











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






强化学习系列(下):贝尔曼方程
2018年05月30日 由 yining 发表
234032
0
在本文中,我们将学习贝尔曼方程和价值函数。
回报和返还(return)
正如前面所讨论的,强化学习agent如何最大化累积未来的回报。用于描述累积未来回报的词是返还,通常用R表示。我们还使用一个下标t来表示某个时间步长的返还。在数学符号中,它是这样的: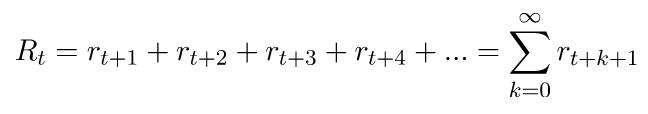 如果我们让这个级数趋于无穷,那么我们最终会得到无限的返还,这对于问题的定义并没有太大意义。因此,只有在我们期望返还的级数终止时,这个方程才有意义。我们将这种总是终止的任务称为“插曲式”(episodic)。纸牌游戏是解释“插曲式”问题的好例子。“插曲”开始于对每个人发牌,并且不可避免地会随着游戏规则的不同而结束。然后,下一“插曲”又开始了另一回合的游戏。
如果我们让这个级数趋于无穷,那么我们最终会得到无限的返还,这对于问题的定义并没有太大意义。因此,只有在我们期望返还的级数终止时,这个方程才有意义。我们将这种总是终止的任务称为“插曲式”(episodic)。纸牌游戏是解释“插曲式”问题的好例子。“插曲”开始于对每个人发牌,并且不可避免地会随着游戏规则的不同而结束。然后,下一“插曲”又开始了另一回合的游戏。
相比使用未来的累积回报作为返还,更常见的是使用未来的累积折现回报(cumulative discounted reward):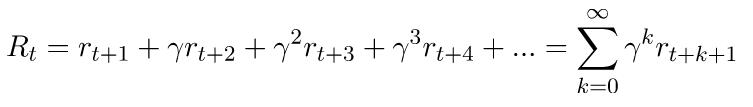 其中0<γ<1。以这种方式定义返还的两个好处是,返还在无穷级数中得到了很好的定义,而且它把更大的权重给了更早的回报,这意味着我们更关心即将得到的回报,而不是将来会得到更多的回报。我们为γ选择的值越小就越正确。这种情况在我们让γ等于0或1时就可以看到。如果γ等于1,这个方程就变成了对所有的回报都同样的关心,无论在什么时候。另一方面,当γ等于0时,我们只关心眼前的回报,而不关心以后的回报。这将导致我们的算法极其短视。它将学会采取目前最好的行动,但不会考虑行动对未来的影响。
其中0<γ<1。以这种方式定义返还的两个好处是,返还在无穷级数中得到了很好的定义,而且它把更大的权重给了更早的回报,这意味着我们更关心即将得到的回报,而不是将来会得到更多的回报。我们为γ选择的值越小就越正确。这种情况在我们让γ等于0或1时就可以看到。如果γ等于1,这个方程就变成了对所有的回报都同样的关心,无论在什么时候。另一方面,当γ等于0时,我们只关心眼前的回报,而不关心以后的回报。这将导致我们的算法极其短视。它将学会采取目前最好的行动,但不会考虑行动对未来的影响。
策略
一个策略,写成π(s, a),描述了一种行动方式。它是一个函数,能够采取一个状态和一个行动,并返回在那个状态下采取这个行动的概率。因此,对于一个给定的状态,即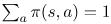 必须是真实的。在下面的例子中,当我们“饥饿”的时候,我们可以在两种行为之间做出选择,要么“吃”,要么“不吃”。
