

















模型:
beomi/kcbert-base



 英文
英文KcBERT: 韩语评论BERT
** 2021.04.07 更新 **
- 发布了KcELECTRA!🤗
- KcELECTRA在所有任务中都比KcBERT表现更好,这源于更多的数据集和更大的通用vocab。
- 欢迎在下面的GitHub链接中尝试使用!
- https://github.com/Beomi/KcELECTRA
** 2021.03.14 更新 **
- 添加了对KcBERT Paper的引用(bibtex)
- 在正文中添加了KcBERT微调性能分数。
** 2020.12.04 更新 **
随着Huggingface Transformers更新到v4.0.0,教程中的代码也有所更改。
更新后的KcBERT-Large NSMC微调Colab链接:
![]()
** 2020.09.11 更新 **
我们提供了在Google Colab中使用TPU对KcBERT进行训练的教程!请点击下面的按钮。
在Colab上用TPU对KcBERT进行预训练:
![]()
我们使用了一个小块(144MB)的部分文本数据来进行训练,以便更方便地使用韩语数据集/语料库。
我们使用了一个名为 Korpora 的包来更轻松地使用韩语数据集/语料库。
** 2020.09.08 更新 **
我们通过Github Release上传了训练数据。
由于每个文件的大小限制为2GB,所以已进行了分割压缩。
请通过以下链接下载数据(不需要注册即可下载,分割为多个压缩文件)
如果您想要一个文件或者想在Kaggle上查看数据,请使用下面的Kaggle数据集。
** 2020.08.22 更新 **
公开Pretrain Dataset
我们在Kaggle上发布了经过清理(下面的 clean 处理)的数据集,供您进行训练!
公开的韩语BERT大多基于经过精心清理的数据集,例如韩语维基,新闻文章和书籍等。然而,像NSMC这样的评论数据集未经过处理,其中有很多口语和网络用语,拼写错误等表达。
为了适应这类数据集,KcBERT从Naver新闻中收集了评论和回复,从头开始训练了分词器和BERT模型。
您可以使用Huggingface的Transformers库轻松地加载和使用KcBERT模型(无需单独下载文件)。
KcBERT性能
- 可在 https://github.com/Beomi/KcBERT-finetune 中找到微调代码。
| Size (용량) | NSMC (acc) | Naver NER (F1) | PAWS (acc) | KorNLI (acc) | KorSTS (spearman) | Question Pair (acc) | KorQuaD (Dev) (EM/F1) | |
|---|---|---|---|---|---|---|---|---|
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
*HanBERT大小为Bert模型和Tokenizer数据库的总和。
* 根据config的设置运行的结果,可以进一步进行超参数调整以获得更好的性能。
如何使用
要求
- pytorch <= 1.8.0
- transformers ~= 3.0.1
- transformers ~= 4.0.0 也可以兼容。
- emoji ~= 0.6.0
- soynlp ~= 0.0.493
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
Pretrain & Finetune Colab链接
Pretrain 数据 Pretrain 代码 可以在Colab上通过TPU进行KcBERT预训练:
![]()
用PyTorch-Lightning在KcBERT-Base上对NSMC进行微调(Colab):
![]()
用PyTorch-Lightning在KcBERT-Large上对NSMC进行微调(Colab):
![]()
上述示例仅在预训练模型(基本还是大)和批量大小不同的情况下有所区别,其他代码完全相同。
训练数据和预处理
原始数据
训练数据是从2019年1月1日至2020年6月15日之间发布的新闻文章中收集的评论数据和回复。
数据大小在提取文本后约为15.4GB,并包含超过1.1亿个句子。
预处理
进行PLM训练的预处理过程如下:
韩语和英语,特殊字符,以及表情符号(🥳)!
