



















 英文
英文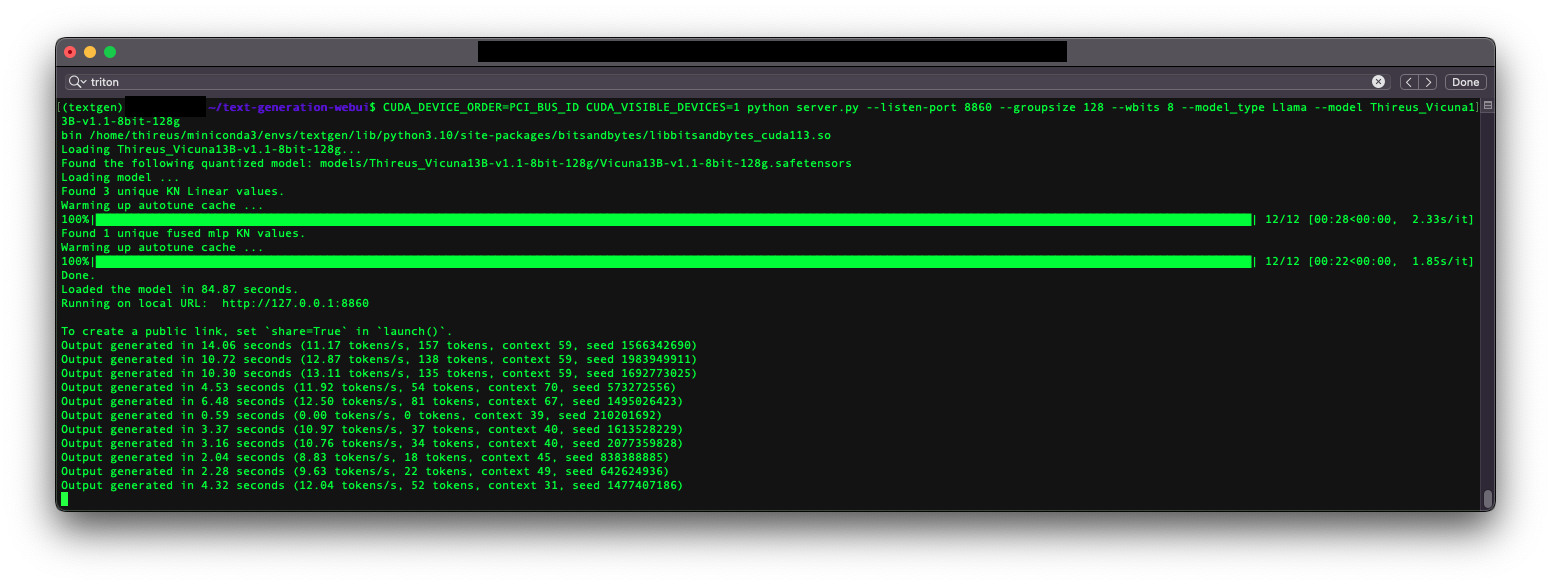
这是Vicuna 13B v1.1 HF的8位GPTQ版本(请勿与8位RTN混淆)。
问:为什么采用8位量化而不是4位?答:用于评估目的。理论上,8位量化模型应该在困惑度上略微优于4位量化版本(可能不明显-待评估...)。如果您的GPU VRAM可用内存超过15GB,您可能想尝试一下。请注意,8位量化不意味着以8位精度加载模型。以8位精度加载模型(--load-in-8bit)会导致感知质量(困惑度)下降。
参考文献:
- https://github.com/ggerganov/llama.cpp/pull/951
- https://news.ycombinator.com/item?id=35148542
- https://github.com/ggerganov/llama.cpp/issues/53
- https://arxiv.org/abs/2210.17323
- https://arxiv.org/abs/2105.03536
- https://arxiv.org/abs/2212.09720
- https://arxiv.org/abs/2301.00774
- https://github.com/IST-DASLab/gptq
该模型是Vicuna 13B v1.1的8位量化版本。
- 13B参数
- 组大小:128
- wbits:8
- 真实顺序:是
- 激活函数顺序:是
- 8位GPTQ
- c4
- 转换过程:LLaMa 13B -> LLaMa 13B HF -> Vicuna13B-v1.1 HF -> Vicuna13B-v1.1-8bit-128g
基准测试
使用 https://github.com/qwopqwop200/GPTQ-for-LLaMa/ 进行测试。最佳结果以粗体显示。
--benchmark 2048 --check结果:
| Model | wikitext2 PPL | ptb PPL | c4 PPL | VRAM Utilization |
|---|---|---|---|---|
