模型:
facebook/wav2vec2-xls-r-1b-en-to-15



 英文
英文Wav2Vec2-XLS-R-1B-EN-15
Facebook's Wav2Vec2 XLS-R用于语音翻译的Fine-tuned模型。

这是一个 SpeechEncoderDecoderModel 模型。编码器从 facebook/wav2vec2-xls-r-1b 检查点开始进行热启动,解码器从 facebook/mbart-large-50 检查点开始。因此,编码器-解码器模型在15个en-> {lang}的翻译对上进行了Fine-tuned。
该模型可以将从口语en(英语)翻译为以下书面语言{lang}:
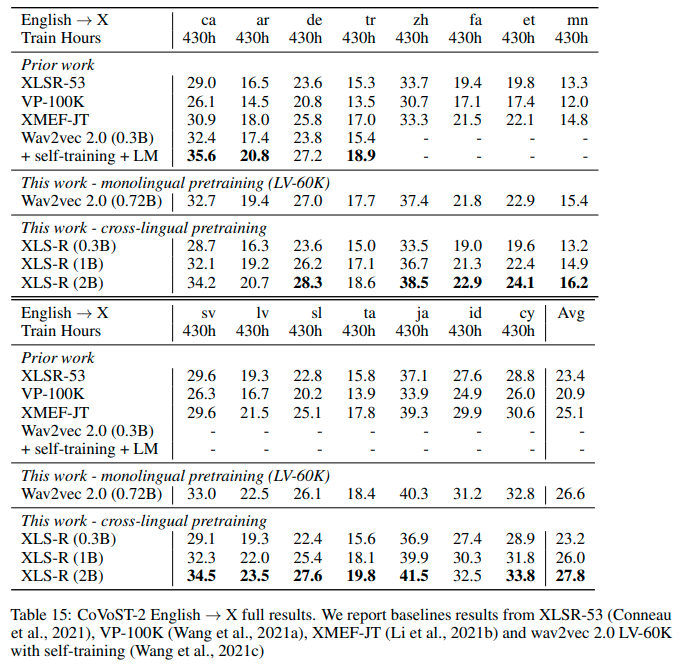
en-> { de, tr, fa, sv-SE, mn, zh-CN, cy, ca, sl, et, id, ar, ta, lv, ja }
有关更多信息,请参见 official XLS-R paper 的第5.1.1节。
用法
演示
可以在 this space 上测试该模型。您可以选择目标语言,在英语中录制一些音频,然后坐下来看看检查点能够多好地翻译输入。
例子
由于这是一个标准的sequence to sequence transformer模型,您可以使用“生成”方法通过将语音特征传递给模型来生成转录文本。
您可以通过使用ASR流程直接使用该模型。默认情况下,检查点将口语英语翻译为德语书面语。要更改书面目标语言,您需要将正确的forced_bos_token_id传递给generate(...),以使解码器条件化于正确的目标语言。
要根据所选语言ID选择正确的forced_bos_token_id,请使用以下映射:
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
例如,如果要将其翻译为瑞典语,可以执行以下操作:
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-1b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
或者逐步按以下方式进行:
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
结果en-> {lang}
有关此模型在 Covost2 上的性能,请参见XLS-R(1B)的行。