我们使用正则表达式将韩语、英语、特殊字符和表情符号(Emoji)都包含在了训练中。
鉴于韩语的范围,我们将范围限定为 ㄱ-ㅎ가-힣 ,排除了 ㄱ-힣 范围内的汉字。
缩写评论中的重复字符串
我们将像 ㅋㅋㅋㅋ 这样的重复字符缩写为 ㅋㅋ 。
区分大小写模型
KcBERT对英文保持大小写的cased模型。
删除10个字符以下的文字
由于10个字符以下的文本通常是由单个单词组成的,我们将其剔除。
删除重复评论
为了删除重复评论,我们将重复的评论合并为一个。
通过以上步骤得到的最终训练数据大小为12.5GB,包含890万个句子。
请按照下面的命令安装pip,并使用下面的clean函数来清理文本数据(以减少[UNK]的数量)。
pip install soynlp emoji
请在文本数据上使用下面的clean函数。
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
清理后的数据(在Kaggle上发布)
您可以在下面的Kaggle数据集中下载经过清理(用下面的clean处理)的原始数据(12GB)的txt文件:
https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments
分词器训练
我们使用Huggingface的 Tokenizers 库进行分词器训练。
我们使用BertWordPieceTokenizer进行训练,词汇表大小设置为30000。
在训练分词器时,我们对1/10的采样数据进行了采样,并在分层抽样的基础上按日期分层进行了采样,以保持样本的平衡。
