












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Maluuba:转移学习机器阅读理解
2018年01月23日 由 荟荟 发表
47932
0
通过晓东他,首席研究员,微软研究
对于人类来说,阅读理解是一项基本任务,每天都要进行。早在小学,我们就可以阅读一篇文章,并回答有关其主要思想和细节的问题。
但对于人工智能而言,完全阅读理解仍然是一个难以实现的目标 - 但如果我们要衡量和实现一般情报AI,这是必要的目标。在实践中,阅读理解对于许多现实场景是必要的,包括客户支持,推荐,问答,对话和客户关系管理。它具有令人难以置信的潜力,例如帮助医生在数千份文件中快速查找重要信息,节省他们的时间,以获得更高价值和可能挽救生命的工作。
因此,能够执行机器读数理解(MRC)的建筑机器非常令人感兴趣。在搜索应用程序中,机器理解将提供精确的答案,而不是在冗长的网页中包含答案的URL。此外,机器理解模型可以理解嵌入在通常涵盖狭窄和特定领域的文章中的特定知识,其中算法所依赖的搜索数据是稀疏的。
微软专注于机器阅读,目前正在引领该领域的竞争。微软的多个项目,包括机器理解的深度学习,也将目光投向了MRC。尽管取得了很大进展,但直到最近才忽略了一个关键问题 - 如何为新域构建MRC系统?
最近,来自斯坦福大学的微软研究AI的几位研究人员,包括Po-Sen Huang, Xiaodong He和实习生David Golub开发了一种用于MRC的转移学习算法来解决这个问题。他们的工作将在EMNLP 2017上进行,这是一个顶级的自然语言处理会议。这是开发可扩展解决方案以将MRC扩展到更广泛领域的关键一步。
这是我们为实现我们在微软的更广泛目标所取得的进展的一个例子:创建具有更复杂和细微差别功能的技术。“我们不只是要构建一堆算法来解决理论问题。我们正在使用它们来解决实际问题并在真实数据上进行测试,“ Rangan Majumder在机器阅读博客中表示。
目前,大多数最先进的机器阅读系统都建立在数据示例的端对端监督培训数据培训上,不仅包含文章,还包含有关文章和相应答案的手动标记问题。通过这些示例,基于深度学习的MRC模型学习理解问题并从文章中推断出答案,其中涉及推理和推理的多个步骤。
但是,对于许多域或垂直行业,此监督的培训数据不存在。例如,如果我们需要建立一个新的机器阅读系统来帮助医生找到有关新疾病的重要信息,可能会有许多文件可用,但是缺乏关于文章的手动标记问题以及相应的答案。需要为每种不同的疾病建立一个单独的MRC系统,并且文献量迅速增加,这一挑战被放大了。因此,弄清楚如何将MRC系统转移到没有手动标记的问题和答案的新域,这是至关重要的,但是有一大堆文件。
微软研究人员开发了一种名为“两阶段合成网络”的新型模型,即SynNet,以满足这一关键需求。在这种方法中,基于一个领域中可用的监督数据,SynNet首先学习识别文章中潜在“兴趣”的一般模式。这些是关键知识点,命名实体或语义概念,通常是人们可能要求的答案。然后,在第二阶段,模型学习在文章的上下文中围绕这些潜在答案形成自然语言问题。经过培训,SynNet可以应用于新域,读取新域中的文档,然后针对这些文档生成伪问题和答案。然后,它形成必要的培训数据,以培训新域的MRC系统,这可能是一种新疾病,新公司的员工手册或新产品手册。
