











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习项目学习实践:在CIFAR-10上进行图像分类
2018年02月28日 由 yining 发表
956196
0
你想开始进行深度学习吗? 这有一篇关于Keras的深度学习的文章(地址见下方链接),对图像分类的神经网络做了一个总体概述。然而,它缺少一个关键的因素——实际的动手练习。本文将试图填补这一空白。
实用性的深度学习
深度学习有一个肮脏的秘密——不管你知道多少,总会有很多反复的尝试和错误。你需要测试各种网络体系架构、数据预处理方法、参数和优化器等等。即使是顶尖的深度学习专家,也不能只写一个神经网络程序,运行它,并在一天内调用它。
每次你看到一个最先进的神经网络,然后问自己“为什么这里会有6个卷积层?”或者“为什么他们会把dropout率提高到0.3?”答案是,他们尝试了各种各样的参数,并选择了他们在经验基础上所做的那个。然而,对其他解决方案的了解确实给我们提供了一个很好的起点。理论知识建立了一种直观的看法,即哪些想法是值得尝试的,哪些想法是不可能改善神经网络的。
解决任何深度学习问题的一个相当普遍的方法是:
- 对于给定的一类问题,使用一些最先进的体系架构。
- 修改它以优化你的特定问题的性能。
修改既包括更改其架构(例如,层数、添加或删除辅助层,如Dropout或Batch Normalization)和调优其参数。唯一重要的性能指标是验证分数(validation score),也就是说,如果在一个数据集上训练的一个网络能够对它从未遇到过的新数据做出良好的预测,其他的一切都归结为实验和调整。
一个良好的数据集——用于图像分类的CIFAR-10
许多关于深度学习的图像分类的介绍都是从MNIST开始的,MNIST是一个手写数字的标准数据集。它不仅不会产生令人感叹的效果或展示深度学习的优点,而且它也可以用浅层机器学习技术解决。在这种情况下,普通的K近邻(KNN)算法会产生超过97%的精度(甚至在数据预处理的情况下达到99.5%)。此外,MNIST并不是一个典型的图像数据集——控制它不太可能教给你可迁移的技能,而这些技能对于其他分类问题是有用的。
如果你真的需要使用28×28灰度图像数据集,那么可以看看notMNIST数据集和一个MNIST-like fashion product数据集(一个非常有趣的数据集,也是10分类问题,不过是时尚相关的)。
- notMNIST数据集:http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html
- MNIST-like fashion product数据集:https://github.com/zalandoresearch/fashion-mnist
然而,我认为没有任何理由可以避免使用真实的照片。
我们将在CIFAR-10上工作,这是一个经典的小彩色图像集。60000个32x32彩色图像,10个类,每个类有6000个图像。有50000个训练图像(也就是我们用来训练神经网络的那个)和10000个测试图像。
看一下这些样本图片:

带有示例图像的CIFAR-10类
动手实践
在开始之前:
- 创建一个Neptune账户,创建地址☞ https://neptune.ml/
- 克隆或复制https://github.com/neptune-ml/hands-on-deep-learning;我们使用的所有脚本都需要从cifar_image_classification目录中运行。
- 在Neptune上,点击项目,创建一个新的CIFAR-10(使用代码:CIF)。
代码在Keras中,地址☞ https://keras.io/
我们将使用Python 3和TensorFlow后端。该代码中唯一的特定于Neptune的部分是logging。如果你想在另一个基础设施上运行它,只需更改几行。