| 4bit-GPTQ - TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g | 8.517391204833984 | 20.888103485107422 | 7.058407783508301 | 8670.26953125 |
| 8bit-GPTQ - Thireus/Vicuna13B-v1.1-8bit-128g | 8.508771896362305 | 20.75649070739746 | 7.105874538421631 | 14840.26171875 |
--eval结果:
| Model | wikitext2 PPL | ptb PPL | c4 PPL |
|---|---|---|---|
| 4bit-GPTQ - TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g | 7.119165420532227 | 25.692861557006836 | 9.06746768951416 |
| 8bit-GPTQ - Thireus/Vicuna13B-v1.1-8bit-128g | 6.988043308258057 | 24.882535934448242 | 8.991846084594727 |
--new-eval --eval结果:
| Model | wikitext2 PPL | ptb-new PPL | c4-new PPL |
|---|---|---|---|
| 4bit-GPTQ - TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g | 7.119165420532227 | 35.637290954589844 | 9.550592422485352 |
| 8bit-GPTQ - Thireus/Vicuna13B-v1.1-8bit-128g | 6.988043308258057 | 34.264320373535156 | 9.426002502441406 |
PPL = 困惑度(值越低越好)- https://huggingface.co/docs/transformers/perplexity
基本安装过程
- 简直是一场噩梦,我只会简要地详述你需要什么。解决WSL问题相当痛苦。我无法提供安装支持,抱歉。您当然可以使用支持8位量化的llama.cpp和其他加载程序,我只是选择了oobabooga/text-generation-webui。在text-generation-webui加载之前,您可能会遇到许多错误,范围从缺少PATH或环境变量到必须手动pip卸载/安装软件包。下面的备注可能会在text-generation-webui和GPTQ-for-LLaMa都获得适当的错误修复后过时。如果该模型生成非常慢的答案(每秒1个令牌),则表示您没有使用Cuda来进行位操作,或者您的硬件需要升级。如果该模型生成带有奇怪字符的答案,则表示您正在使用qwopqwop200/GPTQ-for-LLaMa的错误提交。如果该模型生成超出主题范围的答案或者它自言自语,则表示您正在使用qwopqwop200/GPTQ-for-LLaMa的错误提交。
推荐 - Triton(每秒令牌数快) - 在Windows上通过WSL(我使用的方式)或Linux工作:
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui #git fetch origin pull/1229/head:triton # Since been merged # This is the version that supports Triton - https://github.com/oobabooga/text-generation-webui/pull/1229 git checkout triton pip install -r requirements.txt mkdir repositories cd repositories git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa.git # -b cuda cd GPTQ-for-LLaMa #git checkout 508de42 # Since been fixed # Before qwopqwop200 broke everything... - https://github.com/qwopqwop200/GPTQ-for-LLaMa/issues/183 git checkout 210c379 # Optional - This is a commit I have verified, you may want to try the latest commit instead, if the latest commit doesn't work revert to an older one such as this one pip install -r requirements.txt