必须是真实的。在下面的例子中,当我们“饥饿”的时候,我们可以在两种行为之间做出选择,要么“吃”,要么“不吃”。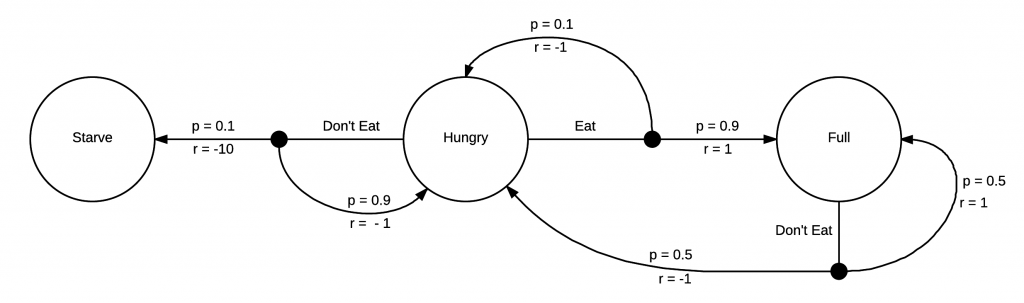 我们的策略应该描述如何在每个状态中采取行动,所以一个等概率的随机策略看起来就像
我们的策略应该描述如何在每个状态中采取行动,所以一个等概率的随机策略看起来就像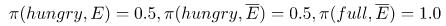 ,在这里
,在这里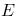 (Eat)是行为“吃”,而
(Eat)是行为“吃”,而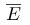 (Don’t Eat)是“不吃”。这意味着,如果你处于“饥饿”状态,选择“吃”和“不吃”的概率是相等的。
(Don’t Eat)是“不吃”。这意味着,如果你处于“饥饿”状态,选择“吃”和“不吃”的概率是相等的。
我们在强化学习中的目标是学习一种最优策略,定义为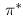 。最优策略告诉我们如何采取行动来最大化每个状态的返还。因为这是一个很简单的例子,所以很容易看出,在这种情况下,最优策略是在“饥饿”时总是“吃”,那么就是
。最优策略告诉我们如何采取行动来最大化每个状态的返还。因为这是一个很简单的例子,所以很容易看出,在这种情况下,最优策略是在“饥饿”时总是“吃”,那么就是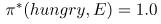 。在这个实例中,对于许多马尔可夫决策来说,最优策略是确定的。每个状态都有一个最优的行动。有时这被写成
。在这个实例中,对于许多马尔可夫决策来说,最优策略是确定的。每个状态都有一个最优的行动。有时这被写成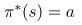 ,它是从状态到这些状态中的最优行动的映射。
,它是从状态到这些状态中的最优行动的映射。
价值函数
为了学习最优策略,我们利用了价值函数。在强化学习中有两种类型的价值函数:状态值函数(state value function),用V(s)表示,和行动值函数,用Q(s,a)表示。
状态值函数在遵循策略时描述一个状态的值。当从状态的行为以我们的策略π开始时,这就是预期的返还。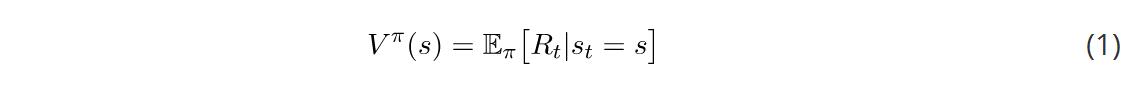 需要注意的是,即使在相同的环境中,价值函数也会根据策略发生变化。这是因为状态的价值取决于你的行动,因为你在那个特定的状态下的行动会影响你期望看到的回报。同时还要注意期望的重要性。期望(expectation)就像一个平均值;它就是你期望看到的返还。我们使用期望的原因是当你到达一个状态后会发生一些随机事件。你可能有一个随机的策略,这意味着我们需要把我们采取的所有不同行动的结果结合起来。此外,转换函数(transition function)可以是随机的,也就是说,我们可能不会以100%的概率结束任何状态。请记住上面的例子:当你选择一个行动时,环境将返回下一个状态。即使给出一个行动,也可能会有多个状态返还。当我们看贝尔曼方程时,会看到更多这样的情况。期望将所有这些随机因素考虑在内。
