











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






探索生成式对抗网络GAN训练的技术:自注意力和光谱标准化
2018年08月24日 由 yuxiangyu 发表
332484
0

介绍
最近,生成模型引起了很多关注。其中很大以部分都来自生成式对抗网络(GAN)。GAN是一个框架,由Goodfellow等人发明,其中互相竞争的网络,生成器G和鉴别器D都由函数逼近器表示。它们在对抗中扮演不同的角色。
给定训练数据 Dtrain,生成器创建样本以试图模仿与Dtrain相同概率分布的样本。
而鉴别器是常见的二元分类器。它主要做两件事。首先,它对自己接收的输入是来自真实数据分布(Dtrain)还是来自生成器的分布进行分类。然后,D还通过将梯度传递给G,引导G创建更真实的样本。实际上,从D获取梯度是G优化参数的唯一方法。
在这个对抗中,G将随机噪声作为输入并生成样本图像Gsample。此示例旨在使D误解图片来自真实训练集Dtrain的概率尽可能大
在训练期间,D既接收来自训练集Dtrain的图像,也接收来自生成器网络的图像Gsample。训练鉴别器,最大限度地为真实图像(来自训练集)和假样本(来自G)分配正确的类标签。最后,希望对抗找到平衡 ,即纳什均衡。在这种情况下,生成器将捕获数据概率分布。而鉴别器将无法区分真假样本。
在过去的几年中,在许多不同的应用程序中得到了应用。其中包括:生成合成数据、图像嵌入、半监督学习、超分辨率、文本到图像生成等。
然而,最近关于GAN的大部分工作都集中在开发稳定训练的技术上。实际上,在训练期间是不稳定的,并且对超参数的选择非常敏感。
在此背景下,本文概述了两种改进GAN的相关技术。具体而言,我们的目标是描述改善生成器样品质量的最新方法。为此,我们讨论了最近的论文中探讨的技术:自注意力生成对抗网络(Self-Attention Generative Adversarial Networks)。
下方链接提供了使用Tensorflow急切执行API开发的所有代码。
GitHub:https://github.com/sthalles/blog-resources/tree/master/sagan
卷积GAN
深度卷积GAN(DCGAN)是图像生成GAN成功的第一步。DCGAN由一系列卷积网络组成,它强加某些架构限制来稳定GAN的训练。在DCGAN中,生成器由一系列转置卷积运算组成。这些运算采用随机噪声向量z并通过逐渐增加其空间维度来转换它,同时减小其特征体积深度。
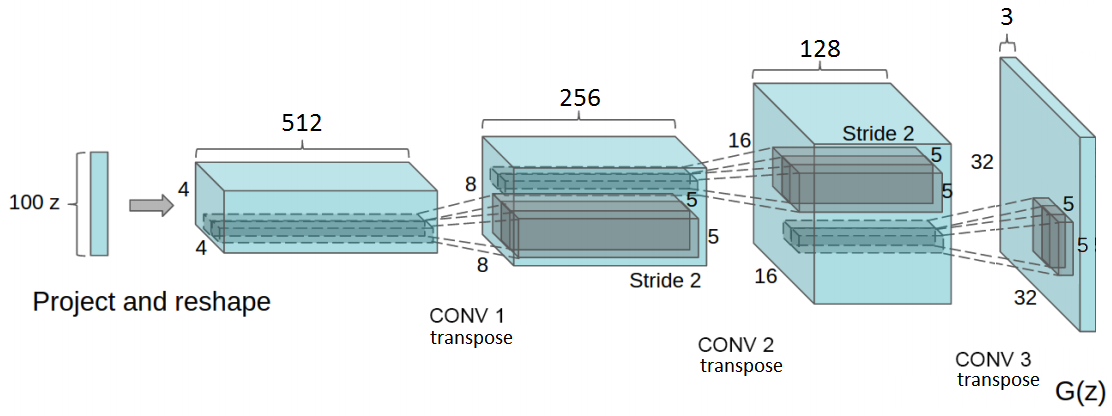
DCGAN引入了一系列的架构指引,以稳定GAN训练。首先,它主张使用跨卷积代替池化层。此外,它对生成器和鉴别器网络使用批标准化(BN)。最后,它在生成器中使用ReLU和Tanh激活,在鉴别器中使用leaky ReLU。
批标准化的工作原理是将层的输入特征标准化,使其具有零均值和单位方差。BN对于让更深层次的模型工作而不会陷入模式崩溃来说至关重要。模式崩溃是G创建具有非常少的多样性样本的情况。换句话说,G为不同的输入信号返回相同的样本。此外,批标准化还有助于处理由于参数初始化不良而产生的问题。
此外,DCGAN在鉴别器网络中使用Leaky ReLU激活。与常规ReLU函数不同的是,Leaky ReLU允许为负值传递一个小的梯度信号。因此,它使来自鉴别器的梯度更强地流入生成器。它不在反向传播中传递0梯度(斜率),而是传递一个小的负梯度。
DCGAN引入的架构指引仍然存在于最近模型的设计中。但是,大部分工作都集中在如何使GAN训练更加稳定。
自注意力GAN
自注意力生成式对抗网络(SAGAN)就是这些工作的成果之一。最近,注意力技术在机器翻译等问题上地探索取得了成功。SAGAN是一种允许生成器模拟远程依赖性的架构。主要的思路是使生成器能够生成具有全局细节信息的样本。
如果我们看一下DCGAN模型,我们会发现常规GAN主要基于卷积。这些操作使用局部感受野(local receptive field,卷积内核)来学习表示。卷积具有非常好的特性,例如参数共享和平移不变性。
典型的深度卷积以分层方式学习表示。对于常规图像分类卷积网络,在前几层中学习边缘和角落等简单特征。此外,卷积网络能够使用这些简单的表示来学习更复杂的表示。也就是说,它可以学习用更简单表示表达的表示。因此,长期依赖可能难以学习。
实际上,它可能只适用于非常少的特征向量。问题在于,在这种粒度下,信号损失量使得它难以对长期细节进行建模。看看下面的图片。

