


















【指南】使用Dask构建端到端数据管道

数据是企业获取竞争优势的重要资产。随着技术的进步,收集和存储数据变得更加容易。然而,数据的丰富性也带来了处理上的挑战,因为数据量越大,处理速度就越慢。
为了提升数据处理能力,有多种工具可以提供帮助,其中包括Dask。Dask是一个强大的Python库,提供与Pandas兼容的API,通过并行和超出内存的计算来扩展数据处理能力。它通过将工作流分割成更小的批次,并在多个核心或机器上同时执行,来处理大型数据集。
由于Dask是一个非常有价值的工具,学习如何建立一个任何数据专业人士都可以使用的端到端数据管道是非常明智的。因此,本文将教您如何使用Dask来设置数据管道。
让我们开始吧。
准备工作
为了使本教程有效,我们需要进行一些准备工作。首先,我们将建立一个数据库来存储我们的数据。在本例中,我们将使用MySQL作为数据库;因此,只需下载并按照标准安装说明进行操作即可。
对于数据集,我们将使用在Kaggle上公开可用的数据科学家薪资数据集。将数据保存在名为'data'的文件夹中,暂时放置在那里。
接下来,通过使用以下代码创建一个虚拟环境来设置环境。
python -m venv dask_pipeline
您可以为您的虚拟环境选择其他名称,但我更喜欢一个自解释的名称。激活虚拟环境并创建一个requirements.txt文件,该文件将列出项目所需的库。
dask[complete]
pandas
numpy
sqlalchemy
PyMySQL
luigi
python-dotenv
setuptools
文件准备好后,我们将使用以下代码安装库。
pip install -r requirements.txt
然后,创建一个名为'.env'的文件,我们将在其中存储本项目中使用的所有变量,主要用于数据库访问。用以下信息填充文件:
DB_USER=your_username
DB_PASS=your_password
DB_HOST=localhost
DB_PORT=3306
DB_NAME=analytics
接着,创建一个名为config.py的文件,用于连接到数据库。
from dotenv import load_dotenv
import os
load_dotenv()
DB_USER = os.getenv("DB_USER")
DB_PASS = os.getenv("DB_PASS")
DB_HOST = os.getenv("DB_HOST")
DB_PORT = os.getenv("DB_PORT")
DB_NAME = os.getenv("DB_NAME")
CONN_STR = (
f"mysql+pymysql://{DB_USER}:{DB_PASS}@"
f"{DB_HOST}:{DB_PORT}/{DB_NAME}"
)
一切准备就绪后,我们将使用Dask创建我们的端到端数据管道。
使用Dask的数据管道
为了设置数据管道,我们将使用LuigiPython库,该库通常用于构建复杂的批处理作业管道。在我们的案例中,它将用于开发一个利用Dask将CSV数据导入数据库、进行转换并将其加载回数据库的管道。
让我们开始创建管道,首先在名为luigi_pipeline.py的Python文件中编写创建数据库的代码。我们将导入所有必要的库并创建一个任务来建立数据库。
import luigi
from luigi import LocalTarget, Parameter, IntParameter
from sqlalchemy import create_engine, text
import pandas as pd
from dask import delayed
import dask.dataframe as dd
from config import DB_USER, DB_PASS, DB_HOST, DB_PORT, DB_NAME, CONN_STR
class CreateDatabase(luigi.Task):
def output(self):
return LocalTarget("tmp/db_created.txt")
def run(self):
engine = create_engine(
f"mysql+pymysql://{DB_USER}:{DB_PASS}@{DB_HOST}:{DB_PORT}/"
)
