











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微调YOLOv8实现精准图像分割:提高目标检测性能
2023年07月28日 由 Alex 发表
915590
0
介绍
如今人工智能开发人员使用计算机视觉(CV)整合解决方案来实时识别、分类和响应对象。一些常见的任务包括图像分类、面部检测、姿态估计、分割等。像YOLOv8这样的模型在各种目标检测和语义分割基准上取得了最先进的结果,CV获得了显著的准确性和效率。
什么是图像分割?
图像分割是在像素级别将数字图像分割成多个片段或区域的过程。它使CV模型能够在详细理解图像的内容,并基于分割的区域执行相关操作。
图像分割广泛应用于医学成像领域,如肿瘤检测、疾病诊断、器官分割等。此外,它还用于机器人的物体识别和操作,以及自动驾驶汽车辆中的物体检测和分类。
计算机视觉中常用的图像分割技术包括实例分割、全景分割、基于区域的分割和阈值分割。
为什么要对模型进行微调?
对模型进行微调包括采用预先训练好的模型,并对其进行调整,使其在新的特定任务或数据集上表现良好。这个过程有助于提高模型在以前未见过的数据上的性能。例如,在水平拍摄的智能手机图像上训练的图像分割模型在垂直卫星图像上可能表现不佳。
通过对模型进行微调,我们可以利用模型在一般对象分割上的预训练来开发更精确的模型。这有助于在不经过整个训练过程的情况下提供优化的模型,从而节省时间和计算资源。
此外,由于我们的自定义数据集可能不包含数百万个示例,因此与从头开始训练模型相比,微调成为一种有利的方法。
对模型进行微调可以提供以下好处:
1. 增强模型的性能。
2. 节省计算资源,减少训练时间。
3. 允许模型利用预先训练的知识来完成目标任务。
4. 使模型能够适应以前未见过的或新的数据分布。
5. 为特定用例定制模型,优化其性能。
图像分割模型的局限性
虽然近年来图像分割模型取得了重大进展,但仍然存在一些局限性。其中包括以下内容:
1. 处理非结构化和不均匀分布的3D数据:随着激光雷达相机等图像采集设备的兴起,对3D数据分割技术的需求越来越大,如点云、体素等。然而,这些非结构化、无序、冗余和不均匀分布的三维数据的表示和处理仍然是分割算法面临的一个重大挑战。
2. 标记数据集的可用性有限:在某些领域,缺乏带有细粒度注释的数据集,这使得使用监督学习算法训练分割网络变得困难。
