










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
microsoft/focalnet-tiny


 英文
英文FocalNet(迷你型模型)
FocalNet模型是在ImageNet-1k数据集上训练的,分辨率为224x224。它是由杨等人在 Focal Modulation Networks 论文中提出,并于 this repository 首次发布。
声明:发布FocalNet的团队没有为该模型编写模型卡片,因此本模型卡片由Hugging Face团队撰写。
模型描述
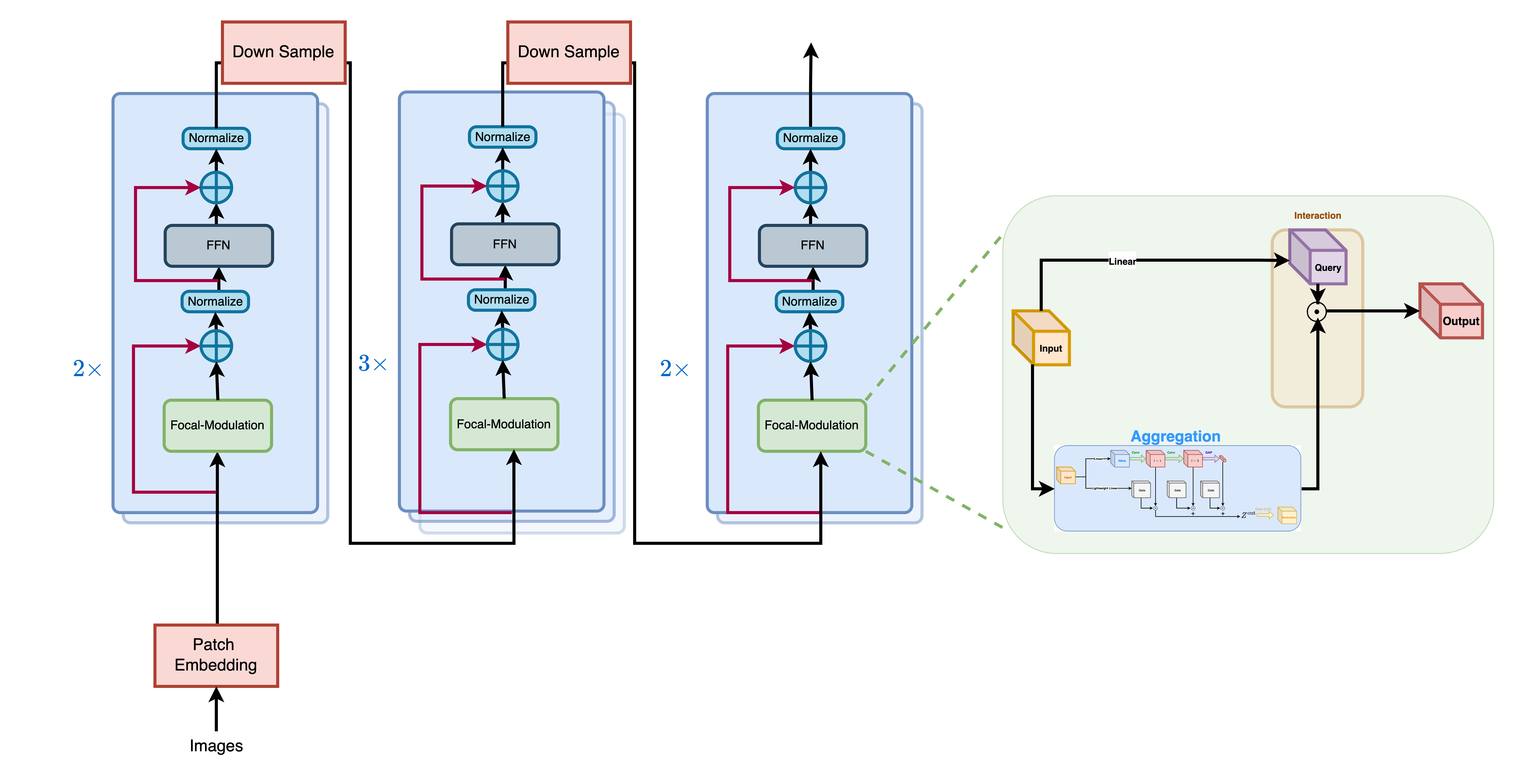
Focal Modulation Networks是Vision Transformers的一种替代方案,其中自注意力(SA)完全被聚焦调制机制替代,用于模拟图像中的令牌交互。聚焦调制包括三个组成部分:(i)分层上下文建模,使用一系列深度卷积层实现,从短到长范围编码视觉上下文,(ii)门控聚合,根据令牌内容有选择性地收集每个查询令牌的上下文,并且(iii)元素调制或仿射变换,将聚合的上下文注入查询。大量实验证明,FocalNet在图像分类、目标检测和分割等任务上的性能优于最先进的SA对应方法(例如,Vision Transformers、Swin和Focal Transformers),而计算成本相似。
预期用途和限制
您可以使用原始模型进行图像分类。查看 model hub 以查找您感兴趣的任务的微调版本。
如何使用
使用此模型将COCO 2017数据集中的图像分类为1,000个ImageNet类别的步骤如下:
from transformers import FocalNetImageProcessor, FocalNetForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = FocalNetImageProcessor.from_pretrained("microsoft/focalnet-tiny")
model = FocalNetForImageClassification.from_pretrained("microsoft/focalnet-tiny")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
更多代码示例,请参阅 documentation 。
BibTeX条目和引用信息
@article{DBLP:journals/corr/abs-2203-11926,
author = {Jianwei Yang and
Chunyuan Li and
Jianfeng Gao},
title = {Focal Modulation Networks},
journal = {CoRR},
volume = {abs/2203.11926},
year = {2022},
url = {https://doi.org/10.48550/arXiv.2203.11926},
doi = {10.48550/arXiv.2203.11926},
eprinttype = {arXiv},
eprint = {2203.11926},
timestamp = {Tue, 29 Mar 2022 18:07:24 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2203-11926.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}