenter" width="2600"]
功能分类匹配模型的完整管道[/caption]三、结论
首先,我们鼓励在我们的行业内进一步发展和改进上述理念。这一领域已经做了很多工作,并为相邻领域带来了解决方案。让这些技术渗透到我们的学科中,将真正有利于我们的日常建筑实践。此外,像我们一样嵌套CNN模型只是一个更大概念的可能版本:3D形状识别和建议。可以部署其他方法和模型,使架构师和设计人员能够获得公开可用数据的广度和丰富性。
实际上,除了本文开发的简单管道之外,还有一个更基本的概念:架构形式的限定。我曾经的一篇文章所述,能够构建包含现有形状的异质性和复杂性的框架,将很快对我们的学科至关重要。随着数字数据量的增加和在大型公共存储库中的汇集,我们对这些共享知识的访问将只取决于查询的智能程度。正如我们在这里演示的,我们可以在一定程度上依赖于机器学习来找到一种共同的语言,从而能够比较各种复杂的形状。
在一个更基本的层面上,这项工作仅仅展示了暗示设计的潜力。通过在创意过程中为设计师带来相关的替代品,我们有机会扩大他们的工作范围。当这种方法扩展到比简单的离散对象更大的分类法时,它最终将把被动的集体知识变成一种积极的灵感来源。
参考文献
[1]多视图卷积神经网络用于三维形状识别,Hang Su, Subhransu Maji, Evangelos Kalogerakis, Erik learreid - miller,马萨诸塞大学,Amherst |链接
[2] VoxNet:一个用于实时对象识别的三维卷积神经网络,Daniel Maturana和Sebastian Scherer |链接
[3]重新混合和重新采样三维对象在设计中使用体积表示和机器学习,NJ Namju Lee,哈佛GSD, 2017年|链接

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
自然梯度优化详解








广告


写评论取消
回复取消