











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






XGBoost入门指南
2019年06月05日 由 sunlei 发表
258427
0
这篇文章将出现树…很多很多的树…

XGBoost是一个开放源码库,提供了梯度增强决策树的高性能实现。一个底层的C++代码库和一个Python接口组合在一起,形成了一个非常强大但易于实现的软件包。
XGBoost的性能不是开玩笑的——它已经成为赢得Kaggle许多比赛的首选库。它的梯度增强实现是首屈一指的,而且随着库不断的获得好评,它将还会有更多的实现。
在本文中,我们将介绍XGBoost库的基础知识。我们将从梯度增强实际工作原理的实际解释开始,然后通过一个Python示例说明XGBoost是如何使它变得如此快速和容易实现的。
对于常规的机器学习模型,比如决策树,我们只需在数据集中训练一个模型,并将其用于预测。我们可能会修改一些参数或增加数据,但最终我们仍然使用单个模型。即使我们构建一个集成,所有的模型都是单独训练并应用于我们的数据中。
另一方面,提升需要一个更迭代的方法。从技术上讲,它仍然是一种集成技术,因为许多模型被组合在一起来执行最后一个模型,但是采用了更聪明的方法。
不是把所有的模型都单独训练,而是不断地改进训练模型,每个新模型都经过训练,以纠正前一个模型所犯的错误。模型是按顺序添加的,直到不能进行进一步的改进为止。
这种迭代方法的优点是所添加的新模型侧重于纠正由其他模型引起的错误。在一个标准的集成方法中,模型是单独训练的,所有的模型最终可能会犯同样的错误!
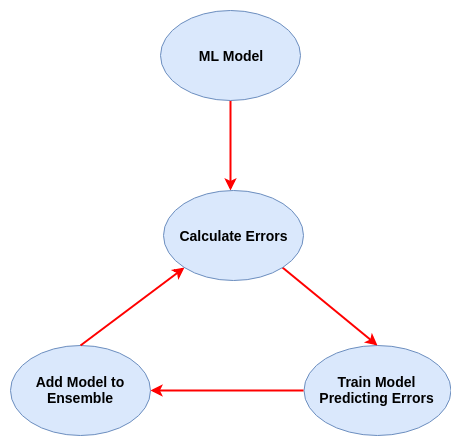
梯度提升是一种新的模型被训练来预测先前模型的残差(即误差)的方法。我在下面的图表中概述了这种方法。
让我们开始使用这个庞大的库——XGBoost。
我们要做的第一件事是安装库,这是最容易通过pip完成的。在Python虚拟环境中这样做也更安全。
在本教程的其余部分中,我们将使用iris flowers数据集。我们可以使用Scikit Learn在Python中加载它。同时,我们还将导入新安装的XGBoost库。
让我们来设置所有的数据。我们将首先创建一个列车测试拆分,以便了解XGBoost的性能。这次我们将采取80%-20%的比例。
为了使XGBoost能够使用我们的数据,我们需要将其转换为XGBoost能够处理的特定格式。这种格式称为DMatrix。这是一个非常简单的线性数字数组的数据转换为DMatrix格式:
既然我们的数据都加载了,我们就可以定义梯度升级集成的参数。我们在下面设置了一些最重要的项目,以帮助我们开始工作。对于更复杂的任务和模型,可以在XGBoost官方网站上获得完整的可能参数列表。
最简单的参数是max_depth(正在训练的决策树的最大深度)、objective(正在使用的损失函数)和num_class(数据集中类的数量)。eta算法需要特别注意。
根据我们的理论,梯度提升涉及到创建决策树并将其依次添加到一个集合模型中。创建新的树来纠正现有集合预测中的残余误差。
由于合奏的本质,即将多个模型组合在一起,形成一个本质上非常大、复杂的合奏,使得这种技术容易过度拟合。ETA参数使我们有机会防止这种过度拟合。
可以更直观地将eta视为学习率。eta不是简单地将新树的预测添加到整个权重中,而是将其与正在添加的残差相乘,以减少它们的权重。这有效地降低了整个模型的复杂性。
通常在0.1到0.3范围内具有较小的值。这些残差的较小权重仍将有助于我们培养一个强大的模型,但不会让该模型陷入更可能发生过度拟合的深层复杂性。
我们最终可以训练我们的模型,就像我们用Scikit Learn做的那样:
现在让我们运行一个评测。同样,这个过程与Scikit学习中的培训模型非常相似:
太棒了!
如果您已经遵循了以上所有步骤,那么您应该获得至少90%的准确率!
以上只是对XGBoost的基础知识的总结。但是还有一些更酷的功能可以帮助你充分利用你的模型。
只有在你有时间的时候才在大数据集上做这个——做一个网格搜索实际上是多次训练一个决策树的集合!
一旦你的XGBoost模型被训练好,你可以将人类可读的描述转储到文本文件中:
收工~
XGBoost是一个开放源码库,提供了梯度增强决策树的高性能实现。一个底层的C++代码库和一个Python接口组合在一起,形成了一个非常强大但易于实现的软件包。
XGBoost的性能不是开玩笑的——它已经成为赢得Kaggle许多比赛的首选库。它的梯度增强实现是首屈一指的,而且随着库不断的获得好评,它将还会有更多的实现。
在本文中,我们将介绍XGBoost库的基础知识。我们将从梯度增强实际工作原理的实际解释开始,然后通过一个Python示例说明XGBoost是如何使它变得如此快速和容易实现的。
提升树
对于常规的机器学习模型,比如决策树,我们只需在数据集中训练一个模型,并将其用于预测。我们可能会修改一些参数或增加数据,但最终我们仍然使用单个模型。即使我们构建一个集成,所有的模型都是单独训练并应用于我们的数据中。
另一方面,提升需要一个更迭代的方法。从技术上讲,它仍然是一种集成技术,因为许多模型被组合在一起来执行最后一个模型,但是采用了更聪明的方法。
不是把所有的模型都单独训练,而是不断地改进训练模型,每个新模型都经过训练,以纠正前一个模型所犯的错误。模型是按顺序添加的,直到不能进行进一步的改进为止。
这种迭代方法的优点是所添加的新模型侧重于纠正由其他模型引起的错误。在一个标准的集成方法中,模型是单独训练的,所有的模型最终可能会犯同样的错误!
梯度提升是一种新的模型被训练来预测先前模型的残差(即误差)的方法。我在下面的图表中概述了这种方法。
XGBoost入门
让我们开始使用这个庞大的库——XGBoost。
我们要做的第一件事是安装库,这是最容易通过pip完成的。在Python虚拟环境中这样做也更安全。
pip install xgboost
使用XGBoost设置数据