架构和块(在Keras中)
将深度学习与经典机器学习区别开来的是它的组合架构。我们不再使用one-class分类器(即逻辑回归、随机森林或XGBoost),而是创建一个由块(称为层)构成的网络。

深度学习隐喻:将ConvNet层比作Jenga块
逻辑回归
让我们从一个简单的“多类逻辑回归”开始。它是一种“浅层”的机器学习技术,但可以用神经网络语言表达。它的体系架构只包含一个有意义的层。在Keras,我们写如下:
model = Sequential()
model.add(Flatten(input_shape=(32, 32, 3)))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer=’adam’,
loss='categorical_crossentropy',
metrics=['accuracy'])
如果我们想一步一步地看到数据流的变化,关于维度和要优化的权重的数量,我们可以使用一个keras-sequential-ascii脚本:
OPERATION DATA DIMENSIONS WEIGHTS(N) WEIGHTS(%)
Input ##### 32 32 3
Flatten ||||| ------------------- 0 0.0%
##### 3072
Dense XXXXX ------------------- 30730 100.0%
softmax ##### 10
Flatten层只是将(x, y, channels)转换为像素值的flat向量。密集层将所有输入连接到所有的输出。然后,Softmax将实数转化为概率。
要运行它,只需输入终端:
$ neptune send lr.py --environment keras-2.0-gpu-py3 --worker gcp-gpu-medium
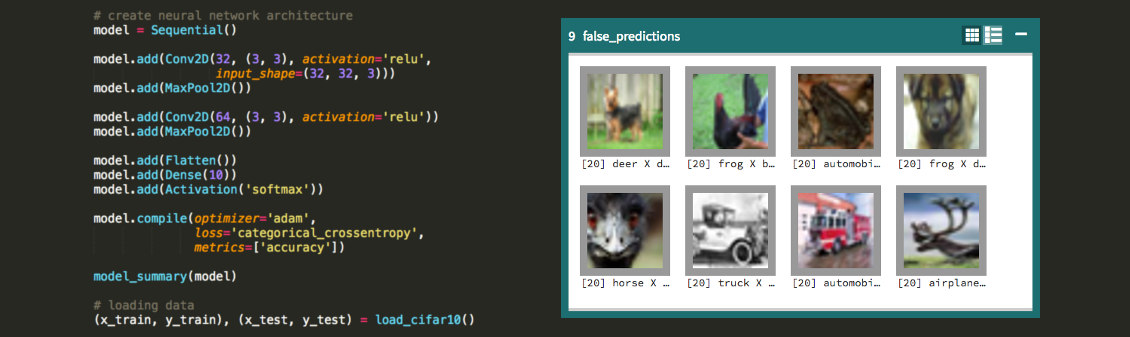
这将打开一个浏览器选项卡,在这个选项卡中你可以跟踪训练过程。你甚至可以查看错误分类的图片。然而,这个线性模型主要是在图像上寻找颜色和它们的位置。

Neptune通道仪表盘中显示的错误分类的图像
整体得分并不令人印象深刻。我在训练集上的准确率达到了41%,更重要的是,37%的准确率在验证上。请注意,10%是进行随机猜测的基线。
多层感知器
老式的神经网络由几个密集的层组成。在层之间,我们需要使用一个激活函数。该函数分别应用于每个组件,使我们可以使其非线性,使用比逻辑回归更复杂的模式。之前的方法(由生物神经网络的抽象所激发)使用了一个S函数。
model = Sequential()
model.add(Flatten(input_shape=(32, 32, 3)))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
这对我们的数据意味着什么?
OPERATION DATA DIMENSIONS WEIGHTS(N) WEIGHTS(%)
Input ##### 32 32 3
Flatten ||||| ------------------- 0 0.0%
##### 3072
Dense XXXXX ------------------- 393344 95.7%
sigmoid ##### 128
Dense XXXXX ------------------- 16512 4.0%
sigmoid ##### 128
Dense XXXXX ------------------- 1290 0.3%
softmax ##### 10
我们使用了两个额外的(所谓的隐藏的)层,每个层都带有S函数作为其激活函数。让我们来运行它!
$ neptune send mlp.py --environment keras-2.0-gpu-py3 --worker gcp-gpu-medium