3. 计算复杂度和实时性:深度学习网络用于图像分割,由于其在训练过程中的计算复杂度,需要大量的计算资源。实现实时分割,在许多领域都是必要的,比如视频处理,其目标是至少每秒25帧,仍然具有挑战性。
4. 处理噪声和图像质量变化的能力有限:许多图像分割算法对噪声和图像质量变化很敏感,这使得在质量差或分辨率低的图像上难以获得准确的结果。
什么是YOLOv8?
YOLOv8是“You Only Look Once version 8”的缩写,是一种最先进的模型,可用于图像分类、对象检测和实例分割任务。它是YOLO系列模型的演变,以其实时目标检测能力而闻名。
YOLOv8引入了重要的架构改进和开发人员经验,使其区别于其前身YOLOv5。YOLOv8的主要改进包括:
1. 一种与基于锚的方法不同的无锚检测系统。
2. 对模型中使用的卷积块的修改提高了其整体性能。
3. 在训练期间实现马赛克增强,在最后10个epoch中禁用。
YOLOv8可以从命令行界面(CLI)执行,也可以作为PIP包安装,以方便使用。此外,它还为标记、培训和部署提供了多个集成,进一步简化了工作流程。
当在MS COCO数据集test-dev 2017上进行评估时,YOLOv8x在图像尺寸为640像素时获得了令人印象深刻的53.9%的平均精度(AP),超过了YOLOv5在相同输入尺寸下实现的50.7%。此外,YOLOv8x在NVIDIA A100和TensorRT上表现出280 FPS的速度,突出了其效率和计算性能。
使用 Comet 微调 YOLOv8 模型
尽管表现令人印象深刻,但像YOLOv8这样的预训练模型仍难以应对特定案例和利基任务。要根据需要更改这些模型,重要的是要根据自定义数据集对它们进行微调。让我们看看如何为实例分割对YOLOv8进行微调。
我们将使用开放图像数据集进行微调,并使用Comet平台集成进行实验跟踪、日志记录和模型存储。
数据探索
我们将对模型进行微调以分割图像中的“鸭子”,并从开放的图像数据集中获得相关的数据集和注释。我们的训练集由400张图像组成,而验证集有50张图像。
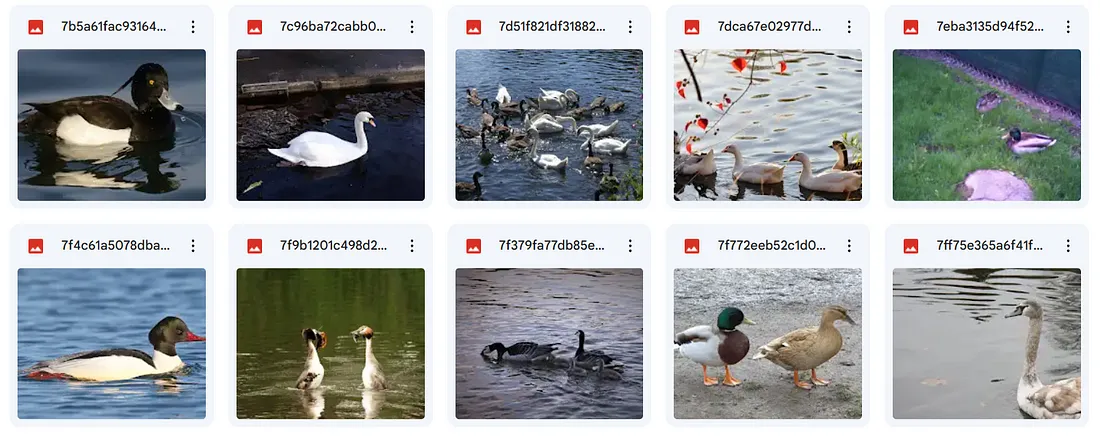
图像分割任务的注释文件由类标签和用于形成分割掩码的像素坐标组成。

预训练实验
在继续进行自定义数据集训练之前,让我们看看预训练的模型为自定义数据集输出了什么。
首先,我们安装所需的库。
!pip install ultralytics comet_ml torch torchvision kaggle --quiet
