












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌基于语义模型打造全新搜索方式——Talk to Books
2018年04月16日 由 浅浅 发表
807562
0

在过去几年中,自然语言理解发展迅速,部分原因是词向量的发展,使得算法能够根据实际语言运用来了解字词间的关系。这些向量模型图基于等价、相似或关联性的思想和语言,将具有相似语义的短语映射到附近点。
去年,谷歌使用了分等级的语言向量模型来改进Gmail的智能回复功能。最近,研究者也一直在探索将这些方法推广到其他应用上去。
Semantic Experiences这一网站展示了两个例子,来说明这些新特性是怎样作用于应用程序的,而这样的结果是过去无法实现的。Talk to Books是一种搜索书籍的全新方式,从句子起步,而不是从作者或主题层面开始。Semantris是一种由机器学习技术支持的单词联想游戏,玩家可以在其中输入与给定提示相关的单词。谷歌还发布了Universal Sentence Encoder一文,更详细地描述了用于这些例子的模型。此外,谷歌为社区提供了一个预训练的语义TensorFlow模块,可以用自己的句子做试验,以及进行短语编码。
建模方法
该方法通过为更大的语言块(比如完整句子和小段落)创建向量,扩展了在向量空间中表达语言的理念。由于语言是由概念的层次结构组成的,所以研究者利用模块的层次结构来创建向量,并考虑到每个模块与不同时间尺度和序列相当的特性。关联词,同义词,反义词,部份-整体关系,以及其他类型关系,如果以正确的方式训练它们,提出正确的问题,它们都可以用向量空间语言模型来表示。这种方法在《用有效的自然语言反应进行智能回复》(Efficient Natural Language Response for Smart Reply)一文中有具体描述。
Talk to Books
Talk to Books这一方法提供了一种搜索书籍的全新方式。当做了陈述或是问了问题,这一工具会在书中找到回复的句子,而不依赖于关键字匹配。从某种意义上来说,与书籍对话并得到回应,你便能够知道自己有没有兴趣阅读这本书。
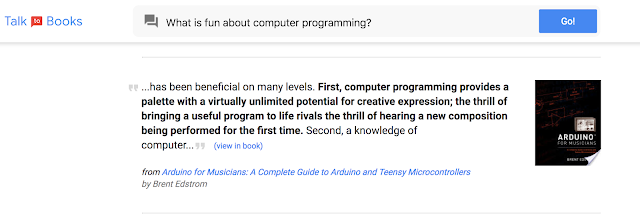
这一模型已接受了10亿次类似的对话训练,学会辨别如何做出合适的回应。一旦你问了问题(或者进行陈述),这一工具会在超过10万本书中搜索句子,基于语义含义在句子层面对你的输入做出反应,而且没有预定义的规则限制输入的内容和所得到的结果。
传统的关键词搜索可能不会出现结果,但这个功能是独一无二的,可以帮助你找到有趣的书,不过此功能仍有改进的空间。
例如,这个实验在句子层面上搜索(而不是如同Gmail的智能回复中那样是在段落层面),所以机器认为好的匹配句子,仍可能会是断章取义的结果。你可能会得到一些你并不想要的书和段落,或者段落被选中的原因并不明显。名声显著的书并不一定居于候选的前列,这个实验只考虑单个句子的匹配度。
然而这种方法的一个好处是,可以帮助人们发现意想不到的作者和标题,并以一种新颖和创新的方式发现书籍。
Semantris
单词联想游戏Semantris也是由此技术开发的。当你输入一个单词或短语时,游戏会在屏幕上列出所有的单词,根据你输入内容的反应好坏来评分。同样,同义词、反义词和相似概念在这个语义模型中都处于平行模式。
Arcade版本中的时间压力(如下所示)会迫使你输入单个单词作为提示。Blocks版本没有时间压力,可以尽情尝试输入短语和句子。你可以试验一下提示究竟可以晦涩难懂到什么程度。
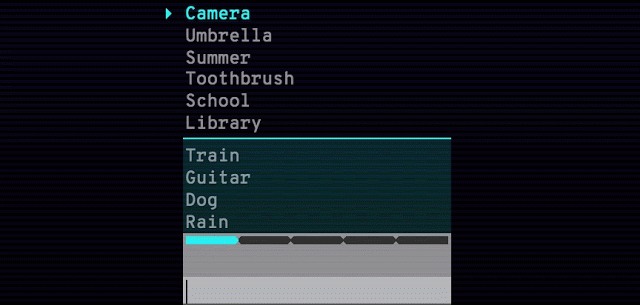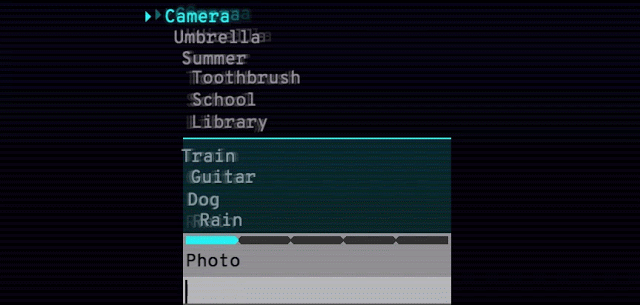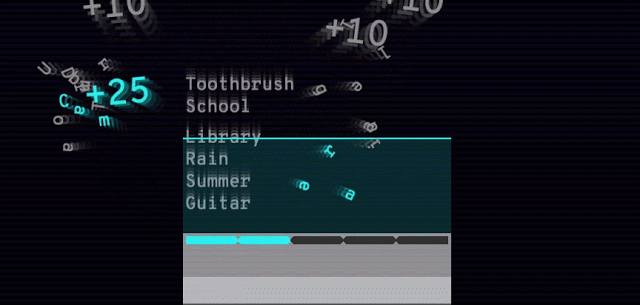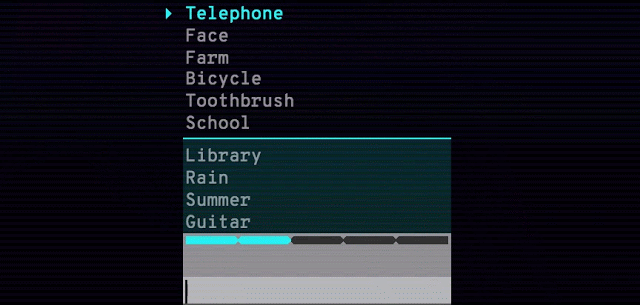
Semantris Arcade
这些例子只是利用新工具进行经验思考和设计应用程序的几种可能的方法。其他有潜力的应用包括:分类、语义相似性、语义群集、白名单应用(在可供替代的选项中选取合适的回应)、语义研究(例如Talk to Books方法)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消