












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Google发布Tacotron 2系统:从文本生成接近人类的语音
2017年12月20日 由 yuxiangyu 发表
259457
0
用文本生成自然的语音(TTS)的研究已有数十年。而在过去的几年中,TTS的研究取得了很大的进展,完整TTS系统的许多独立的部分都有了很大的改进。结合Tacotron和WaveNet等以往工作的想法,我们增加了更多的改进,最终实现了我们的新系统Tacotron 2。我们的方法没有使用复杂的语言和声学特征作为输入。而是使用仅用语音示例和相应文本记录训练的神经网络从文本中生成类人语言。
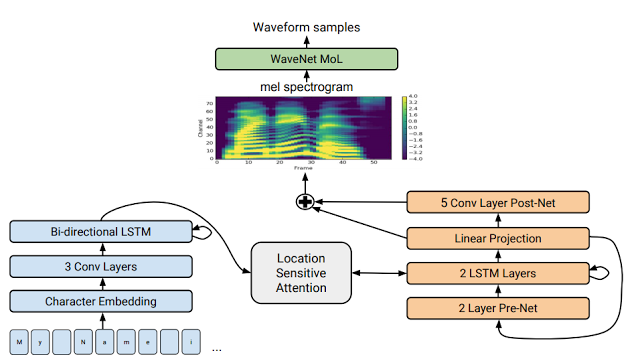
新系统的完整描述访问我们的论文查看。简而言之,它的工作原理是这样的:我们使用针对TTS优化的seq2seq模型来映射字母序列到编码音频的序列特征。这些特征是一个80维音频频谱图,每12.5毫秒计算一帧,不仅可以捕捉单词的发音,还可以捕捉人类语音的各种细节,包括音量,语速和语调。最后,这些特征使用WaveNet-like架构转换为24 kHz波形。
论文:https://arxiv.org/abs/1712.05884
我们提供了一些Tacotron 2音频样本,这里展示了我们TTS系统取得的最佳成果。在一次评估中,我们要求听众对生成的语音的是否自然进行评分,得到的评分与专业录音的评分相当。
样本链接:https://google.github.io/tacotron/publications/tacotron2/index.html
然而,虽然我们的样本听起来还不错,但仍有一些棘手的问题需要解决。例如,我们的系统对一些发音复杂的单词(如,decorum和merlot)的处理不太好,在极端的情况下甚至会随机产生奇怪的噪音。另外,我们的系统无法实时生成音频。而且,我们也无法控制生成的语音,比如让声音听起来高兴或悲伤。这些都是很有意思的研究。
新系统的完整描述访问我们的论文查看。简而言之,它的工作原理是这样的:我们使用针对TTS优化的seq2seq模型来映射字母序列到编码音频的序列特征。这些特征是一个80维音频频谱图,每12.5毫秒计算一帧,不仅可以捕捉单词的发音,还可以捕捉人类语音的各种细节,包括音量,语速和语调。最后,这些特征使用WaveNet-like架构转换为24 kHz波形。
论文:https://arxiv.org/abs/1712.05884
Tacotron 2的详细模型架构。图像的下半部分描述了将字母序列映射到声谱图的seq2seq模型。
我们提供了一些Tacotron 2音频样本,这里展示了我们TTS系统取得的最佳成果。在一次评估中,我们要求听众对生成的语音的是否自然进行评分,得到的评分与专业录音的评分相当。
样本链接:https://google.github.io/tacotron/publications/tacotron2/index.html
然而,虽然我们的样本听起来还不错,但仍有一些棘手的问题需要解决。例如,我们的系统对一些发音复杂的单词(如,decorum和merlot)的处理不太好,在极端的情况下甚至会随机产生奇怪的噪音。另外,我们的系统无法实时生成音频。而且,我们也无法控制生成的语音,比如让声音听起来高兴或悲伤。这些都是很有意思的研究。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消