

















模型:
facebook/sam-vit-large

 英文
英文Segment Anything Model (SAM) - ViT Large (ViT-L)版本的模型卡片
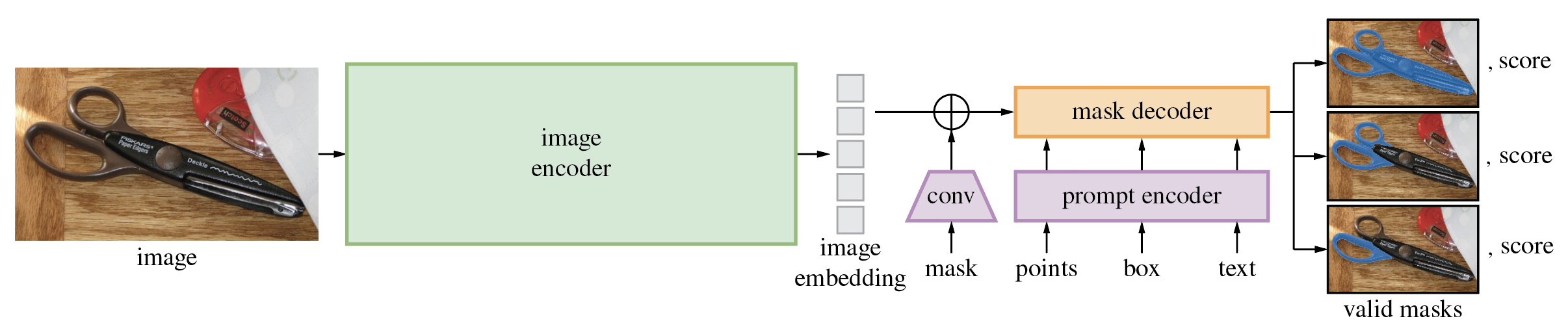 Segment Anything Model (SAM)的详细架构。
Segment Anything Model (SAM)的详细架构。
目录
TL;DR


Segment Anything模型(SAM)可以根据输入的提示(如点或框)生成高质量的对象掩码,并可用于生成图像中所有对象的掩码。它已在1100万图像和110亿个掩码的数据集上进行了训练,并且在各种分割任务上具有较强的零样本性能。论文的摘要如下:
我们引入了Segment Anything(SA)项目: 一项新的图像分割任务、模型和数据集。使用我们的高效模型在数据收集循环中,我们构建了迄今为止最大的分割数据集,其中包含1100万受许可且尊重隐私的图像上的超过10亿个掩码。该模型经过设计和训练,可以根据提示进行转移学习,适应新的图像分布和任务。我们评估了它在许多任务上的能力,并发现它的零样本性能令人印象深刻,往往与之前的全监督结果相当甚至更好。为了促进计算机视觉基础模型的研究,我们发布了Segment Anything模型(SAM)和相应的数据集(SA-1B),其中包含10亿个掩码和1100万张图像,网址为 https://segment-anything.com 。
免责声明: 该模型卡片的内容由Hugging Face团队撰写,并且其中的部分内容来自原始 SAM model card 。
模型细节
SAM模型由3个模块组成:
- VisionEncoder: 基于VIT的图像编码器。它使用图像的补丁进行注意力计算以获得图像嵌入。使用相对位置嵌入。
- PromptEncoder: 为点和边界框生成嵌入。
- MaskDecoder: 双向Transformer,它在图像嵌入和点嵌入之间进行交叉注意力计算,并输出。
- Neck: 根据MaskDecoder产生的上下文掩码预测输出掩码。
使用方法
提示掩码生成
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("facebook/sam-vit-large")
processor = SamProcessor.from_pretrained("facebook/sam-vit-large")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D localization of a window
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
除了生成掩码的其他参数,您还可以传递对象感兴趣区域的二维位置、包围对象感兴趣区域的边界框(格式应为边界框的右上和左下点的x、y坐标)和分割掩码。根据 the official repository 的官方模型,目前尚不支持传入文本作为输入。更多细节,请参考这个笔记本,其中展示了如何使用模型的步骤以及一个视觉示例!
自动掩码生成
该模型可以用于以“零样本”方式生成分割掩码,给定输入图像。模型会自动使用1024个点的网格进行提示。
该流程用于自动生成掩码。以下代码片段演示了如何简单地运行它(在任何设备上运行!只需提供适当的points_per_batch参数)
from transformers import pipeline
generator = pipeline("mask-generation", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
现在来显示图片:
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
引用
如果您使用了这个模型,请使用以下BibTeX条目进行引用。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}