ultralytics包将允许我们访问YOLOv8模型,comet_ml将允许我们在彗星平台内启动实验,而在YOLOv8中需要导入torch和torchvision。
接下来,我们导入必要的包。
import comet_ml
from ultralytics import YOLO
import os
from google.colab import files
首先,我们从Kaggle导入数据集。为此,我们需要Kaggle API令牌和相关的数据集URI。要访问数据集,你必须创建自己的Kaggle令牌并将其上传到Colab工作区。完成后,你可以通过运行以下命令访问数据集。
!kaggle datasets download haziqasajid5122/yolov8-finetuning-dataset-ducks
!unzip yolov8-finetuning-dataset-ducks -d /content/Data
!cp /content/Data/config.yaml /content/config.yaml
要使用comet_ml运行实验,我们需要一个API密钥。从免费的Comet帐户获取API密钥。你可以在Account Settings下找到API密钥。
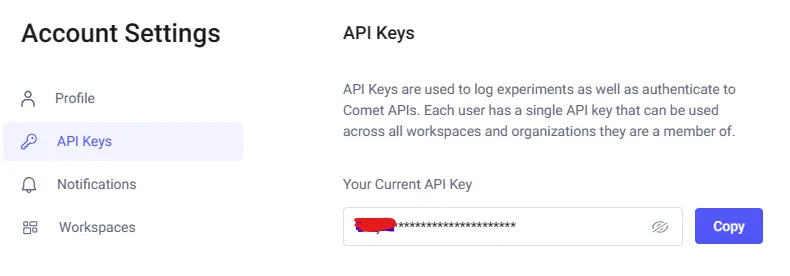
使用此键的最简单方法是将其设置为环境变量。
os.environ[“COMET_API_KEY”] = “”
现在,当我们初始化Comet项目时,它将自动检测此键并继续进行设置。
comet_ml.init(“YOLOv8-With-Comet”)
接下来,我们需要选择一个预训练的YOLO模型。默认情况下,ultralytics为每个不同大小的任务包含多个模型。分割模块包括:
1. YOLOv8n-seg
2. YOLOv8s-seg
3. YOLOv8m-seg
4. YOLOv8l-seg
5. YOLOv8x-seg
我们将使用YOLOv8m-seg (medium)模型,因为它可以为我们提供训练性能和结果之间的平衡。
model = YOLO(‘yolov8m-seg.pt’)
当模型第一次被调用时,它将被自动下载到你的本地设备。
现在让我们看看这个模型如何在我们的自定义数据集上工作。
