











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在深度学习中必须了解的信息论概念
2019年03月30日 由 老张 发表
53818
0
 信息论是一个重要的领域,它对深度学习和人工智能作出了重大贡献,但很多人对此并不了解。信息论可以被看作是深度学习的基本组成部分:微积分、概率论和统计学的复杂融合。一些来自信息论或相关领域的人工智能概念的例子:
信息论是一个重要的领域,它对深度学习和人工智能作出了重大贡献,但很多人对此并不了解。信息论可以被看作是深度学习的基本组成部分:微积分、概率论和统计学的复杂融合。一些来自信息论或相关领域的人工智能概念的例子:- 常用的交叉熵损失函数
- 根据最大信息增益构建决策树
- 维特比算法广泛应用于NLP和语音
- 编码器-解码器的概念广泛用于机器翻译RNN和各种其他类型的模型
信息论简史
在20世纪初期,科学家和工程师们努力解决这样的问题:“如何量化信息?有没有一种分析方法或数学方法可以告诉我们信息的内容?”例如,考虑以下两句话:
- 布鲁诺是一条狗。
- 布鲁诺是一条大棕狗。
第二句话给了我们更多的信息,因为它还告诉布鲁诺除了是“狗”之外还是“大的”和“棕色的”。我们如何量化两个句子之间的差异?我们能否有一个数学测量方法告诉我们第二句话与第一句话相比多了多少信息?
科学家们一直在努力解决这些问题。语义,域和数据形式只会增加问题的复杂性。数学家和工程师克劳德·香农提出了“熵”的概念,它永远改变了我们的世界,这标志着数字信息时代的开始。

香农提出“数据的语义方面是无关紧要的”,数据的性质和含义在信息内容方面并不重要。相反,他根据概率分布和不确定性来量化信息。香农还引入了“bit”这个词,这一革命性的想法不仅奠定了信息论的基础,而且为人工智能等领域的进步开辟了新的途径。
下面将讨论深度学习和数据科学中四种流行的,广泛使用的和必须已知的信息论概念:
熵
也称为信息熵或香农熵。熵给出了实验中不确定性的度量。
让我们考虑两个实验:
- 抛出一枚无偏硬币(P(H)= 0.5)并观察它的输出,假设H
- 抛出一枚有偏硬币(P(H)= 0.99)并观察其输出,假设H
如果我们比较两个实验,与例1相比,例2更容易预测结果。因此,我们可以说例1本质上比例2更不确定或不可预测。实验中的这种不确定性是使用熵测量的。
因此,如果实验中存在更多固有的不确定性,那么它的熵更大。或者说实验越不可预测熵更大。实验的概率分布用于计算熵。
一个完全可预测的确定性实验,即投掷P(H)= 1的硬币的熵为零。一个完全随机的实验,比如滚动无偏骰子,是最不可预测的,具有最大的不确定性,在这些实验中熵最大。
另一种观察熵的方法是我们观察随机实验结果时获得的平均信息。将实验结果获得的信息定义为该结果发生概率的函数。结果越罕见,从观察中获得的信息就越多。
例如,在确定性实验中,我们总是知道结果,因此通过观察结果没有获得新信息,因此熵为零。
对于离散随机变量X,可能的结果(状态)x_1,...,x_n,熵(以位为单位)定义为:
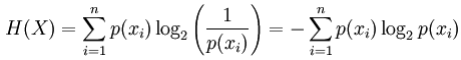
其中p(x_i)是X的第i个结果的概率。
应用
熵用于自动决策树构造。在树构建的每个步骤中,使用熵标准来完成特征选择。
基于最大熵原理的模型选择,从竞争模型中得出熵最大的模型为最佳模型。
交叉熵
交叉熵用于比较两个概率分布。它告诉我们两个分布有多相似。
在相同的结果集上定义的两个概率分布p和q之间的交叉熵由下式给出:
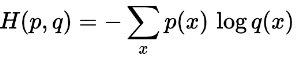
应用
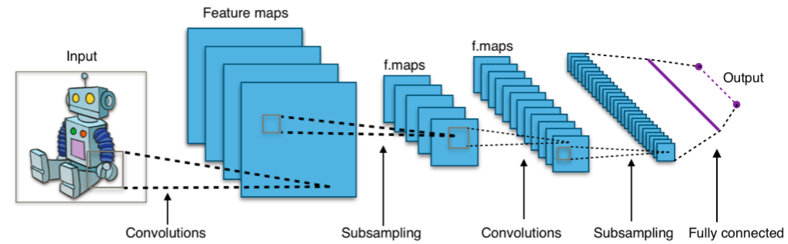
基于卷积神经网络的分类器通常使用softmax层作为最后一层,并使用交叉熵损失函数进行训练。
交叉熵损失函数广泛用于逻辑回归等分类模型。随着预测偏离真实输出,交叉熵损失函数增大。
在诸如卷积神经网络的深度学习架构中,最终输出的softmax层经常使用交叉熵损失函数。
交互信息
交互信息是两种概率分布或随机变量之间相互依赖性的度量。它告诉我们一个变量由另一个变量携带了多少信息。
交互信息捕获随机变量之间的依赖性,比一般的相关系数更具广义性,后者只捕获线性关系。
两个离散随机变量X和Y的交互信息定义为:
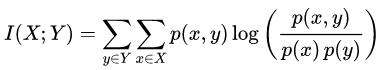
其中p(x,y)是X和Y的联合概率分布,p(x)和p(y)分别是X和Y的边际概率分布。
应用
在贝叶斯网络中,可以使用交互信息来确定变量之间的关系结构。
特征选择:使用交互信息,而不是使用相关性。相关性仅捕获线性依赖性并忽略非线性依赖性,但交互信息不会。零的交互独立性保证随机变量是独立的,但零相关不是。
在贝叶斯网络中,交互信息用于学习随机变量之间的关系结构,并定义这些关系的强度。
Kullback Leibler(KL)散度
也称为相对熵。KL散度用于比较两个概率分布。
KL散度是找到两个概率分布之间相似性的另一种方法。它衡量一个分布与另一个分布的差异。
假设我们有一些数据,它的真实分布是P。但是我们不知道P,所以我们选择一个新的分布Q来近似这个数据。由于Q只是一个近似值,它无法像P那样准确地逼近数据,会造成一些信息的丢失。这个信息损失由KL散度给出。
P和Q之间的KL散度告诉我们,当我们试图用P和Q来近似数据时,我们损失了多少信息。
一个概率分布Q与另一个概率分布P的KL散度定义为:
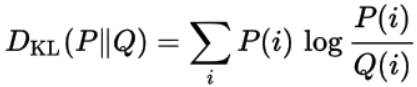
应用
KL散度通常用于无监督机器学习技术中的变分自编码器。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
深度学习词汇表(一)
下一篇
白话机器学习算法 Part 1








广告


写评论取消
回复取消