


















Anthropic开源工具以追踪大型语言模型的“思维”
Anthropic的研究人员已经将他们的工具开源该工具用于追踪大型语言模型在推理过程中的内部运作。它包括一个电路追踪Python库,可以与任何开源权重模型一起使用,并通过Neuropedia托管的前端,以图形方式探索库的输出。
正如InfoQ报道的在Anthropic最初披露时,他们揭示LLM内部行为的方法涉及用另一个模型替换实际模型,该模型使用稀疏激活特征,这些特征来自跨层MLP转码器而不是原始神经元。通常,这些特征可以代表可解释的概念,使得可以通过修剪掉所有不影响调查输出的特征来构建一个归因图。
Anthropic的电路追踪库可以识别替换电路,并使用预训练的转码器从给定模型生成归因图。
它计算每个非零转码器特征、转码器错误节点和输入标记对其他非零转码器特征和输出logit的直接影响[编者注:模型在应用概率函数如softmax之前分配给每个可能输出的原始(非归一化)分数]。
正如Anthropic的一位研究人员在Hacker News上指出,图形揭示了模型在采样标记时采取的中间计算步骤,这可以提供有用的见解。这些见解可以用于操纵转码器特征并观察模型输出的变化。
Anthropic已经使用其电路追踪器研究了Gemma-2-2b和Llama-3.2-1b中的多步骤推理和多语言表示。以下是为提示“事实:包含达拉斯的州的首都是”生成的归因图示例。在一个
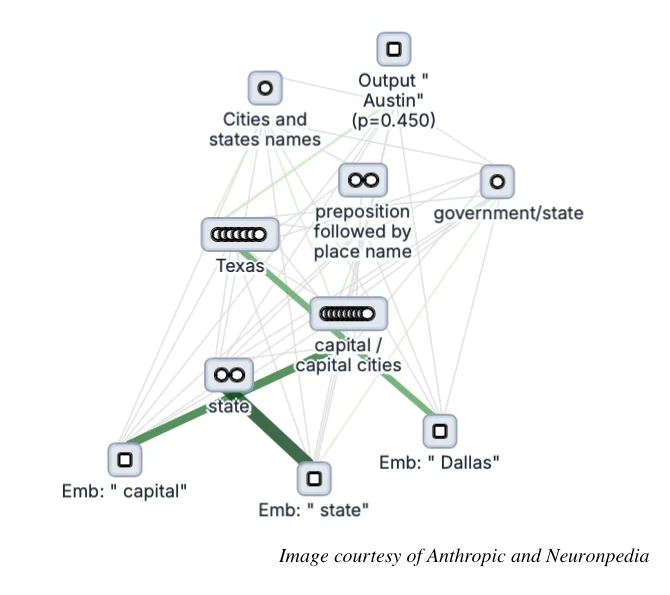
由Dwarkesh Patel主持的长篇播客中,特邀嘉宾包括Anthropic的Trenton Bricken和Sholto Douglas,Bricken解释了Anthropic在电路追踪方面的研究是LLM机械解释性的重要贡献,即努力理解LLM内部的核心计算单元是什么。这建立在使用玩具模型、然后是稀疏自编码器,最终是电路的先前研究基础上。
现在你正在识别模型各层中一起工作的个别特征,以执行一些复杂的任务。你可以更好地了解它实际上是如何进行推理和做出决策的
这仍然是一个非常年轻的领域,但对于LLM的安全使用来说,变得越来越关键:
取决于AI加速的速度和我们工具的状态,我们可能无法从头到尾证明一切都是安全的。但我觉得这是一个非常好的北极星。对于我们来说,这是一个非常有力的、令人安心的北极星,尤其是当我们考虑到我们是更广泛的AI安全组合的一部分时
电路追踪库可以很容易地从Anthropic的教程笔记本中运行。或者,你可以在Neuronpedia上使用它或本地安装它。