在本教程的其余部分中,我们将使用iris flowers数据集。我们可以使用Scikit Learn在Python中加载它。同时,我们还将导入新安装的XGBoost库。
from sklearn import datasets
import xgboost as xgb
iris = datasets.load_iris()
X = iris.data
y = iris.target
让我们来设置所有的数据。我们将首先创建一个列车测试拆分,以便了解XGBoost的性能。这次我们将采取80%-20%的比例。
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2)
为了使XGBoost能够使用我们的数据,我们需要将其转换为XGBoost能够处理的特定格式。这种格式称为DMatrix。这是一个非常简单的线性数字数组的数据转换为DMatrix格式:
D_train = xgb.DMatrix(X_train, label=Y_train)
D_test = xgb.DMatrix(X_test, label=Y_test)
定义XGBoost模型
既然我们的数据都加载了,我们就可以定义梯度升级集成的参数。我们在下面设置了一些最重要的项目,以帮助我们开始工作。对于更复杂的任务和模型,可以在XGBoost官方网站上获得完整的可能参数列表。
param = {
'eta': 0.3,
'max_depth': 3,
'objective': 'multi:softprob',
'num_class': 3}
steps = 20 # The number of training iterations最简单的参数是max_depth(正在训练的决策树的最大深度)、objective(正在使用的损失函数)和num_class(数据集中类的数量)。eta算法需要特别注意。
根据我们的理论,梯度提升涉及到创建决策树并将其依次添加到一个集合模型中。创建新的树来纠正现有集合预测中的残余误差。
由于合奏的本质,即将多个模型组合在一起,形成一个本质上非常大、复杂的合奏,使得这种技术容易过度拟合。ETA参数使我们有机会防止这种过度拟合。
可以更直观地将eta视为学习率。eta不是简单地将新树的预测添加到整个权重中,而是将其与正在添加的残差相乘,以减少它们的权重。这有效地降低了整个模型的复杂性。
通常在0.1到0.3范围内具有较小的值。这些残差的较小权重仍将有助于我们培养一个强大的模型,但不会让该模型陷入更可能发生过度拟合的深层复杂性。
培训和测试
我们最终可以训练我们的模型,就像我们用Scikit Learn做的那样:
model = xgb.train(param, D_train, steps)
现在让我们运行一个评测。同样,这个过程与Scikit学习中的培训模型非常相似:
import numpy as np
from sklearn.metrics import precision_score, recall_score, accuracy_score
preds = model.predict(D_test)
best_preds = np.asarray([np.argmax(line) for line in preds])
print("Precision = {}".format(precision_score(Y_test, best_preds, average='macro')))
print("Recall = {}".format(recall_score(Y_test, best_preds, average='macro')))
print("Accuracy = {}".format(accuracy_score(Y_test, best_preds)))
太棒了!
如果您已经遵循了以上所有步骤,那么您应该获得至少90%的准确率!
XGBoost的进一步探索
以上只是对XGBoost的基础知识的总结。但是还有一些更酷的功能可以帮助你充分利用你的模型。
- Gamma参数也有助于控制过拟合。它指定了在树的叶节点上进行进一步分区所需的最小损失减少量。也就是说,如果创建一个新节点不能减少一定数量的损失,那么我们就根本不会创建它。
- Booster参数允许您设置构建集成时将使用的模型类型。默认值是gbtree,它构建一组决策树。如果您的数据不太复杂,您可以使用更快更简单的gblinear选项来构建一组线性模型。
- 设置任何ML模型的最优超参数都是一个挑战。那么为什么不让Scikit为你学习呢?我们可以很容易地将Scikit Learn的网格搜索与XGBoost分类器结合起来:
from sklearn.model_selection import GridSearchCV
clf = xgb.XGBClassifier()
parameters = {
"eta" : [0.05, 0.10, 0.15, 0.20, 0.25, 0.30 ] ,
"max_depth" : [ 3, 4, 5, 6, 8, 10, 12, 15],
"min_child_weight" : [ 1, 3, 5, 7 ],
"gamma" : [ 0.0, 0.1, 0.2 , 0.3, 0.4 ],
"colsample_bytree" : [ 0.3, 0.4, 0.5 , 0.7 ]
}
grid = GridSearchCV(clf,
parameters, n_jobs=4,
scoring="neg_log_loss",
cv=3)
grid.fit(X_train, Y_train)
只有在你有时间的时候才在大数据集上做这个——做一个网格搜索实际上是多次训练一个决策树的集合!
一旦你的XGBoost模型被训练好,你可以将人类可读的描述转储到文本文件中:
model.dump_model('dump.raw.txt')收工~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消