需要注意的是,即使在相同的环境中,价值函数也会根据策略发生变化。这是因为状态的价值取决于你的行动,因为你在那个特定的状态下的行动会影响你期望看到的回报。同时还要注意期望的重要性。期望(expectation)就像一个平均值;它就是你期望看到的返还。我们使用期望的原因是当你到达一个状态后会发生一些随机事件。你可能有一个随机的策略,这意味着我们需要把我们采取的所有不同行动的结果结合起来。此外,转换函数(transition function)可以是随机的,也就是说,我们可能不会以100%的概率结束任何状态。请记住上面的例子:当你选择一个行动时,环境将返回下一个状态。即使给出一个行动,也可能会有多个状态返还。当我们看贝尔曼方程时,会看到更多这样的情况。期望将所有这些随机因素考虑在内。
我们将使用的另一个价值函数是行动值函数。行动值函数告诉我们当跟随某个策略时,在某些状态下执行某个行动的值。给出状态和在π下的行动,这是期望的返还: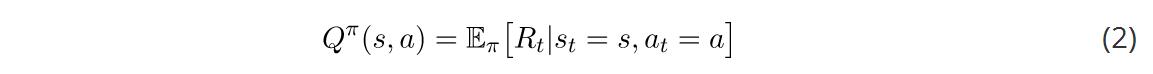
对状态值函数的注释同样适用于行动值函数。根据该策略,期望将考虑未来行动的随机性,以及来自环境的返还状态的随机性。
贝尔曼方程
理查德·贝尔曼推导出了以下公式,让我们可以开始解决这些马尔可夫决策问题。贝尔曼方程在强化学习中无处不在,对于理解强化算法的工作原理是非常必要的。但在我们了解贝尔曼方程之前,我们需要一个更有用的符号,定义为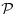 和
和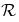 ,如下所示:
,如下所示: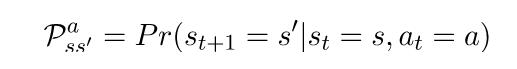 是过渡概率。如果我们从状态s开始,然后采取行动a,我们就会得到状态
是过渡概率。如果我们从状态s开始,然后采取行动a,我们就会得到状态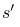 和概率
和概率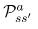 。
。
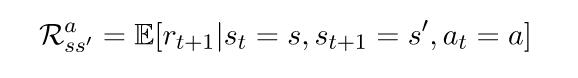
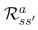 是另一种写为期望(或平均)回报的方式,我们从状态s开始,采取行动a,然后移动到状态。
是另一种写为期望(或平均)回报的方式,我们从状态s开始,采取行动a,然后移动到状态。
最后,有了这些条件,我们就可以推导出贝尔曼方程了。我们将考虑贝尔曼方程的状态值函数。根据返还的定义,我们可以重写方程(1),如下所示: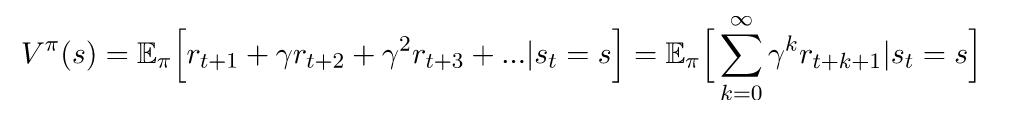 如果我们从求和中得到第一个回报,我们可以这样重写它:
如果我们从求和中得到第一个回报,我们可以这样重写它: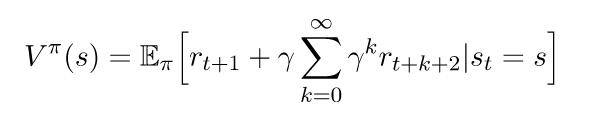 这里的期望描述的是,如果我们继续遵循策略π的状态s,我们期望返还的是什么。通过对所有可能的行动和所有可能的返还状态的求和,可以明确地编写为期望。下面的两个方程可以帮助我们完成下一个步骤。