之前已经探索过生成合成数据以增加不足的训练数据的想法。例如,对于目标翻译任务,Rico Sennrich及其同事在他们的论文中提出了一种方法,用于生成合成翻译,给出真实句子以重新定义现有的机器翻译系统。但是,与机器翻译不同,对于像MRC这样的任务,我们需要综合一篇文章的问题和答案。此外,虽然问题是语法上的自然语言句子,但答案主要是段落中的一个突出的语义概念,例如命名实体,动作或数字。由于答案具有与问题不同的语言结构,因此将答案和问题视为两种不同类型的数据可能更为合适。
在我们的方法中,我们将生成问答对的过程分解为两个步骤:以段落和问题生成为条件的答案生成以段落和答案为条件。我们首先生成答案,因为答案通常是关键的语义概念,而问题可以被视为一个完整的句子,用于查询概念。
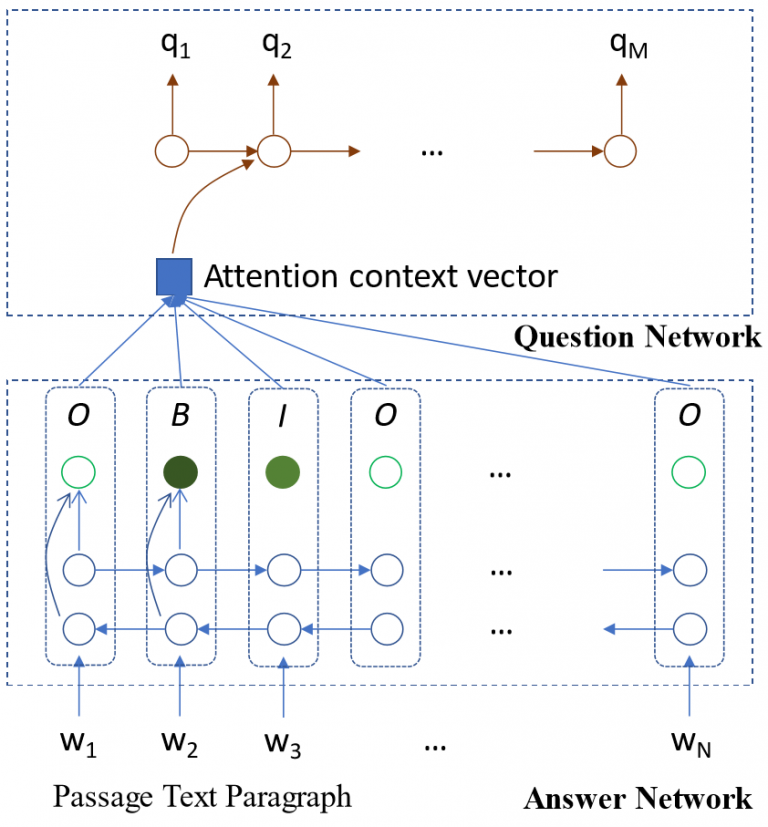
生成的问题和文章答案的两个例子如下所示:
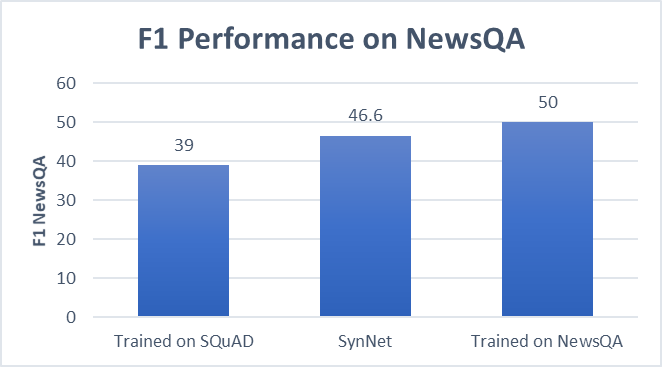
使用SynNet,我们能够在没有任何额外训练数据的情况下在新域上获得更准确的结果,接近完全监督的MRC系统的性能。
SynNet就像一位教师,根据她在以前领域的经验,从新领域的文章中创建问题和答案,并使用这些材料教她的学生在新领域中进行阅读理解。因此,微软研究人员还开发了一套神经机器阅读模型,包括最近开发的ReasoNet,它已经显示了很多承诺,就像那些从教材中学习并根据文章回答问题的学生一样。
据我们所知,这是首次尝试应用MRC域名转移。我们期待开发可扩展的解决方案,迅速扩展MRC的能力,释放机器读取的游戏变化潜力!
相关:微软正在教授阅读,回答甚至提问的系统
开始使用GitHub上的Stanford Question Answering Dataset
用单语数据改进神经机器翻译模型
访问Microsoft Research深度学习小组
对于人类来说,阅读理解是一项基本任务,每天都要进行。早在小学,我们就可以阅读一篇文章,并回答有关其主要思想和细节的问题。
但对于人工智能而言,完全阅读理解仍然是一个难以实现的目标 - 但如果我们要衡量和实现一般情报AI,这是必要的目标。在实践中,阅读理解对于许多现实场景是必要的,包括客户支持,推荐,问答,对话和客户关系管理。它具有令人难以置信的潜力,例如帮助医生在数千份文件中快速查找重要信息,节省他们的时间,以获得更高价值和可能挽救生命的工作。
因此,能够执行机器读数理解(MRC)的建筑机器非常令人感兴趣。在搜索应用程序中,机器理解将提供精确的答案,而不是在冗长的网页中包含答案的URL。此外,机器理解模型可以理解嵌入在通常涵盖狭窄和特定领域的文章中的特定知识,其中算法所依赖的搜索数据是稀疏的。
微软专注于机器阅读,目前正在引领该领域的竞争。微软的多个项目,包括机器理解的深度学习,也将目光投向了MRC。尽管取得了很大进展,但直到最近才忽略了一个关键问题 - 如何为新域构建MRC系统?