results = model.predict("/content/Data/images/val/0a411d151f978818.png", save=True)"/content/Data/images/val/0a411d151f978818.png", save=True)我们的实验是在安装了Google Drive的Google Colab环境中运行的,这就是路径看起来这样的原因。

图像被正确分割为“鸟”,这是预期的,因为预训练模型是在COCO数据集上训练的。然而,我们希望告诉模型这是什么类型的鸟,即在本例中是一只鸭子。
微调
对于自定义数据集训练,YOLO希望数据具有一定的格式。训练和验证图像和标签的目录结构如下所示。
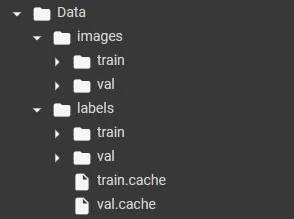
“images”的子文件夹包含所有的“.png”文件,标签目录包含“.txt”格式的注释。
YOLO也期待一个'.yaml '文件,其中包含数据集路径的详细信息和数据集中的类标签。以下是'.yaml '的信息。
path: /content/Data
train: images/train
val: images/val
nc: 1
names:
0: duck
数据集的路径配置将根据你的系统。
所有细节准备就绪,现在开始培训。
results = model.train(
data="/content/config.yaml","/content/config.yaml",
project="YOLOv8-With-Comet",
batch=12,
save_json=True,
epochs=15,
pretrained=True
)
一旦提交训练,Comet将自动在你的Comet工作空间中创建一个实验来跟踪运行。
在转到实验日志之前,让我们看看我们的微调模型是否按预期执行。
results = model.predict("/content/Data/images/val/0a411d151f978818.png", save=True)"/content/Data/images/val/0a411d151f978818.png", save=True)
这个模型似乎准确地认出了鸭子。尽管建议使用超参数优化和更大的数据集进行进一步训练,但这个微调模型现在已经为特定任务的实现做好了准备。
使用Comet日志
Comet将根据需要跟踪尽可能多的实验,并显示所有运行的指标。
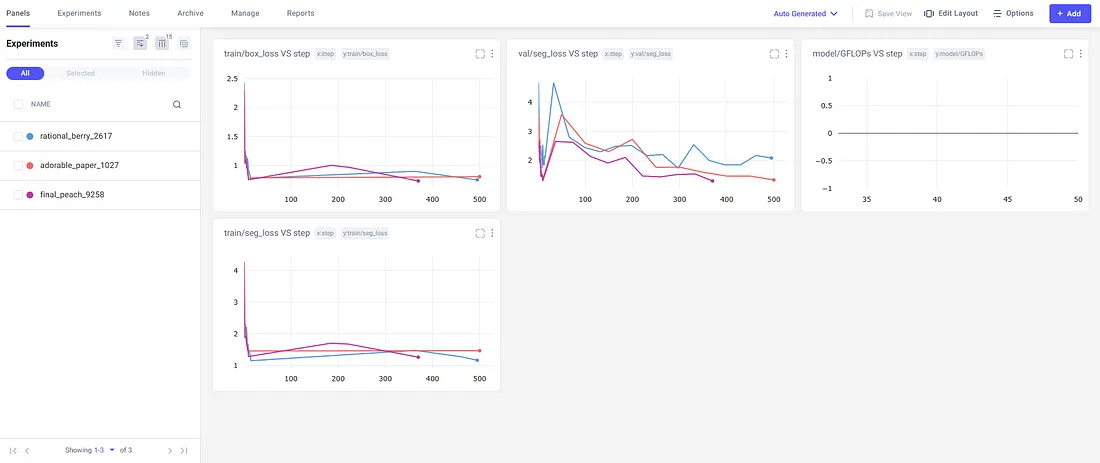
左边的面板显示了所有的实验(如果没有指定名称,Comet将随机分配一个),并为每个实验绘制了不同的指标。让我们来看看我们最新的运行。