它们来自在ImageNet上训练的DCGAN模型。如前所述,大多数不显示精细形状的图像内容看起来都很好。换句话说,GAN通常不会在建模较少的结构内容(如天空或海洋)时遇到问题。
然而,创建几何形状复杂(如四足动物)的任务就很难了。这是因为,复杂的几何轮廓需要长期细节,而卷积本身可能无法掌握这些细节。这就是注意力发挥作用的地方。
我们的思路是向生成器提供来自更广泛的特征空间的信息。不局限于卷积内核范围。通过这样做,生成器可以创建具有精细分辨率的样本。
实现
通常,给定卷积层L的输入特征,第一步是将L转换成3种不同的表示形式。我们使用1x1卷积对L进行卷积并获得三个特征空间:f,g和h。在这里,我们使用f和g来计算注意力。为此,我们使用矩阵乘法对f和g进行线性组合,并将结果输入softmax层。
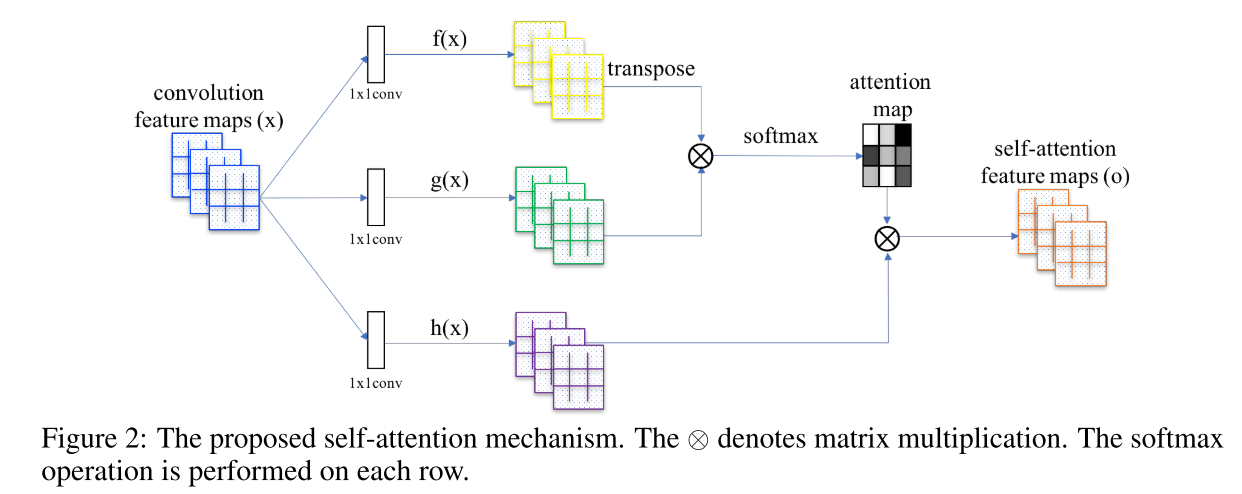
得到的张量与h线性结合,最后通过gamma进行缩放(注意,gamma开始为0)。在训练开始时,gamma会消除注意层。因此,网络仅依赖于常规卷积层的局部表示。然而,随着gamma接收梯度下降更新,网络逐渐允许来自非局部的信号通过。
另外,请注意,特征向量f和g具有与h不同的尺寸。事实上,f和g使用的卷积滤波器比h少8倍。
下面是自注意力模块的完整代码。
import tensorflow as tf
tfe = tf.contrib.eager
from libs.convolutions import Conv2D
def hw_flatten(x):
# Input shape x: [BATCH, HEIGHT, WIDTH, CHANNELS]
# flat the feature volume across the width and height dimensions
x_shape = tf.shape(x)
return tf.reshape(x, [x_shape[0], -1, x_shape[-1]]) # return [BATCH, W*H, CHANNELS]
class SelfAttention(tf.keras.Model):
def __init__(self, number_of_filters, dtype=tf.float64):
super(SelfAttention, self).__init__()
self.f = Conv2D(number_of_filters//8, 1, spectral_normalization=True,
strides=1, padding='SAME', name="f_x",
activation=None, dtype=dtype)
self.g = Conv2D(number_of_filters//8, 1, spectral_normalization=True,
strides=1, padding='SAME', name="g_x",
activation=None, dtype=dtype)
self.h = Conv2D(number_of_filters, 1, spectral_normalization=True,
strides=1, padding='SAME', name="h_x",
activation=None, dtype=dtype)
self.gamma = tfe.Variable(0., dtype=dtype, trainable=True, name="gamma")