BERT模型预训练
- KcBERT Base 配置
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
- KcBERT Large 配置
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
BERT模型配置与Base和Large的默认设置相同(MLM 15%等)。
我们使用TPU v3-8进行训练,每个模型训练了3天和N天(Large模型训练期间),Huggingface上公开的模型是训练了100万步的ckpt。
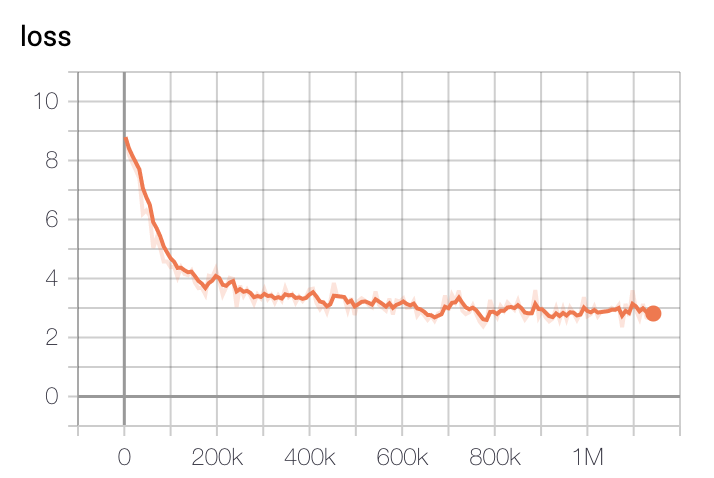
模型训练的Loss在步骤上,最开始的20万步会迅速减小,然后在40万步后略有下降。
- Base模型Loss
- Large模型Loss
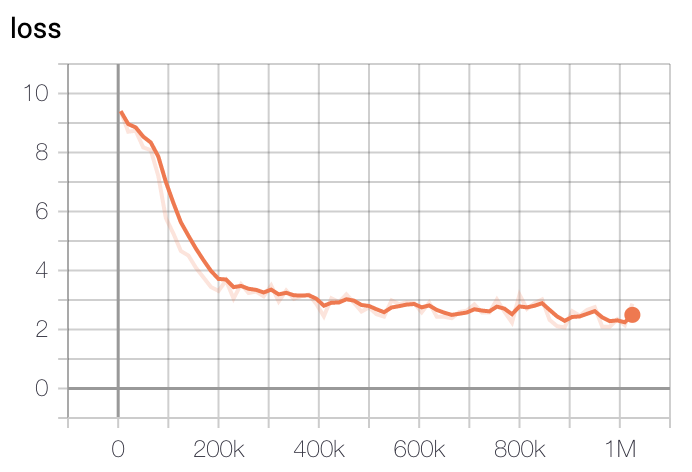
我们使用GCP的TPU v3-8进行了模型训练,基础模型训练时间约为2.5天。Large模型在训练了大约5天后选择了具有最低Loss的checkpoint。
示例
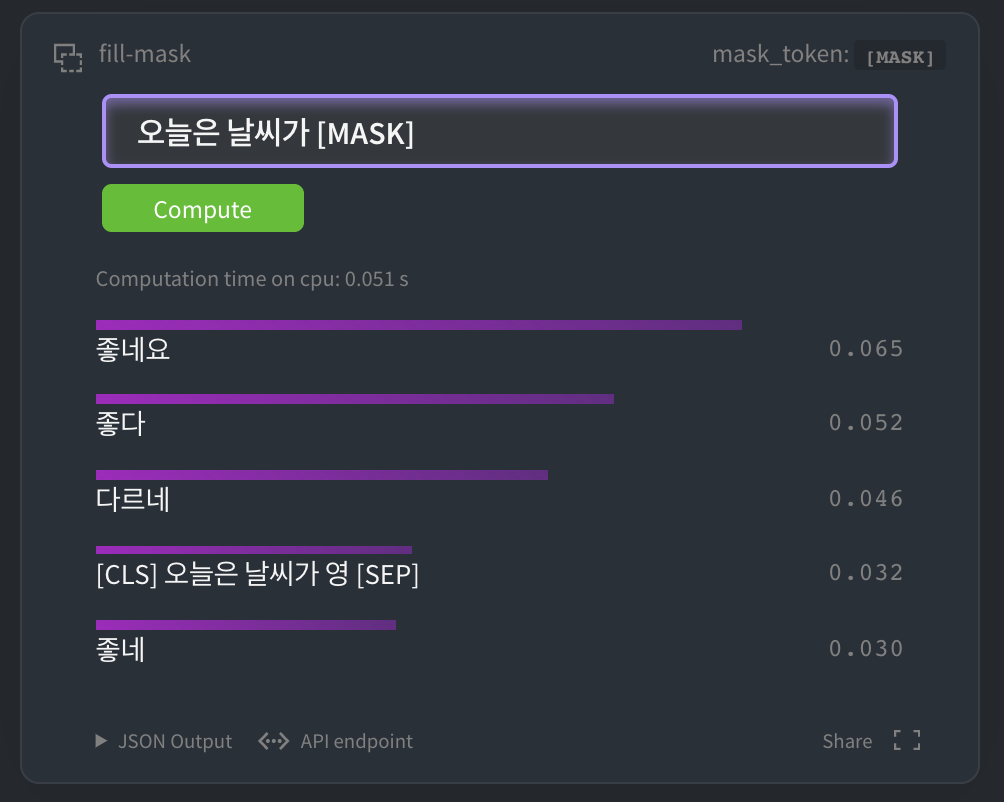
HuggingFace MASK LM
您可以在 HuggingFace kcbert-base 모델 中尝试以下内容:
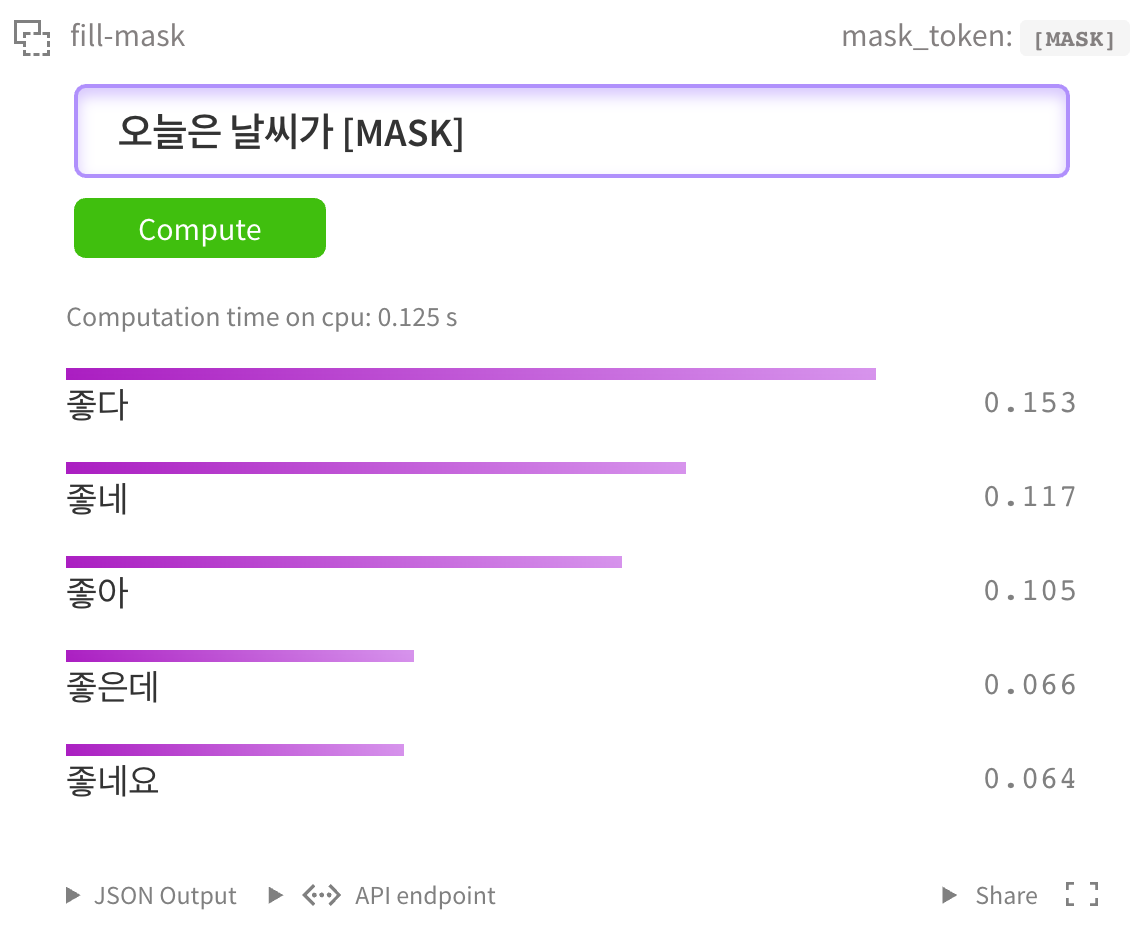
当然,您也可以在 kcbert-large 모델 中进行测试。