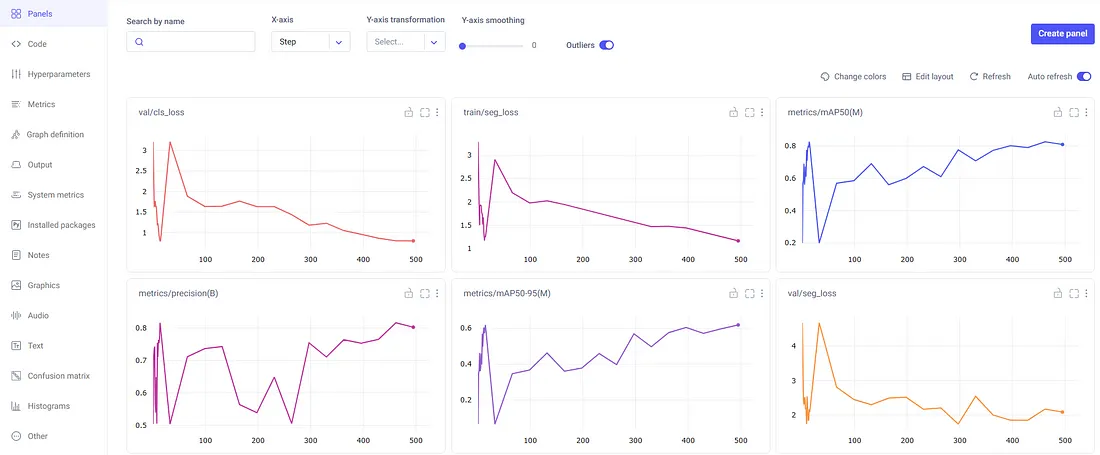
直接地,我们看到Comet已经可视化了每个时期的一些常见指标。这里的一些常见指标包括:
1. 段掩码丢失(seg_loss)
2. 类别丢失(cls_loss)
3. 精确
4. 平均精度(mAP50-95)
从这张鸟瞰图中,我们可以看到损失一直在减少,mAP一直在增加。这意味着增加纪元数量可能会产生更好的模型。
我们还可以在单独的窗格中查看指标。
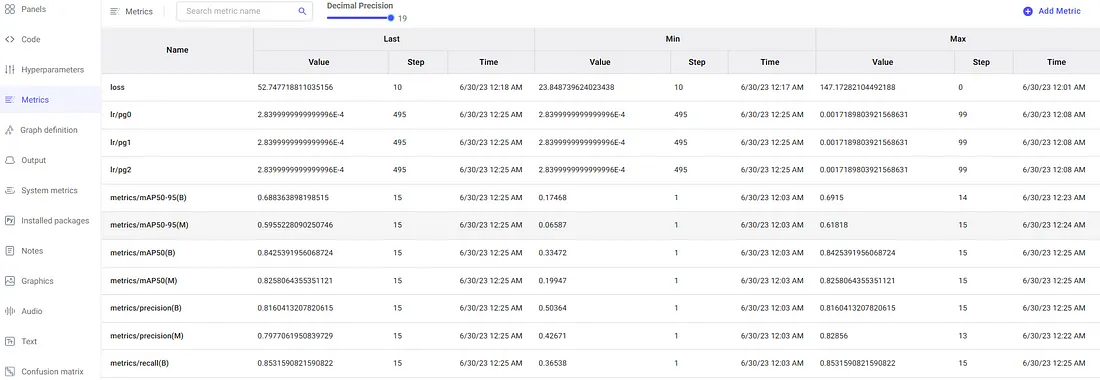
这将以表格格式显示详细信息,以提高精度。
Comet以图形格式记录所有步骤,并将它们存储在相应的实验下,供用户稍后查看。最后,为了评估模型性能,Comet创建了一个混淆矩阵。
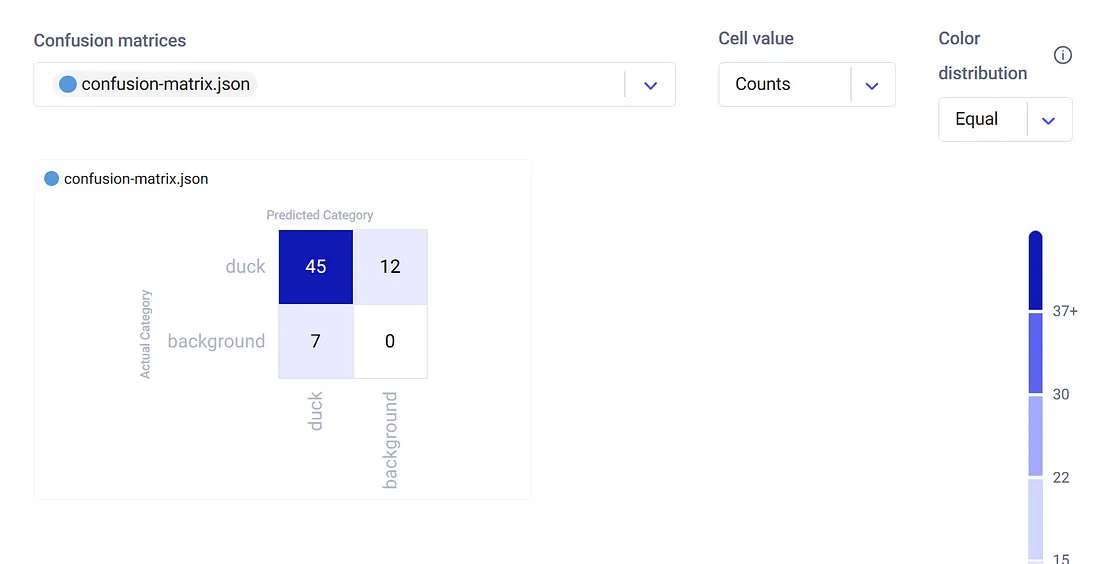
从这张图中,我们可以看到我们的微调模型正确地从验证数据集中检测并分割了45只鸭子。比正面标签类别有79%的成功率。
此外,Comet还保留了实验期间使用的系统的日志。
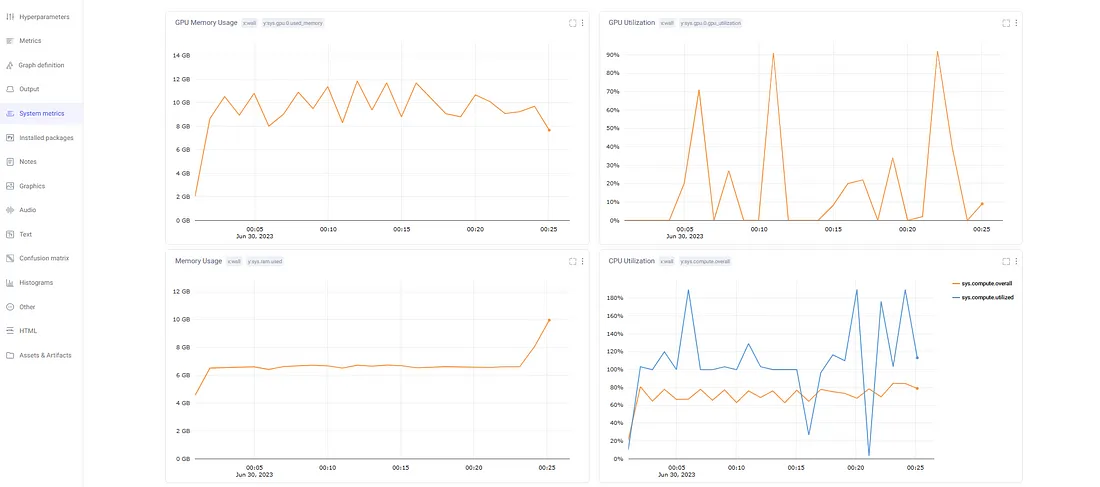
它显示如下信息:
1. GPU的利用率
2. GPU内存利用率
3. CPU利用率
4. 内存利用率
这些指标有助于监视系统运行状况,并调试由于资源错误而导致的实验失败。
总的来说,Comet提供了一个很好的平台来跟踪和版本控制机器学习任务。它提供了整个运行的交互式鸟瞰图,以了解模型性能并采取改进措施。
它还存储所有实验细节(运行配置、超参数)、生成的图形和训练过的模型,这些可以与同事共享,以便更好地进行团队协作。
结论
模型微调是机器学习生态系统的重要组成部分。它允许机器学习工程师跳过从头开始训练整个模型的麻烦,并构建高性能的特定任务应用程序。微调是通过从现有模型加载预训练的权重并进一步训练它们以学习特定于我们需要的模式来执行的。
然而,实验过程仍然很复杂,可以通过第三方集成来简化。Comet平台自动跟踪你的所有机器学习运行。它为模型评估记录所有必要的度量,并存储实验细节和训练模型,以供协作和将来参考。
来源:https://heartbeat.comet.ml/fine-tuning-yolov8-for-image-segmentation-9ac7c6e1ddb5

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消