












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






研究人员提高AI工具识别小说人名的能力,准确度达到90%
2019年05月01日 由 老张 发表
741526
0
 AI工具识别小说文本的能力越来越出色,现在它们也可以用来识别小说中的人名。
AI工具识别小说文本的能力越来越出色,现在它们也可以用来识别小说中的人名。自然语言处理(NLP)工具通常用于许多日常应用程序,如Siri,但这些技术的有效性尚未被完全理解。来自阿姆斯特丹自由大学、荷兰皇家学院人文科学研究所的研究人员用了四种工具对40部流行的小说进行了全面评估,其中包括《权力的游戏》。
他们找到了解决方案,提高了工具在小说中识别名字的能力,准确度从7%提升到90%。
对于这些工具来说,识别名称和文本类型尤其具有挑战性。此外,他们从小说中提取社交网络来探索故事结构的差异。这些见解可以帮助这些技术更有效地对抗类型差异,例如,它可以帮助那些想要分析大型数据集(如《巴拿马文件》)的记者更好地利用这项技术。
许多NLP工具都基于机器学习,例如,为了识别文本中的名字,它提供了许多报纸文章中人类精心标记的名字。然后,该程序的任务是根据上下文(例如,名字前面有Mr)或单词的样式(例如,名字通常以英文大写字母开头)来学习的。
现在,当把这种以报纸为训练对象的系统应用到小说中时,问题在于小说作者在叙述方面比那些需要坚持事实的记者有更多的自由。小说作者可以随意编造名字,例如Tywin或R'hllor,或者直接使用字典中的描述性字符名称,例如Gray Worm。这些名字与一般名字不同,因此NLP系统很难在文本中识别它们。
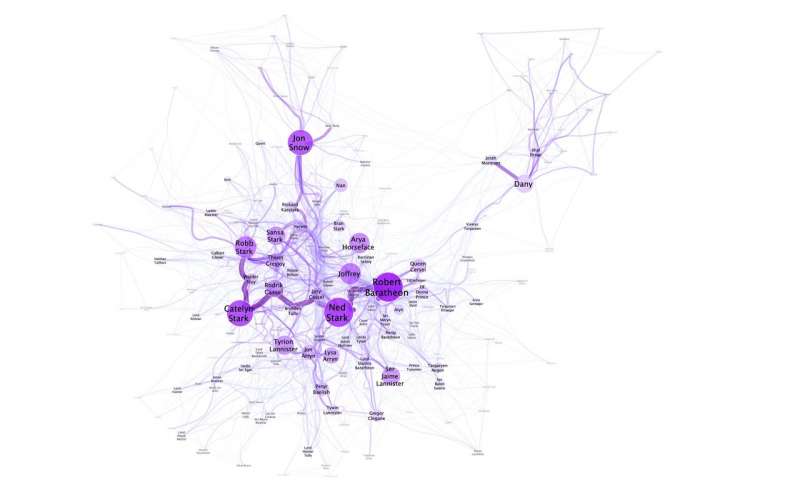
网络可视化显示,在权力的游戏中,Dany / Daenerys与其他主角并不亲密
由Niels Dekker(Trifork BV),Tobias Kuhn(阿姆斯特丹自由大学)和Marieke van Erp(KNAW Humanities Cluster)进行的实验也突出了语言的灵活性以及名字在故事背景的重要性。
例如,可以将Daenerys Targaryen称为Daenerys和“她”,但她也被称为Dany,Daenerys Stormborn,龙妈,Khaleesi,Unburnt或Mhysa。为权力的游戏创建的社交网显示,她的朋友叫她Dany,而她的全名Daenerys只被她的敌人(在她不在场时)使用。
研究人员表示,接下来他们会更多地关注NLP工具的性能,并且在计算机完全理解文本之前仍有大量工作要做。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消