这里的期望描述的是,如果我们继续遵循策略π的状态s,我们期望返还的是什么。通过对所有可能的行动和所有可能的返还状态的求和,可以明确地编写为期望。下面的两个方程可以帮助我们完成下一个步骤。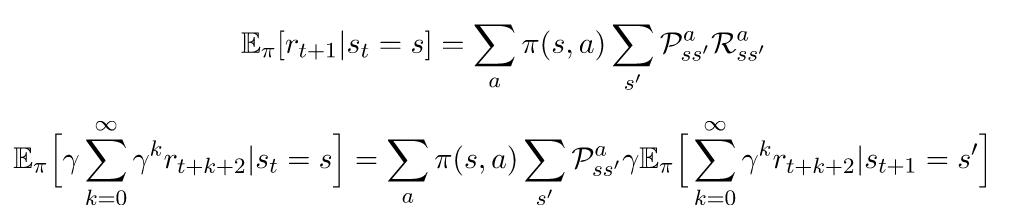 通过在这两个部分之间分配期望,我们就可以把我们的方程转化成:
通过在这两个部分之间分配期望,我们就可以把我们的方程转化成: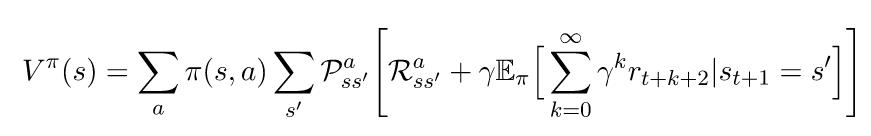 注意,方程(1)与这个方程的末尾形式相同。我们可以替换它,得到:
注意,方程(1)与这个方程的末尾形式相同。我们可以替换它,得到: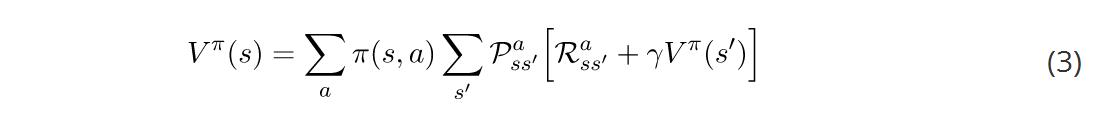 贝尔曼方程的行动值函数可以以类似的方式进行推导。本文结尾有具体过程,其结果如下:
贝尔曼方程的行动值函数可以以类似的方式进行推导。本文结尾有具体过程,其结果如下: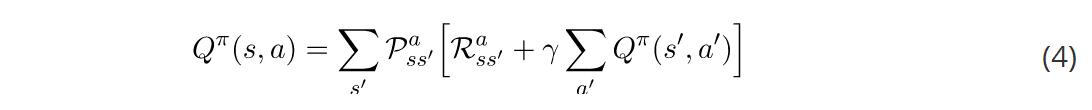 贝尔曼方程的重要性在于,它们让我们表达了其它状态的价值。这意味着,如果我们知道
贝尔曼方程的重要性在于,它们让我们表达了其它状态的价值。这意味着,如果我们知道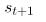 的值,我们可以很容易地计算出
的值,我们可以很容易地计算出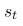 的值。这为计算每个状态值的迭代方法打开了大门,因为如果我们知道下一个状态的值,我们就可以知道当前状态的值。最重要的事情是我们需要记住一些编号方程。最后,在贝尔曼方程中,我们可以开始研究如何计算最优策略,并编码我们的第一个强化学习agent。
的值。这为计算每个状态值的迭代方法打开了大门,因为如果我们知道下一个状态的值,我们就可以知道当前状态的值。最重要的事情是我们需要记住一些编号方程。最后,在贝尔曼方程中,我们可以开始研究如何计算最优策略,并编码我们的第一个强化学习agent。
在我们推导出贝尔曼方程的过程中,我们得到了这一系列的方程,从方程(2)开始: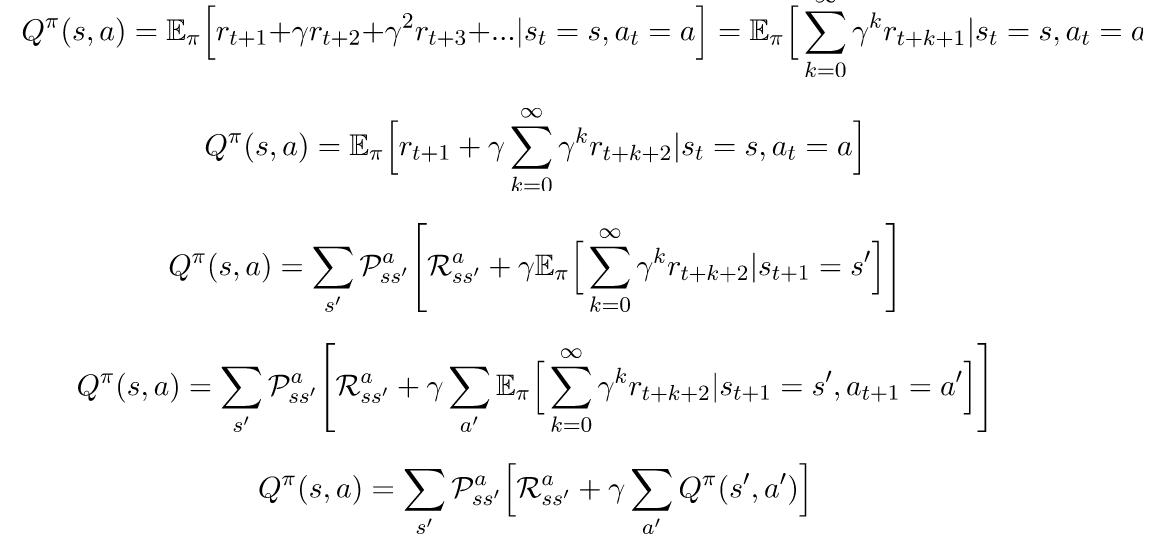
回报和返还(return)
正如前面所讨论的,强化学习agent如何最大化累积未来的回报。用于描述累积未来回报的词是返还,通常用R表示。我们还使用一个下标t来表示某个时间步长的返还。在数学符号中,它是这样的:
如果我们让这个级数趋于无穷,那么我们最终会得到无限的返还,这对于问题的定义并没有太大意义。因此,只有在我们期望返还的级数终止时,这个方程才有意义。我们将这种总是终止的任务称为“插曲式”(episodic)。纸牌游戏是解释“插曲式”问题的好例子。“插曲”开始于对每个人发牌,并且不可避免地会随着游戏规则的不同而结束。然后,下一“插曲”又开始了另一回合的游戏。相比使用未来的累积回报作为返还,更常见的是使用未来的累积折现回报(cumulative discounted reward):
其中0<γ<1。以这种方式定义返还的两个好处是,返还在无穷级数中得到了很好的定义,而且它把更大的权重给了更早的回报,这意味着我们更关心即将得到的回报,而不是将来会得到更多的回报。我们为γ选择的值越小就越正确。这种情况在我们让γ等于0或1时就可以看到。如果γ等于1,这个方程就变成了对所有的回报都同样的关心,无论在什么时候。另一方面,当γ等于0时,我们只关心眼前的回报,而不关心以后的回报。这将导致我们的算法极其短视。它将学会采取目前最好的行动,但不会考虑行动对未来的影响。策略