self.flatten = tf.keras.layers.Flatten()
def call(self, x):
f = self.f(x)
g = self.g(x)
h = self.h(x)
f_flatten = hw_flatten(f)
g_flatten = hw_flatten(g)
h_flatten = hw_flatten(h)
s = tf.matmul(g_flatten, f_flatten, transpose_b=True) # [B,N,C] * [B, N, C] = [B, N, N]
b = tf.nn.softmax(s, axis=-1)
o = tf.matmul(b, h_flatten)
y = self.gamma * tf.reshape(o, tf.shape(x)) + x
return y
光谱标准化
此前,Miyato等人提出了一种称为光谱标准化(SN,spectral normalization)的标准化技术。简单的说,SN约束卷积滤波器的Lipschitz常数。SN被用作稳定鉴别器网络训练的方法。在实践中,它非常有效。
然而,在训练经过标准化的鉴别器时存在一个问题。过去的研究表明,正则化的鉴别器使GAN训练变慢。因此,一些解决方法包括使生成器和鉴别器之间的更新步骤的速率不均匀。换句话说,我们可以在更新生成器之前更新鉴别器几次。例如,每次生成器更新,正则化鉴别器可能需要5次或更多的更新。
为了解决学习慢、更新步骤不平衡的问题,这是一种简单而有效的方法。值得注意的是,在GAN框架中,G和D一起训练。在此背景下,Heusel等人在GAN训练中引入了TTUR(two-timescale update rule)。它包括提供不同的学习率,以优化生成器和鉴别器。
鉴别器训练的学习率分别比G高4倍(分别为0.004和0.001)。较大的学习率意味着鉴别器将吸收梯度信号的较大部分。因此,较高的学习率缓解了正则化鉴别器学习慢的问题。。此外,这种方法使得对生成器和鉴别器使用相同的更新速率成为可能。实际上,我们在生成器和鉴别器之间使用的更新间隔就是1:1。
此外,有论文已经表明,受限良好的生成器与GAN性能有因果关系。鉴于此,GAN的自注意力也被提倡使用光谱标准化来稳定生成器网络的训练。对于G,它可以防止参数变得过大并避免不必要的梯度。
论文:https://arxiv.org/abs/1802.08768
实现
值得注意的是,Miyato等人引入的光谱标准化(SN)算法是一种迭代逼近。它定义了用于正则化每个Conv层Wl的光谱标准化是Wl的最大奇异值。在这里,“l ”属于网络的所有层的集合L.
在每个步骤中应用奇异值分解都可能是计算的扩展。因而,Miyato等人使用幂迭代法估计每一层的光谱标准化。
要使用Tensorflow急切执行来实现SN,我们必须下载并调整convolutions.py文件。
完整的代码:https://github.com/keras-team/keras/blob/master/keras/layers/convolutional.py
下面我们将展示算法中有趣的部分。首先,我们随机初始化一个向量u,如下所示。
self.u = K.random_normal_variable([1, units], 0, 1, dtype=self.dtype) # [1, out_channels]
如算法1所示,幂迭代法计算向量u和卷积核Wi的线性组合之间的l2距离。并且,在非标准化核权重上计算光谱标准化。