不推荐 - Cuda(每秒令牌数慢)和输出问题 https://github.com/qwopqwop200/GPTQ-for-LLaMa/issues/128 :
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui pip install -r requirements.txt mkdir repositories cd repositories git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa.git -b cuda # Make sure you obtain the qwopqwop200 version, not the oobabooga one! (because "act-order: yes") cd GPTQ-for-LLaMa git checkout 505c2c7 # Optional - This is a commit I have verified, you may want to try the latest commit instead, if the latest commit doesn't work revert to an older one such as this one pip install -r requirements.txt python setup_cuda.py install
测试详细信息和演示
oobabooga的最新版本+ https://github.com/oobabooga/text-generation-webui/pull/1229
NVIDIA GTX 3090
32GB DDR4
i9-7980XE OC @4.6Ghz
平均每秒11个令牌(使用Triton)
与4位版本相同的平均每秒令牌数
待初步观察:在VRAM使用率增加71%的情况下,比8位RTN/--load-in-8bits有更好的质量结果(待确认)
观察结果:比4位GPTQ有更好的质量结果(参见上述PPL基准测试),但需要更多VRAM
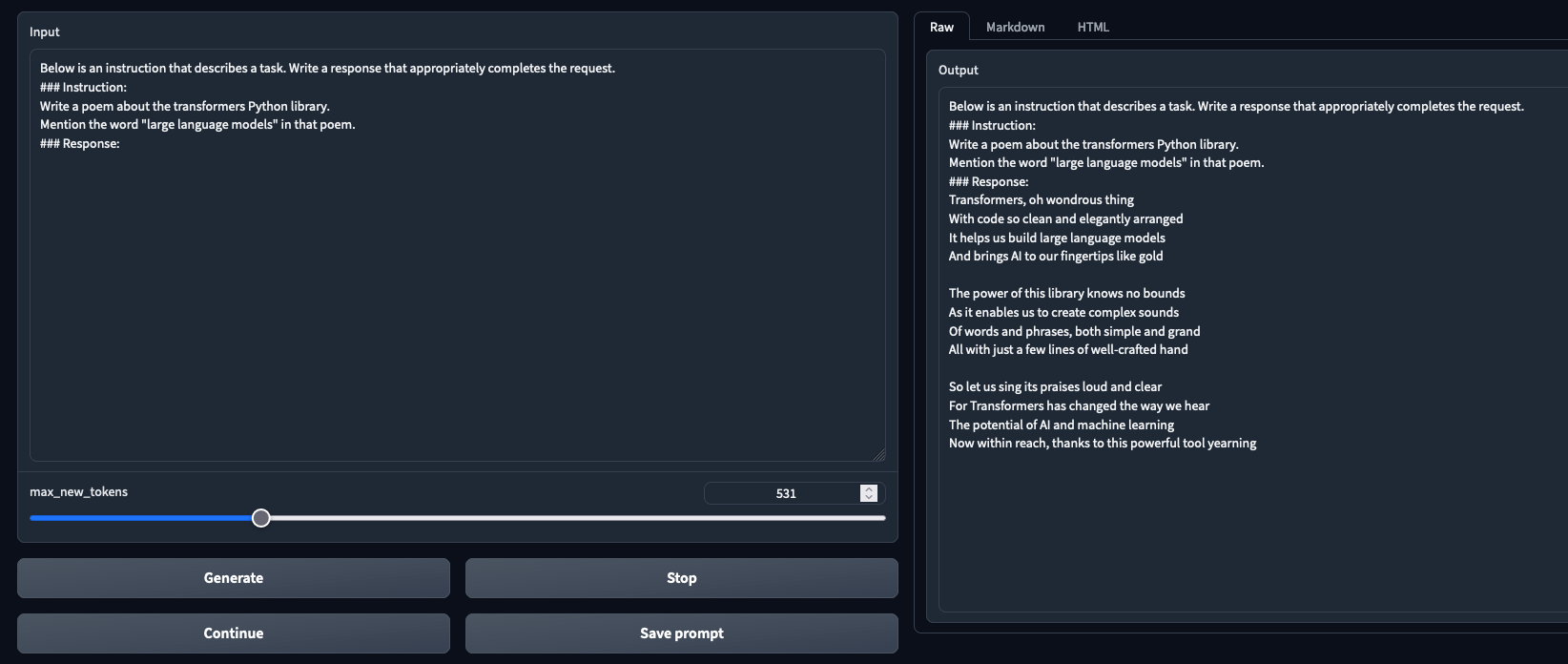
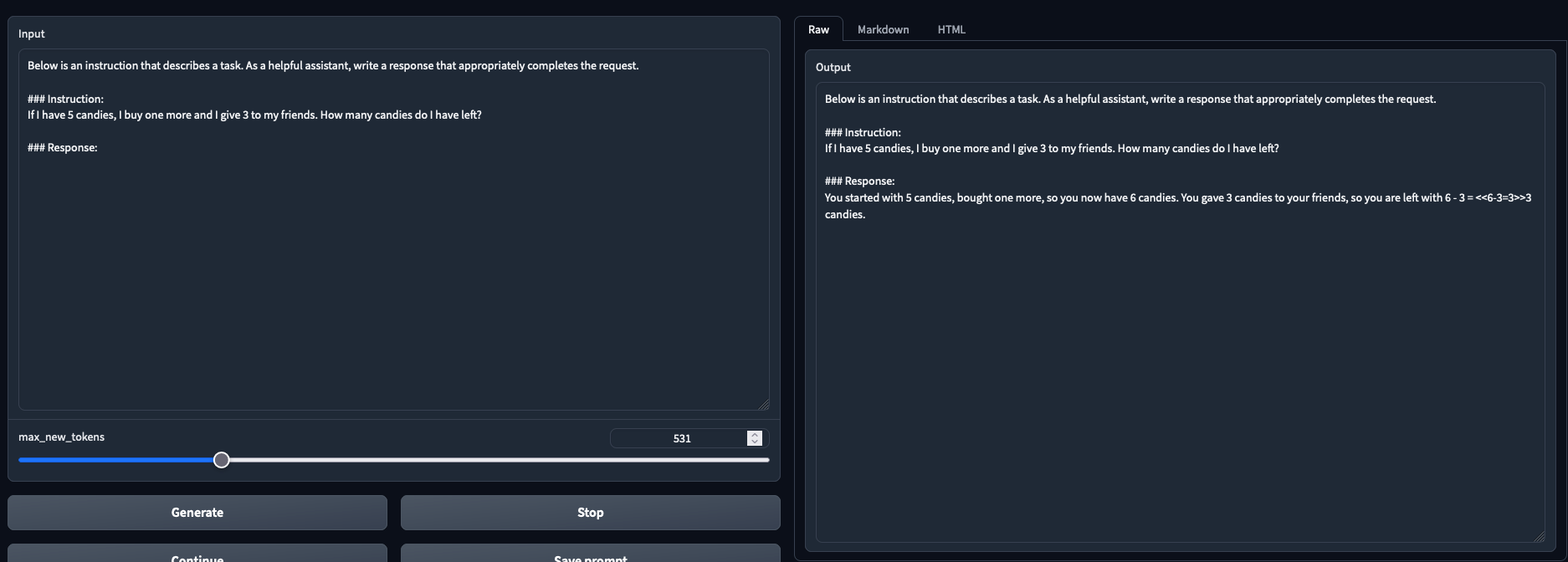
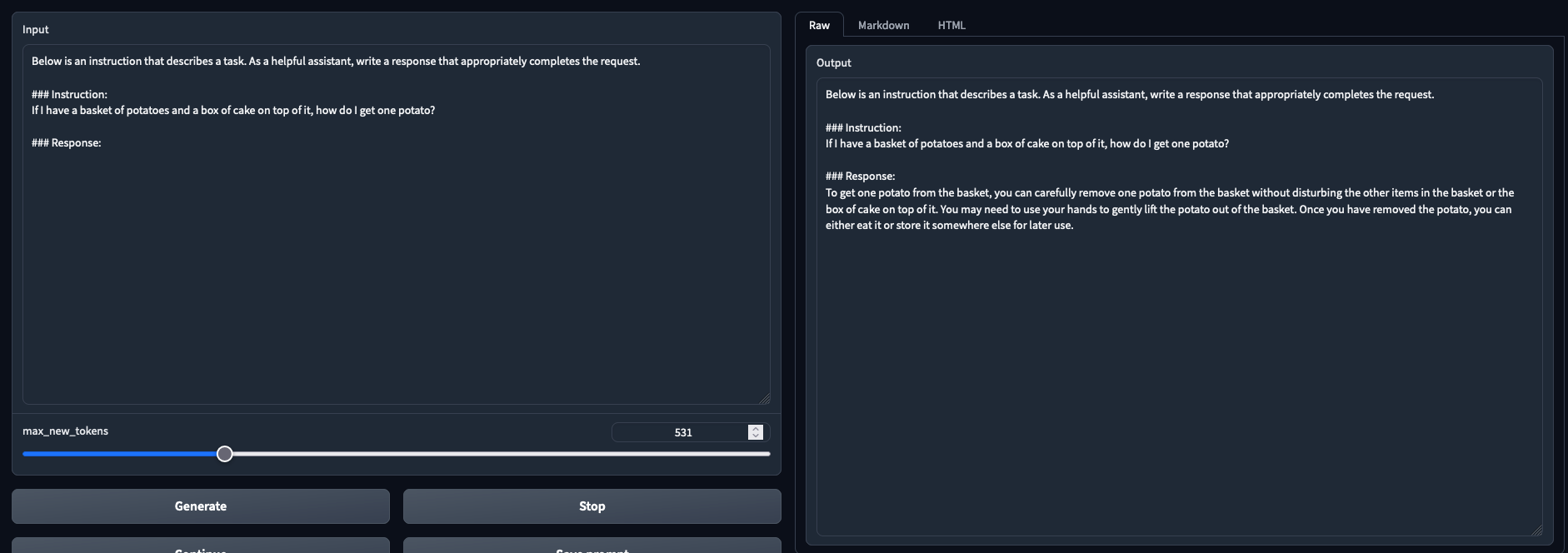
在聊天模式和文本生成模式下经过测试并正常工作

许可协议
仅供研究-仅限非商业研究目的-其他限制适用。有关详细信息,请参阅LLaMa继承的LICENSE文件。
将LLaMA-13B转换为与Transformers/HuggingFace配合使用的特殊许可证,请参阅LICENSE文件以了解详情。
https://www.reddit.com/r/LocalLLaMA/comments/12kl68j/comment/jg31ufe/
Vicuna模型卡
模型详细信息
模型类型:Vicuna是一个开源聊天机器人,通过在从ShareGPT收集到的用户共享的对话上进行LLaMA的微调进行训练。它是基于变压器架构的自回归语言模型。
模型日期:Vicuna的训练时间为2023年3月至2023年4月。
开发模型的组织:Vicuna团队,成员来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校。
有关更多信息的论文或资源: https://vicuna.lmsys.org/
许可证:Apache许可证2.0
有关模型的问题或评论的发送位置: https://github.com/lm-sys/FastChat/issues
预期用途
主要预期用途:Vicuna的主要用途是用于大型语言模型和聊天机器人的研究。
主要预期用户:该模型的主要预期用户是自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
训练数据集
从ShareGPT.com收集的70K个对话。
评估数据集
通过创建一组80个不同的问题,并利用GPT-4对模型输出进行评估,对模型质量进行了初步评估。有关更多细节,请参见 https://vicuna.lmsys.org/ 。
权重v1.1的主要更新
- 重新设计了标记化和分隔符。在Vicuna v1.1中,分隔符已从"###"更改为EOS标记""。此更改使确定生成停止标准变得更容易,并更好地与其他库兼容。
- 修复了有监督的微调损失计算,以提高模型质量。