一个策略,写成π(s, a),描述了一种行动方式。它是一个函数,能够采取一个状态和一个行动,并返回在那个状态下采取这个行动的概率。因此,对于一个给定的状态,即
我们的策略应该描述如何在每个状态中采取行动,所以一个等概率的随机策略看起来就像我们在强化学习中的目标是学习一种最优策略,定义为
价值函数
为了学习最优策略,我们利用了价值函数。在强化学习中有两种类型的价值函数:状态值函数(state value function),用V(s)表示,和行动值函数,用Q(s,a)表示。
状态值函数在遵循策略时描述一个状态的值。当从状态的行为以我们的策略π开始时,这就是预期的返还。
需要注意的是,即使在相同的环境中,价值函数也会根据策略发生变化。这是因为状态的价值取决于你的行动,因为你在那个特定的状态下的行动会影响你期望看到的回报。同时还要注意期望的重要性。期望(expectation)就像一个平均值;它就是你期望看到的返还。我们使用期望的原因是当你到达一个状态后会发生一些随机事件。你可能有一个随机的策略,这意味着我们需要把我们采取的所有不同行动的结果结合起来。此外,转换函数(transition function)可以是随机的,也就是说,我们可能不会以100%的概率结束任何状态。请记住上面的例子:当你选择一个行动时,环境将返回下一个状态。即使给出一个行动,也可能会有多个状态返还。当我们看贝尔曼方程时,会看到更多这样的情况。期望将所有这些随机因素考虑在内。我们将使用的另一个价值函数是行动值函数。行动值函数告诉我们当跟随某个策略时,在某些状态下执行某个行动的值。给出状态和在π下的行动,这是期望的返还:
对状态值函数的注释同样适用于行动值函数。根据该策略,期望将考虑未来行动的随机性,以及来自环境的返还状态的随机性。
贝尔曼方程
理查德·贝尔曼推导出了以下公式,让我们可以开始解决这些马尔可夫决策问题。贝尔曼方程在强化学习中无处不在,对于理解强化算法的工作原理是非常必要的。但在我们了解贝尔曼方程之前,我们需要一个更有用的符号,定义为
最后,有了这些条件,我们就可以推导出贝尔曼方程了。我们将考虑贝尔曼方程的状态值函数。根据返还的定义,我们可以重写方程(1),如下所示:
如果我们从求和中得到第一个回报,我们可以这样重写它:这里的期望描述的是,如果我们继续遵循策略π的状态s,我们期望返还的是什么。通过对所有可能的行动和所有可能的返还状态的求和,可以明确地编写为期望。下面的两个方程可以帮助我们完成下一个步骤。通过在这两个部分之间分配期望,我们就可以把我们的方程转化成:注意,方程(1)与这个方程的末尾形式相同。我们可以替换它,得到:贝尔曼方程的行动值函数可以以类似的方式进行推导。本文结尾有具体过程,其结果如下:贝尔曼方程的重要性在于,它们让我们表达了其它状态的价值。这意味着,如果我们知道在我们推导出贝尔曼方程的过程中,我们得到了这一系列的方程,从方程(2)开始:

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消