最近,来自斯坦福大学的微软研究AI的几位研究人员,包括Po-Sen Huang, Xiaodong He和实习生David Golub开发了一种用于MRC的转移学习算法来解决这个问题。他们的工作将在EMNLP 2017上进行,这是一个顶级的自然语言处理会议。这是开发可扩展解决方案以将MRC扩展到更广泛领域的关键一步。
这是我们为实现我们在微软的更广泛目标所取得的进展的一个例子:创建具有更复杂和细微差别功能的技术。“我们不只是要构建一堆算法来解决理论问题。我们正在使用它们来解决实际问题并在真实数据上进行测试,“ Rangan Majumder在机器阅读博客中表示。
目前,大多数最先进的机器阅读系统都建立在数据示例的端对端监督培训数据培训上,不仅包含文章,还包含有关文章和相应答案的手动标记问题。通过这些示例,基于深度学习的MRC模型学习理解问题并从文章中推断出答案,其中涉及推理和推理的多个步骤。
但是,对于许多域或垂直行业,此监督的培训数据不存在。例如,如果我们需要建立一个新的机器阅读系统来帮助医生找到有关新疾病的重要信息,可能会有许多文件可用,但是缺乏关于文章的手动标记问题以及相应的答案。需要为每种不同的疾病建立一个单独的MRC系统,并且文献量迅速增加,这一挑战被放大了。因此,弄清楚如何将MRC系统转移到没有手动标记的问题和答案的新域,这是至关重要的,但是有一大堆文件。
微软研究人员开发了一种名为“两阶段合成网络”的新型模型,即SynNet,以满足这一关键需求。在这种方法中,基于一个领域中可用的监督数据,SynNet首先学习识别文章中潜在“兴趣”的一般模式。这些是关键知识点,命名实体或语义概念,通常是人们可能要求的答案。然后,在第二阶段,模型学习在文章的上下文中围绕这些潜在答案形成自然语言问题。经过培训,SynNet可以应用于新域,读取新域中的文档,然后针对这些文档生成伪问题和答案。然后,它形成必要的培训数据,以培训新域的MRC系统,这可能是一种新疾病,新公司的员工手册或新产品手册。
之前已经探索过生成合成数据以增加不足的训练数据的想法。例如,对于目标翻译任务,Rico Sennrich及其同事在他们的论文中提出了一种方法,用于生成合成翻译,给出真实句子以重新定义现有的机器翻译系统。但是,与机器翻译不同,对于像MRC这样的任务,我们需要综合一篇文章的问题和答案。此外,虽然问题是语法上的自然语言句子,但答案主要是段落中的一个突出的语义概念,例如命名实体,动作或数字。由于答案具有与问题不同的语言结构,因此将答案和问题视为两种不同类型的数据可能更为合适。
在我们的方法中,我们将生成问答对的过程分解为两个步骤:以段落和问题生成为条件的答案生成以段落和答案为条件。我们首先生成答案,因为答案通常是关键的语义概念,而问题可以被视为一个完整的句子,用于查询概念。
生成的问题和文章答案的两个例子如下所示:
ynNet经过培训,可以综合答案和给定段落的问题。模型的第一阶段,答案合成模块,使用双向长短期记忆(LSTM)来预测输入段落上的内外开始(IOB)标记,这标记了可能答案的关键语义概念。第二阶段是问题综合模块,它使用单向LSTM生成问题,同时参与段落中的单词嵌入和IOB ID。虽然段落中的多个跨度可以被识别为潜在答案,但我们在生成问题时选择一个跨度。
使用SynNet,我们能够在没有任何额外训练数据的情况下在新域上获得更准确的结果,接近完全监督的MRC系统的性能。
SynNet就像一位教师,根据她在以前领域的经验,从新领域的文章中创建问题和答案,并使用这些材料教她的学生在新领域中进行阅读理解。因此,微软研究人员还开发了一套神经机器阅读模型,包括最近开发的ReasoNet,它已经显示了很多承诺,就像那些从教材中学习并根据文章回答问题的学生一样。
据我们所知,这是首次尝试应用MRC域名转移。我们期待开发可扩展的解决方案,迅速扩展MRC的能力,释放机器读取的游戏变化潜力!
相关:微软正在教授阅读,回答甚至提问的系统
开始使用GitHub上的Stanford Question Answering Dataset
用单语数据改进神经机器翻译模型
访问Microsoft Research深度学习小组

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消