












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌Tacotron进展:使用文字合成的语音更加自然
2018年03月29日 由 yuxiangyu 发表
94845
0
Google研究所一直在探索让机器合成语音更加自然的方法。Machine Perception、Google Brain和 TTS Research近日在博客中宣布,他们找到了让语音更具表现力的方法。以下为博客的原文翻译。
在谷歌,我们最近在使用神经网络进行TTS(文字转语音)的研究中进展很快,我们为此感到欣喜。特别是,我们去年宣布的Tacotron系统等端到端架构,它们既可以简化语音构建管道,也可以产生听起来很自然的讲话声。这种进步未来会帮助我们建立更好的人机界面,如会话助理,有声读物的叙述,新闻阅读器或语音设计软件。然而,要提供真的像人一样的声音,TTS系统必须学会模仿韵律(prosody),演讲富有表现力的 各种因素的集合,如语调,重读和节奏。包括Tacotron在内的大多数当前端到端系统都没有明确地对此建模,这意味着它们无法精确控制生成的语音应该如何发音。这可能会使说话声音单调,即使模型在非常富有表现力的数据集(如有声读物,这种数据集包含的声音,往往随演讲者演讲内容含义而变化)上训练也无济于事。如今,我们很高兴与大家分享解决这些问题的两篇新论文。
我们的第一篇论文“ Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron ”引入了韵律嵌入(prosody embedding)的概念。我们在Tacotron架构中增加了从人类语音片段(参考音频)计算低维嵌入的韵律编码器。
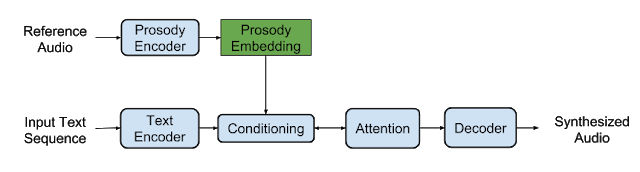
图的下半部分是原始的Tacotron的seq2seq模型。
这种嵌入捕捉音频的特征,这些特征独立于语音信息和独特的说话者特征,他们包括重读,语调和语速。在推理时,我们可以使用这种嵌入来执行韵律的迁移,以生成完全不同的演讲者的声音来产生话语,并且在此展现参考音频的韵律。
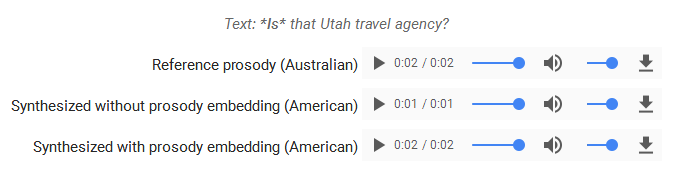
嵌入也可以将时序几乎一致的韵律从一个短语迁移到稍微不同的短语。当然,只有当参考短语和目标短语的长度和结构相似时,这个技术的效果才最好。

令人激动的是,即使当参考音频并不来自Tacotron训练数据中的说话者时,我们也会观察到韵律传递。
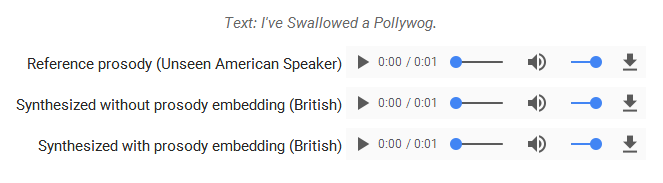
这是一个很有前景的研究结果,它为语音交互设计者提供了一种使用他们自己的语音来定制语音合成的方法。你可以在下方链接中收听论文中完整的音频演示集 。
音频:https://google.github.io/tacotron/publications/end_to_end_prosody_transfer/
尽管这种方法可以高保真的迁移韵律,但这种嵌入并不能完全解析参考音频片段内容的韵律。(这解释了为什么它们只能讲韵律最好地迁移到具有相似结构和长度的短语)。此外,它们需要在推断时提供参考音频的片段。那么我们自然会有这样的疑问:我们能否建立一种能缓解这些问题的富有表现力的演讲模型来?
在我们的第二篇论文,“Style Tokens: Unsupervised Style Modeling, Control and Transfer in
End-to-End Speech Synthesis “中,我们就是这么做的。基于我们第一篇论文的架构,我们提出了一种新的无监督方法来建模演讲潜在的因素。这种模式的关键在于,它不再学习时序一致的韵律元素,而是学习可以通过任意不同的短语转移的更高级的说话风格模式。
这个模型的工作原理是给Tacotron增加一个额外的注意机制,强制它将任何语音片段的韵律嵌入表示为一组固定的基于嵌入的线性组合。我们称这些嵌入称为全局风格符号(Global Style Tokens,GST),它用来发现他们在演讲者的风格中学习了与文本无关的变化(柔和,高亢,激烈等),而不需要明确的样式标签。
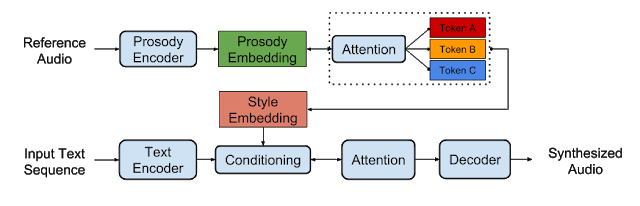
GST模型架构。韵律嵌入被分解为“风格符号”,以实现无监督的风格控制和迁移。
在推理时,我们可以选择或修改符号(tokens)的组合权重,使我们能够强制Tacotron使用特定的讲话风格,而无需参考音频片段。例如,使用GST,我们可以使不同长度的句子听起来更“活泼”,“愤怒”,“悲痛”等等。
GST的独立于文本的特性使它们成为风格迁移的理想选择,它采用以特定风格说出的参考音频剪辑,并将其风格转移到我们选择的任何目标短语。为此,我们首先运行推理来预测我们想要模仿的话语的GST组合权重。然后,我们可以将这些组合权重提供给模型,以相同风格合成完全不同的短语,即使短语的长度和结构差异很大。
最后,我们的论文表明,GST不可以建模的不仅仅是说话风格。当它受到来自未标记的说话者的嘈杂音频(来自YouTube)的训练时,启用了GST的Tacotron学会了用单独的符号表示噪声源和不同的说话者。也就是说,通过选择我们用于推理的GST,我们可以合成无背景噪声的语音,或者合成一个数据集中特定的没有标记的说话者的声音。这为高度可扩展并具有鲁棒性的语音合成开辟了道路
音频:https://google.github.io/tacotron/publications/global_style_tokens/
我们对这两项研究主体所带来的应用潜力和前景感到兴奋。同时,也有一些新的重要研究问题亟待解决。我们希望扩展第一篇论文的技巧,以支持在目标说话者自然音高范围内进行韵律迁移。我们还希望开发一种从上下文自动选择适当韵律或说话风格的技术。例如,将自然语言理解与TTS进行集成。最后,虽然我们的第一篇论文提出了一套初步的客观和主观的韵律迁移度指标,但我们希望进一步完善它们,以建立公认的韵律评估方法。
论文1:https://arxiv.org/abs/1803.09047
论文2:https://arxiv.org/abs/1803.09017

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消