需要注意的是在训练期间,在幂迭代中计算的值ü,作为你在下一次迭代的初始值。这种策略使算法仅使用1轮幂迭代就能得到非常好的估计。此外,为了标准化核权重,我们将它们除以当前的光谱标准化估计。
def _l2normalizer(v, epsilon=1e-12):
return v / (K.sum(v ** 2) ** 0.5 + epsilon)
def power_iteration(W, u, rounds=1):
'''
Accroding the paper, we only need to do power iteration one time.
'''
_u = u
for i in range(rounds):
_v = _l2normalizer(K.dot(_u, W))
_u = _l2normalizer(K.dot(_v, K.transpose(W)))
W_sn = K.sum(K.dot(_u, W) * _v)
return W_sn, _u, _v
def compute_spectral_normal(self, training=True):
# Spectrally Normalized Weight
if self.spectral_normalization:
# Get kernel tensor shape [batch, units]
W_shape = self.kernel.shape.as_list()
# Flatten the Tensor
W_mat = K.reshape(self.kernel, [W_shape[-1], -1]) # [out_channels, N]
W_sn, u, v = power_iteration(W_mat, self.u)
if training:
# Update estimated 1st singular vector
self.u.assign(u)
return self.kernel / W_sn
else:
return self.kernel
实现说明
我们使用光谱标准化和自注意力训练了SAGAN模型的定制版本。我们使用了Tensorflow的tf.keras和急切执行。
生成器采用随机向量z并生成128x128 RGB图像。所有层,包括稠密层,都使用光谱标准化。此外,生成器使用批量标准化和ReLU激活。此外,它在中到高的特征映射之间使用自注意力。与最初的实现一样,我们将注意力层放置在尺寸为32x32的特征映射上。
鉴别器还使用谱标准化(所有层)。它采用大小为128x128的 RGB图像样本并输出未缩放的概率。它使用 Leaky ReLU,其alpha参数为0.02。与生成器一样,它还具有自我关注层,可操作尺寸为32x32的特征映射。

目标是最小化对抗性损失的hinge版本。为此,我们使用Adam优化器以交替方式训练生成器和鉴别器。
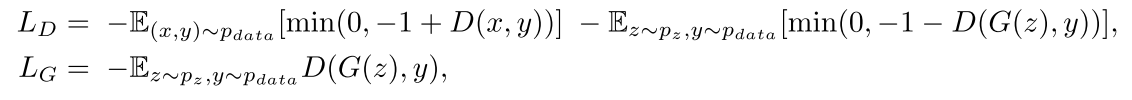
# Hinge version of the GAN loss
def discriminator_loss(d_logits_real, d_logits_fake):
real_loss = tf.reduce_mean(tf.nn.relu(1. - d_logits_real))
fake_loss = tf.reduce_mean(tf.nn.relu(1. + d_logits_fake))
return real_loss + fake_loss
def generator_loss(d_logits_fake):
return - tf.reduce_mean(d_logits_fake)
在此任务中,我们使用的数据集为:
Large-scale CelebFaces Attributes (CelebA):https://sthalles.github.io/advanced_gans/#7
以下是结果。


欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消