我建议在一个绘图上创建一个结合训练和验证通道(validation channels)的自定义图表。
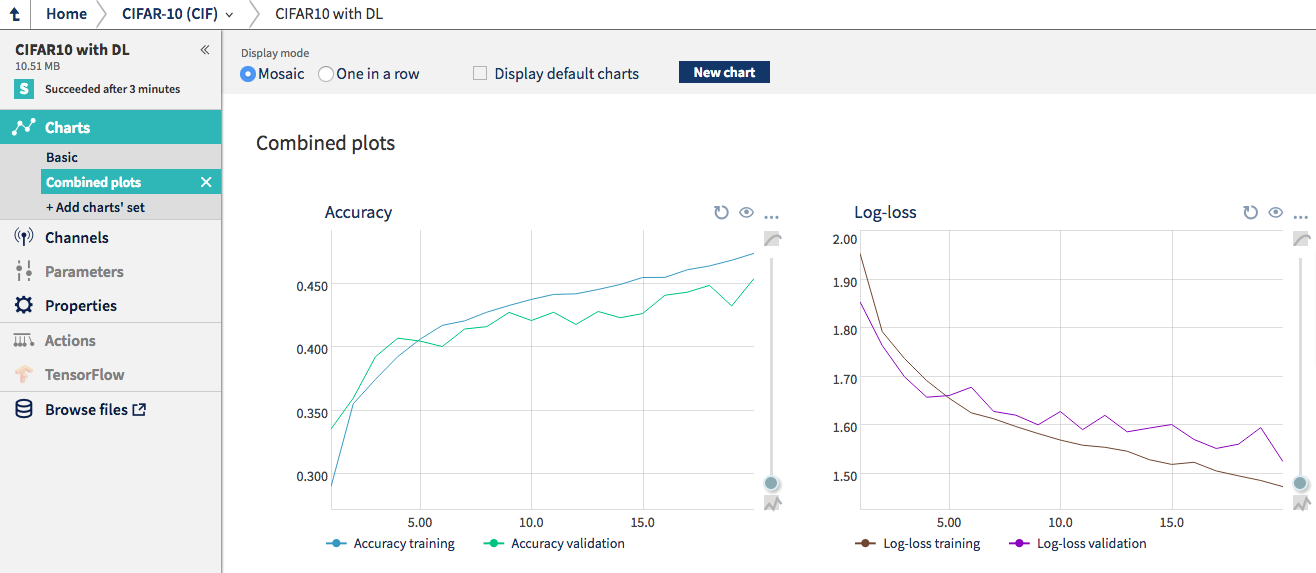
训练集和验证集的准确性和log-loss
原则上,即使有一个隐藏的层,也可以近似任何函数 (参见:万能近似定理,universal approximation theorem)。然而,这并不意味着它在实践中工作得很好,因为数据量十分有限。如果隐藏层太小,它就无法近似任何函数。当它变得太大时,网络很容易就会变得过度拟合——也就是记忆训练数据,但不能概括为其他图像。任何时候,你的训练分数都会以验证分数的成本上升,然后你的网络就会变得不过度拟合。
我们可以在验证集上获得大约45%的准确率,这是对逻辑回归的改进。不过,我们可以做得更好。如果你想要使用这种网络——编辑文件,运行它(我建议在命令行中添加——tags my-experiment),看看你是否能做得更好。采取一些方法,看看结果如何。
提示:
- 使用20个以上的epoch。
- 在实践中,神经网络使用2-3个密集层。
- 做大的改变来看看区别。在这种情况下,将隐藏层的大小更改为2x,甚至是10x。
仅仅因为理论上你应该能够用画图的方式来创建任何图片(或者甚至是任何照片),这并不意味着它将在实践中起作用。我们需要利用空间结构,并使用卷积神经网络(CNN)。
卷积神经网络
我们可以用更智能的方式处理图像,而不是试图把所有东西都连接起来。卷积是在图像的每个部分执行相同的局部操作的操作。卷积可以做的一些例子包括模糊,放大边缘或者检测颜色梯度。参见:http://setosa.io/ev/image-kernels/
每一个卷积层都根据之前的内容产生新的通道。首先,我们从红色、绿色和蓝色(RGB)组件的三个通道开始。接下来,通道变得越来越抽象。
当我们创建表示图像的各种属性的通道时,我们需要降低分辨率(通常使用max-pooling)。此外,现代网络通常使用ReLU作为激活功能,因为它对更深层的模型效果更好。
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu',
input_shape=(32, 32, 3)))
model.add(MaxPool2D())
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
网络架构是这样的:
OPERATION DATA DIMENSIONS WEIGHTS(N) WEIGHTS(%)
Input ##### 32 32 3
Conv2D \|/ ------------------- 896 2.1%
relu ##### 30 30 32
MaxPooling2D Y max ------------------- 0 0.0%
##### 15 15 32
Conv2D \|/ ------------------- 18496 43.6%
relu ##### 13 13 64
MaxPooling2D Y max ------------------- 0 0.0%
##### 6 6 64
Flatten ||||| ------------------- 0 0.0%
##### 2304
Dense XXXXX ------------------- 23050 54.3%
softmax ##### 10
要运行它,我们需要输入:
$ neptune send cnn_simple.py --environment keras-2.0-gpu-py3 --worker gcp-gpu-medium
即使使用这个简单的神经网络,我们在验证上的准确率也达到了70%。这比我们用逻辑回归或者多层感知器产生的结果要多得多!