with engine.connect() as conn:
conn.execute(text(f"CREATE DATABASE IF NOT EXISTS {DB_NAME}"))
self.output().makedirs()
with self.output().open("w") as f:
f.write("ok")
上面的代码将在运行时创建一个新数据库,如果数据库名称之前不存在。我们将在下面设置的Dask CSV导入管道中使用上述类。
class IngestCSV(luigi.Task):
csv_path = Parameter()
table_name = Parameter(default="ds_salaries")
def requires(self):
return CreateDatabase()
def output(self):
return LocalTarget("tmp/ingest_done.txt")
def run(self):
url_no_db = f"mysql+pymysql://{DB_USER}:{DB_PASS}@{DB_HOST}:{DB_PORT}/"
engine0 = create_engine(url_no_db)
with engine0.connect() as conn:
conn.execute(text(f"CREATE DATABASE IF NOT EXISTS {DB_NAME}"))
ddf = dd.read_csv(self.csv_path, assume_missing=True)
engine = create_engine(CONN_STR)
empty = ddf.head(0)
empty.to_sql(self.table_name, con=engine, if_exists="replace", index=False)
def append_part(pdf):
pdf.to_sql(self.table_name, con=engine, if_exists="append", index=False)
ddf.map_partitions(append_part, meta=()).compute()
with self.output().open("w") as f:
f.write("ok")
在上面的代码中,我们使用Dask读取CSV文件并将其发送到数据库。我们使用Dask来增强读取过程,使数据发送到数据库更加可控。
作为管道的一部分,我们将CSV导入放入ETL转换中,使用下面的代码。
class TransformETL(luigi.Task):
csv_path = Parameter()
table_name = Parameter(default="ds_salaries")
chunk_size = IntParameter(default=100_000)
def requires(self):
return IngestCSV(csv_path=self.csv_path,
table_name=self.table_name)
def output(self):
return LocalTarget("tmp/etl_done.txt")
def run(self):
engine = create_engine(CONN_STR)
# 1. Count total rows for chunking
with engine.connect() as conn:
total = conn.execute(
text(f"SELECT COUNT(*) FROM {self.table_name}")
).scalar()
# 2. Build delayed partitions
@delayed
def load_chunk(offset, limit):
return pd.read_sql(
f"SELECT * FROM {self.table_name} LIMIT {limit} OFFSET {offset}",
engine
)
parts = [
load_chunk(i * self.chunk_size, self.chunk_size)
for i in range((total // self.chunk_size) + 1)
]
# 3. Load zero‐row metadata and cast to correct dtypes
meta = (