NSMC二分类
我们对 네이버 영화평 코퍼스 数据集进行了微调以进行简单的性能测试。
您可以在KcBERT-Base上运行Fine Tune的代码为
![]() 。
。
您可以在KcBERT-Large上运行Fine Tune的代码为
![]() 。
。
- GPU(P100 x1)每个epoch需要2-3个小时,TPU每个epoch需要1个小时以内。
- GPU(RTX Titan x4)每个epoch需时大约30分钟。
- 示例代码已在 pytorch-lightning 上开发。
-
KcBERT-Base模型实验结果:验证准确度 .8905

-
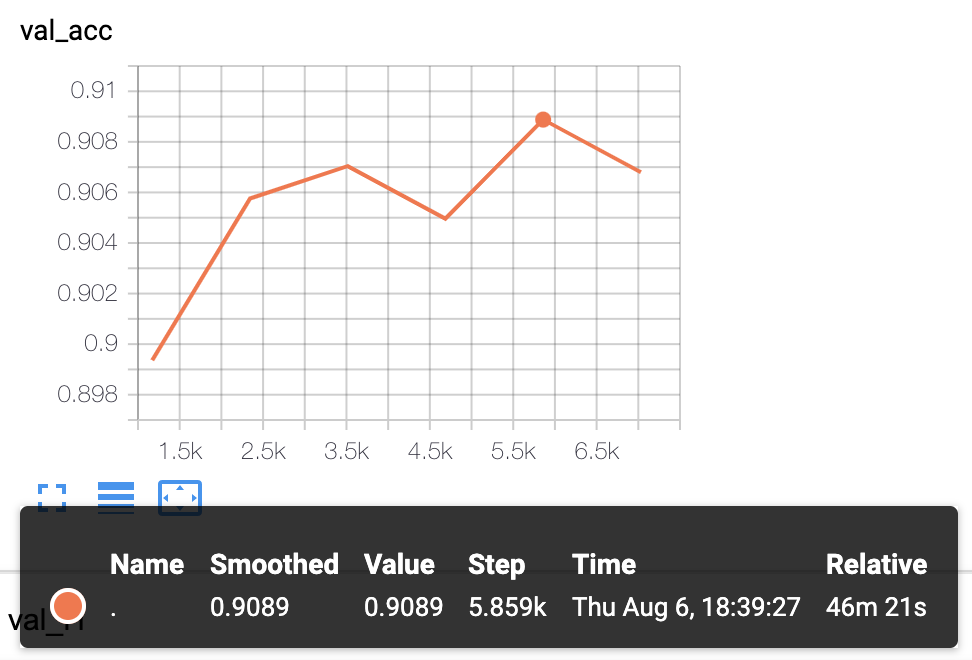
KcBERT-Large模型实验结果:验证准确度 .9089
我们计划在更多的Downstream Task中进行测试并进行公开。
引用/Citation
当引用KcBERT时,请使用以下格式进行引用。
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
- 论文下载链接: http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (* 或者 http://hclt.kr/symp/?lnb=conference )
致谢
训练KcBERT模型时使用了GCP/TPU环境,获得了 TFRC 计划的支持。
感谢 Monologg 先生在模型训练过程中提供的许多建议 :)