现在,你可以自由地进行实验。
提示:
- 一般来说,3×3卷积是最好的;坚持使用它们(和只使用混合通道的1×1卷积)。
- 在进行每个MaxPool操作之前,你要有1-3个卷积层。
- 添加一个密集层可能会有所帮助。
- 在密集层之间,你可以使用Dropout,以减少过度拟合(例如,如果你发现训练的准确性高于验证的准确性)。
这仅仅是个开始。
要比较结果,请单击项目名称(project name)。你将看到整个项目列表。在Manage columns中,记录所有的accuracy score(以及可能的log-loss)。你可以使用验证精度(validation accuracy)来整理你的结果。
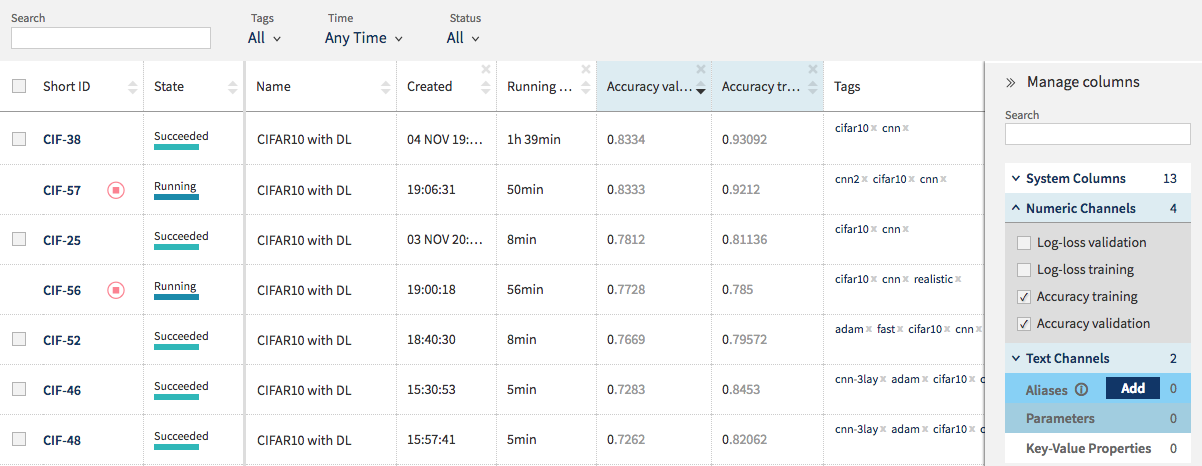
除了架构(这是一个大问题),优化器还会显著地改变总体结果的准确性。通常情况下,我们通过添加更多的epoch(即整个训练数据集的次数)来获得更好的结果,同时降低学习率(learning rate)。
例如,试试这个网络:
OPERATION DATA DIMENSIONS WEIGHTS(N) WEIGHTS(%)
Input ##### 32 32 3
Conv2D \|/ ------------------- 896 0.1%
relu ##### 32 32 32
Conv2D \|/ ------------------- 1056 0.2%
relu ##### 32 32 32
MaxPooling2D Y max ------------------- 0 0.0%
##### 16 16 32
BatchNormalization μ|σ ------------------- 128 0.0%
##### 16 16 32
Dropout | || ------------------- 0 0.0%
##### 16 16 32
Conv2D \|/ ------------------- 18496 2.9%
relu ##### 16 16 64
Conv2D \|/ ------------------- 4160 0.6%
relu ##### 16 16 64
MaxPooling2D Y max ------------------- 0 0.0%
##### 8 8 64
BatchNormalization μ|σ ------------------- 256 0.0%
##### 8 8 64
Dropout | || ------------------- 0 0.0%
##### 8 8 64
Conv2D \|/ ------------------- 73856 11.5%
relu ##### 8 8 128
Conv2D \|/ ------------------- 16512 2.6%
relu ##### 8 8 128
MaxPooling2D Y max ------------------- 0 0.0%
##### 4 4 128
BatchNormalization μ|σ ------------------- 512 0.1%
##### 4 4 128
Dropout | || ------------------- 0 0.0%
##### 4 4 128
Flatten ||||| ------------------- 0 0.0%
##### 2048
Dense XXXXX ------------------- 524544 81.6%
relu ##### 256
Dropout | || ------------------- 0 0.0%
##### 256
Dense XXXXX ------------------- 2570 0.4%
softmax ##### 10
$ neptune send cnn_adv.py --environment keras-2.0-gpu-py3 --worker gcp-gpu-medium
这个过程需要大约半个小时,但是结果会更好—验证的准确性应该在83%左右!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
用于机器学习的线性代数速查表








广告


写评论取消
回复取消