pd.read_sql(f"SELECT * FROM {self.table_name} LIMIT 0", engine)
.astype({
"work_year": "int64",
"salary": "float64",
"salary_in_usd": "float64",
"remote_ratio": "int64",
# leave the rest as object
})
)
# 4. Create Dask DataFrame with corrected meta
ddf = dd.from_delayed(parts, meta=meta)
# 5. Filter & clean
ddf = (
ddf
.dropna(subset=["salary_in_usd"])
.assign(
salary_in_usd=ddf["salary_in_usd"].astype(float)
)
)
# 6. Keep only full-time roles
ddf = ddf[ddf["employment_type"] == "FT"]
# 7. Compute salary bracket at 10k USD
bracket = (ddf["salary_in_usd"] // 10_000).astype(int) * 10_000
ddf = ddf.assign(salary_bracket=bracket)
# 8. Aggregate: average salary by year
result = (
ddf.groupby("work_year")["salary_in_usd"]
.mean()
.compute()
.reset_index()
.rename(columns={"salary_in_usd": "avg_salary_usd"})
)
# 9. Persist results
result.to_sql("avg_salary_by_year",
con=engine, if_exists="replace", index=False)
with self.output().open("w") as f:
f.write("ok")
上面的代码使用Dask执行多个任务来转换我们拥有的数据。具体来说,Dask在管道中执行以下操作:
- 分块从数据库加载数据集。
- 设置元数据并创建Dask数据框。
- 使用Dask进行过滤和数据清理。
- 使用Dask进行数据转换
- 将数据加载到数据库中
数据管道已经准备好使用,我们可以通过下面的Python代码来执行它。
python luigi_pipeline.py TransformETL --csv-path data\ds_salaries.csv
您将会收到如下的输出信息。
===== Luigi Execution Summary =====
Scheduled 1 tasks of which:
* 1 complete ones were encountered:
- 1 TransformETL(csv_path=data\ds_salaries.csv, table_name=ds_salaries, chunk_size=100000)
Did not run any tasks
This progress looks :) because there were no failed tasks or missing dependencies
接下来,您可以查看Luigi UI以确认管道是否正常工作。
luigid
您可以在下面的图片中看到仪表板的输出。
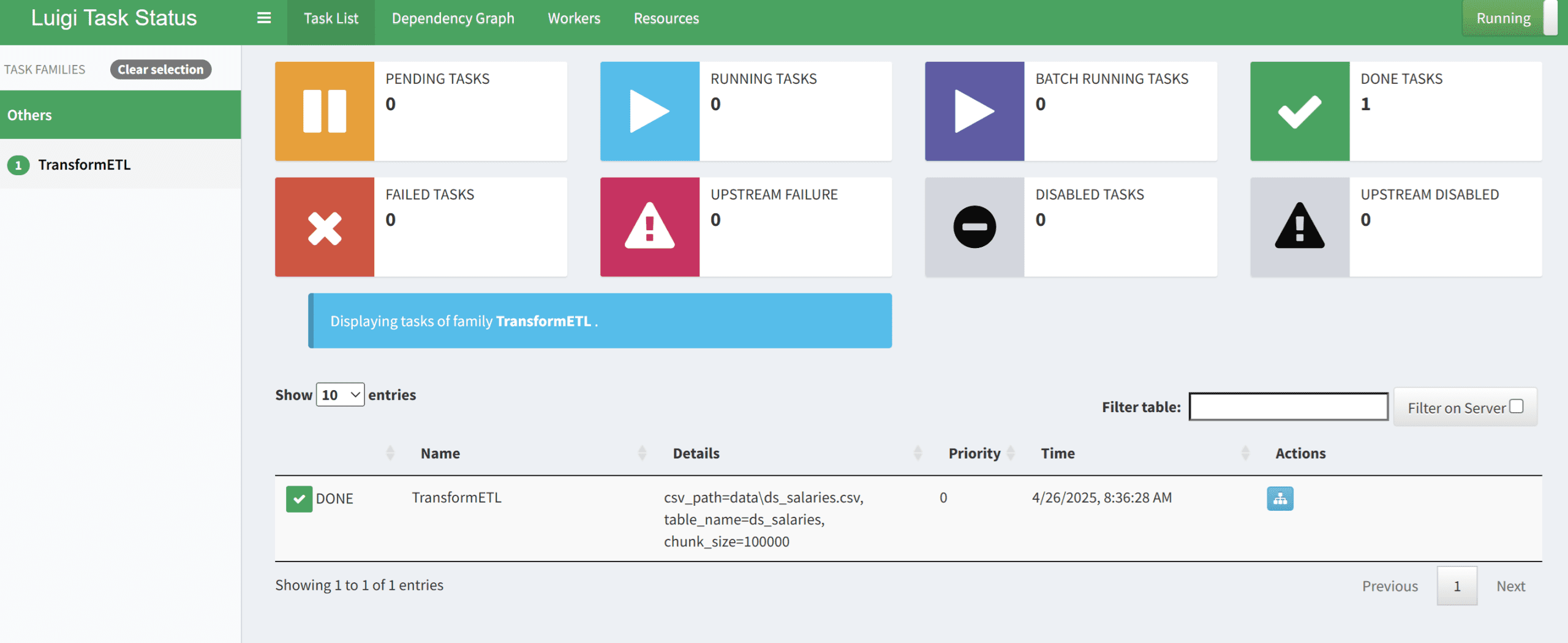
如果成功,您将看到管道已成功执行,并可以在您的数据库中查看结果。
SELECT * FROM analytics.avg_salary_by_year;
输出结果如下所示。
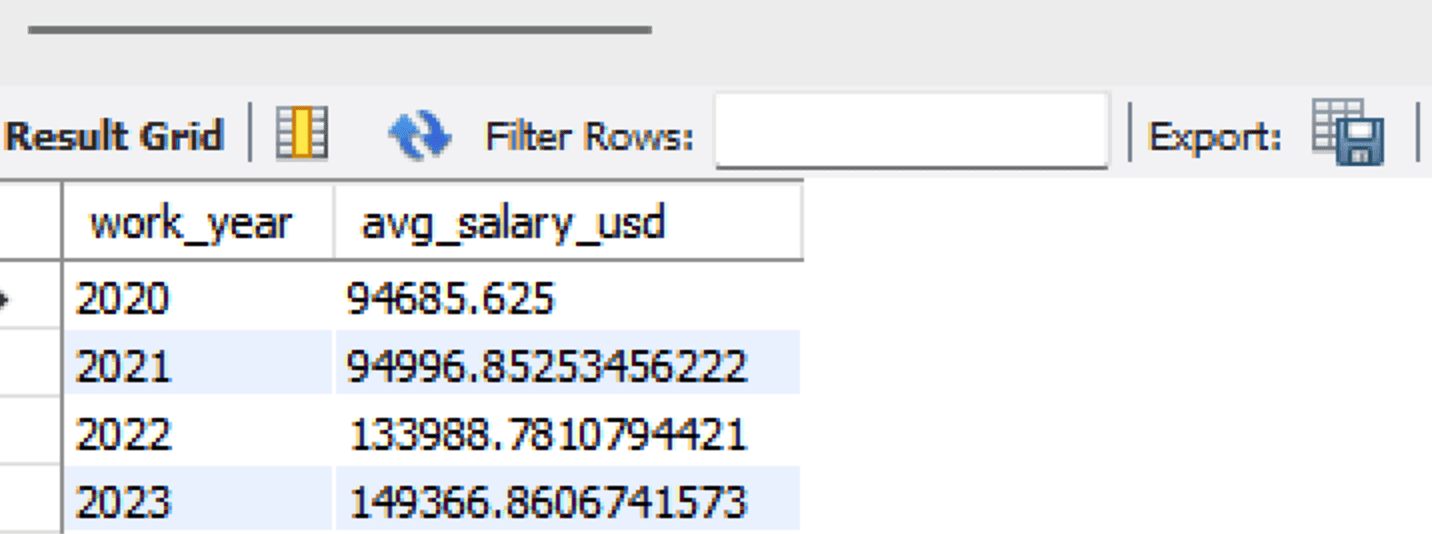
通过这种方式,您已经使用Dask构建了一个端到端的数据管道。所有代码都存储在以下的GitHub仓库中。
结论
构建数据管道是数据专业人员的一项重要技能,特别是在使用Dask时,因为它能够增强数据处理和操作。在本文中,我们学习了如何构建从数据摄取到将其加载回数据库的端到端数据管道。









