


















NLP项目:使用NLTK和SpaCy进行命名实体识别

命名实体识别(NER)是信息提取的第一步,旨在在文本中查找和分类命名实体转换为预定义的分类,例如人员名称,组织,地点,时间,数量,货币价值,百分比等。NER用于自然语言处理(NLP)的许多领域,它可以帮助回答许多现实问题,例如:
- 新闻文章中提到了哪些公司?
- 在投诉或审查中是否提及特定产品?
- 这条推文是否包含某个人的名字?这条推文是否包含此人的位置?
本文介绍如何使用NLTK和SpaCy构建命名实体识别器,以在原始文本中识别事物的名称,例如人员、组织或位置。
NLTK
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
信息提取
我接收了《纽约时报》(New York Times) 的一句话,“European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices.”
ex = 'European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices'
然后我们将单词标记和词性标注应用于句子。
def preprocess(sent):
sent = nltk.word_tokenize(sent)
sent = nltk.pos_tag(sent)
return sent
让我们看看我们得到了什么:
sent = preprocess(ex)
sent

我们得到一个元组列表,其中包含句子中的单个单词及其相关的词性。
现在,我们实现名词短语分块,以使用正则表达式来识别命名实体,正则表达式指示句子的分块规则。
我们的块模式由一个规则组成,每当这个块找到一个可选的限定词(DT),后面跟着几个形容词(JJ),然后再跟着一个名词(NN)时,应该形成名词短语NP。
pattern ='NP:{块
使用这种模式,我们创建一个块解析程序并在我们的句子上测试它。
cp = nltk.RegexpParser(pattern)
cs = cp.parse(sent)
print(cs)

输出可以读取为树或层,S为第一层,表示句子。我们也可以用图形方式显示它。

IOB标签已经成为表示文件中块结构的标准方式,我们也使用这种格式。
from nltk.chunk import conlltags2tree, tree2conlltags
from pprint import pprint
iob_tagged = tree2conlltags(cs)
pprint(iob_tagged)

在此表示中,每行有一个标记,每个标记具有其词性标记及其命名实体标记。基于这个训练语料库,我们可以构建一个可用于标记新句子的标记器;并使用nltk.chunk.conlltags2tree()函数将标记序列转换为块树。
使用函数nltk.ne_chunk(),我们可以使用分类器识别命名实体,分类器添加类别标签(如PERSON,ORGANIZATION和GPE)。
ne_tree = ne_chunk(pos_tag(word_tokenize(ex)))
print(ne_tree)

谷歌被识别为一个人。这非常令人失望。
SpaCy
SpaCy的命名实体识别已经在OntoNotes 5语料库上进行了训练,它支持以下实体类型:

实体
import spacy
from spacy import displacy
from collections import Counter
import en_core_web_sm
nlp = en_core_web_sm.load()
我们使用同样的句子。
Spacy的一个好处是我们只需要应用nlp一次,整个后台管道都会返回对象。
doc = nlp('European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices')
pprint([(X.text, X.label_) for X in doc.ents])
欧洲是NORD(国家或宗教或政治团体),谷歌是一个组织,51亿美元是货币价值,周三是日期对象。他们都是正确的。
标记
在上面的示例中,我们在"实体"级别上处理,在下面的示例中,我们使用BILUO标记方案演示“标记”级别的实体注释,以描述实体边界。

pprint([(X,X.ent_iob_,X.ent_type_)for doc in doc])

"B"表示象征开始于实体,"I"意味着它在实体内部,"O"意味着它在实体外部,并且""意味着没有设置实体标记。
从文章中提取命名实体
现在让我们严肃地讨论SpaCy,从《纽约时报》的一篇文章中提取命名实体 - “F.B.I. Agent Peter Strzok, Who Criticized Trump in Texts, Is Fired”(链接代码中有)。
from bs4 import BeautifulSoup
import requests
import re
def url_to_string(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, 'html5lib')
for script in soup(["script", "style", 'aside']):
script.extract()
return " ".join(re.split(r'[\n\t]+', soup.get_text()))
ny_bb = url_to_string('https://www.nytimes.com/2018/08/13/us/politics/peter-strzok-fired-fbi.html?hp&action=click&pgtype=Homepage&clickSource=story-heading&module=first-column-region®ion=top-news&WT.nav=top-news')
article = nlp(ny_bb)
len(article.ents)
188
文章中有188个实体,它们表示为10个唯一标签:
labels = [x.label_ for x in article.ents]
Counter(labels)

以下是三种最常见的标记。
items = [x.text for x in article.ents]
Counter(items).most_common(3)
让我们随机选择一个句子进行更多的了解。
sentences = [x for x in article.sents]
print(sentences[20])
运行displacy.render 以生成原始标记。
displacy.render(nlp(str(sentences [20])),jupyter = True,style ='ent')

在这里 F.B.I.被错误的分类。
使用spaCy的内置displaCy可视化工具,以下是上述句子及其依赖关系:
displacy.render(nlp(str(sentences [20])),style ='dep',jupyter = True,options = {'distance':120})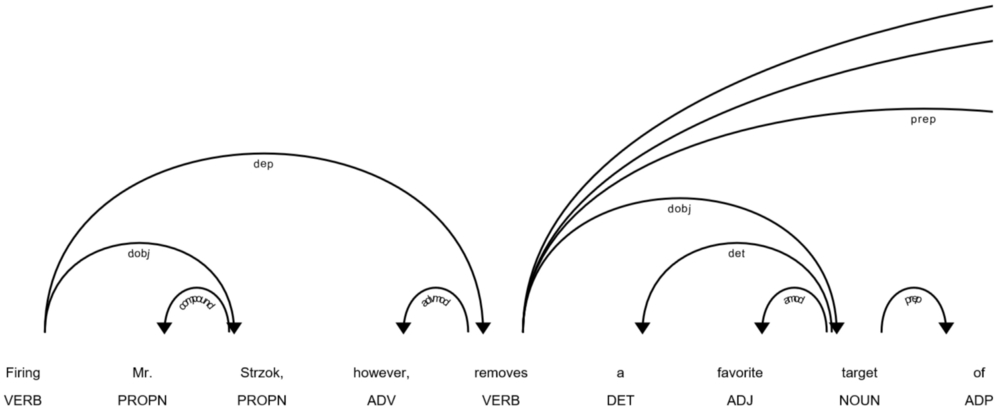
接下来,我们逐字逐句地提取词性,并对这个句子进行lemmatize 。
[(x.orth_,x.pos_,x.lemma_)for x in [y
for y
in nlp(str(sentences [20]))
if if y.is_stop and y.pos_!='PUNCT']]

dict([(str(x),x.label_)for n in nlp(str(sentences [20]))。ents])

除“FBI”外,命名实体提取是正确的。
print([(x, x.ent_iob_, x.ent_type_) for x in sentences[20]])

最后,我们可视化整篇文章的命名实体。

源代码可以在Github上找到
Github:https://github.com/susanli2016/NLP-with-Python/blob/master/NER_NLTK_Spacy.ipynb









