

















模型:
deepmind/multimodal-perceiver
其他:
perceiver许可:
 apache-2.0
apache-2.0
 英文
英文Perceiver IO多模态自编码
Perceiver IO模型在 Kinetics-700-2020 上进行训练,用于对包含图像、音频和类别标签的视频进行自编码。该模型由Jaegle等人在 Perceiver IO: A General Architecture for Structured Inputs & Outputs 的论文中提出,并在 this repository 首次发布。
多模态自编码的目标是学习一个能够在架构引起的瓶颈下准确重构多模态输入的模型。
免责声明:发布Perceiver IO的团队没有为该模型撰写模型卡,因此此模型卡是由Hugging Face团队撰写的。
模型描述
Perceiver IO是一个可以应用于任何模态(文本、图像、音频、视频等)的Transformer编码模型。其核心思想是在一组不太大的潜向量(例如256或512)上使用自注意机制,并只使用输入与潜向量进行交叉注意。这样可以使自注意机制的时间和内存需求不依赖于输入的大小。
为了解码,作者使用所谓的解码器查询,它们允许灵活地解码潜向量的最终隐藏状态,以产生任意大小和语义的输出。对于多模态自编码,输出包含三种模态的重构:图像、音频和类别标签。
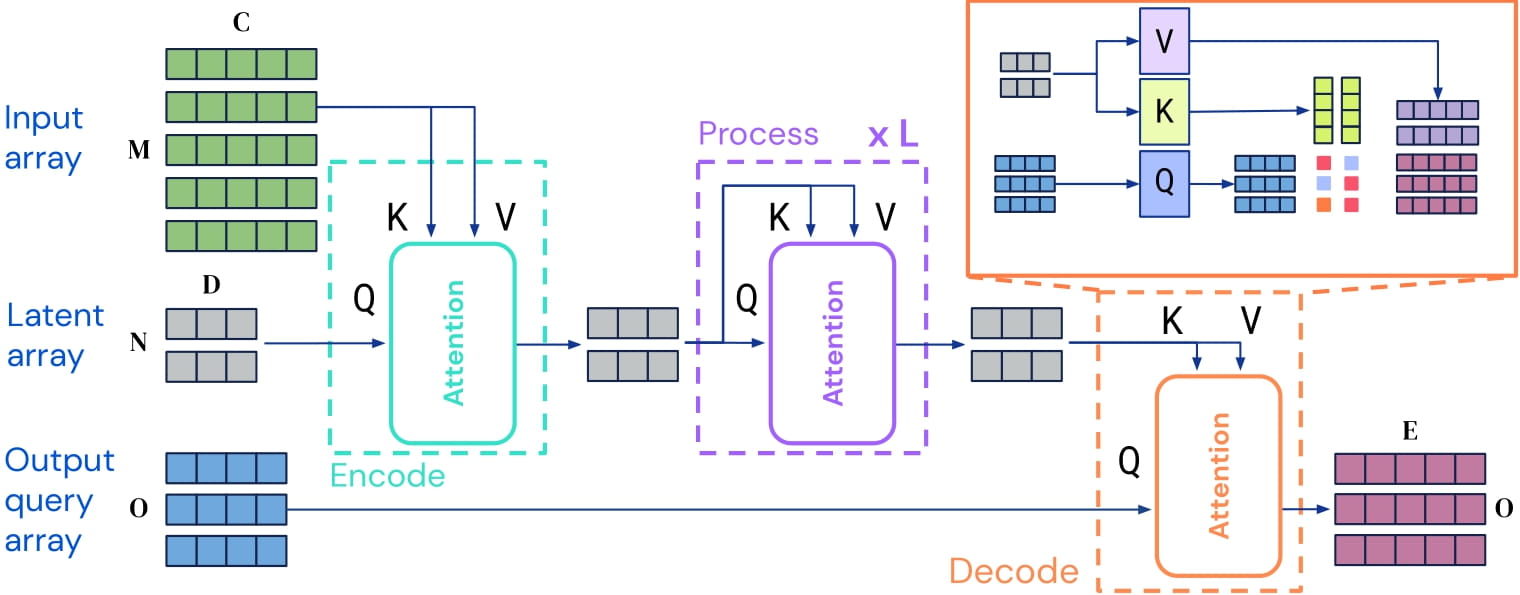
Perceiver IO架构。
由于自注意机制的时间和内存需求不依赖于输入的大小,Perceiver IO的作者可以通过使用模态特定嵌入将输入(图像、音频、类别标签)进行填充,并将所有输入串行化为2D输入数组(即沿时间维度进行连接)。通过使用包含基于傅里叶的位置嵌入(用于视频和音频)和模态嵌入的查询来解码潜向量的最终隐藏状态。
预期用途和限制
您可以将原始模型用于多模态自编码。请注意,在评估过程中屏蔽类别标签,自编码模型将变成视频分类器。
请参阅[模型中心]( https://huggingface.co/models search=deepmind/perceiver)以查找您可能感兴趣的任务的其他版本。
使用方法
有关使用Perceiver进行多模态自编码的详细信息,请参阅 tutorial notebook 。
训练数据
该模型在 Kinetics-700-200 上进行了训练,该数据集包含属于700个类别之一的视频。
训练过程
预处理
作者对16帧的224x224分辨率进行训练,预处理为50k个4x4补丁,以及30k个原始音频样本,补丁成一共1920个16维向量和一个700维独热表示的类别标签。
预训练
超参数详细信息可在 paper 的附录F中找到。
评估结果
有关评估结果,请参阅 paper 的表5。
BibTeX条目和引用信息
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}