











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌推出SoundStorm:离散条件标记实现并行音频生成
2023年07月19日 由 daydream 发表
854501
0
谷歌最近在一篇论文中推出了名为“SoundStorm:高效并行音频生成”的新模型。该模型提供了一种高效且高质量的音频生成新方法。

SoundStorm通过两个创新组件来解决生成较长音频标记序列的问题:
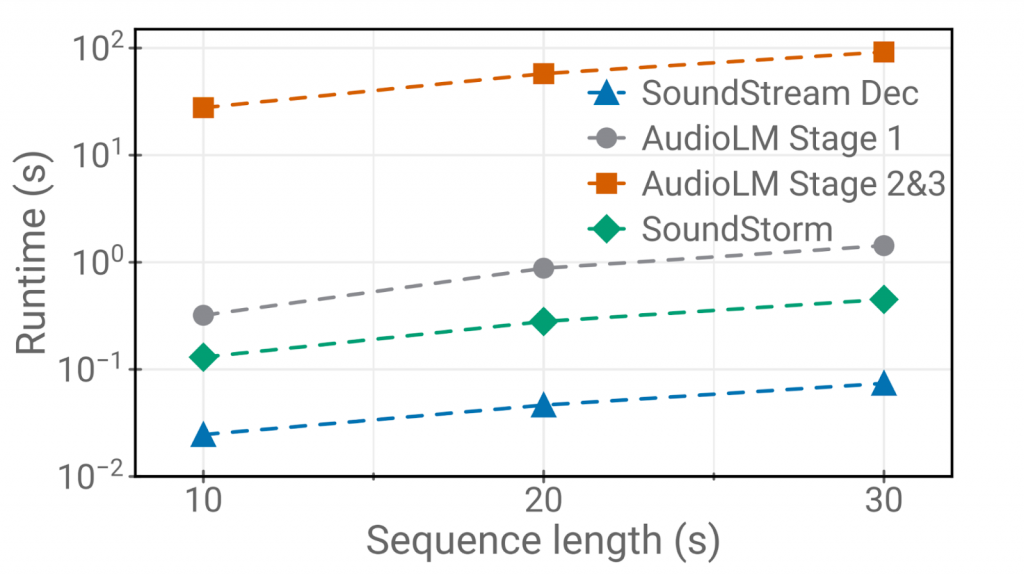
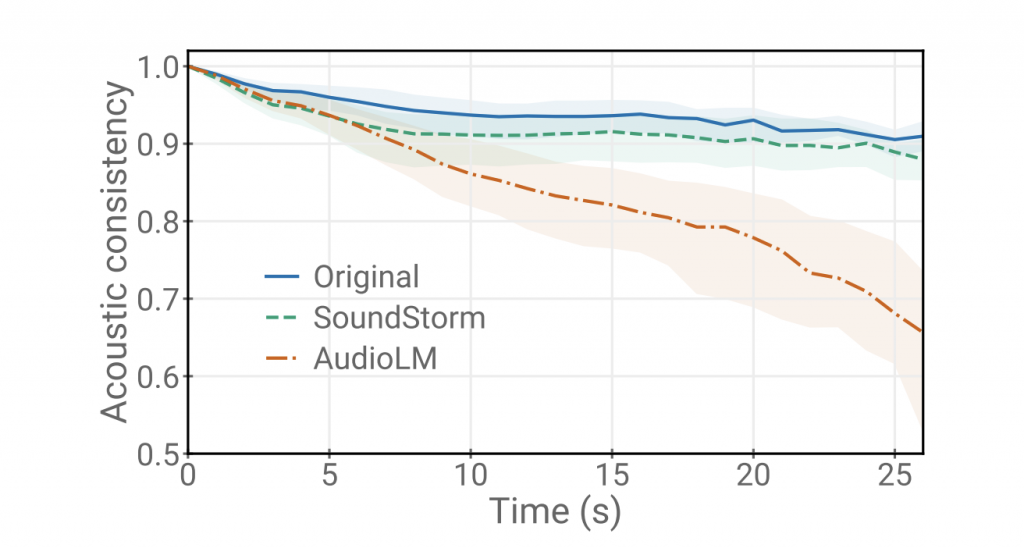
与AudioLM的自回归解码方法相比,SoundStorm实现了标记的并行生成,从而将长序列的推断时间缩短了100倍。此外,SoundStorm在保持音频质量的同时,在语音和声学条件上提供了更高的一致性。
此外,该论文还展示了通过将SoundStorm与SPEAR-TTS的文本到语义建模阶段相结合,可以合成高质量、自然的对话。这使得可以通过转录文本来控制口头内容,使用短语音提示来选择说话者的声音,通过转录注释来控制对话者的交替。所提供的示例证明了SoundStorm及其与SPEAR-TTS的整合在产生具有说服力的对话方面的能力。
在他们之前关于AudioLM的研究中,研究人员展示了一种生成音频的两步过程。第一步是语义建模,根据先前的语义标记或条件信号生成语义标记。第二步是声学建模,重点是从语义标记中生成声学标记。
然而,在SoundStorm中,研究人员特别处理了声学建模步骤,并旨在将较慢的自回归解码方法替换为更快的并行解码方法。
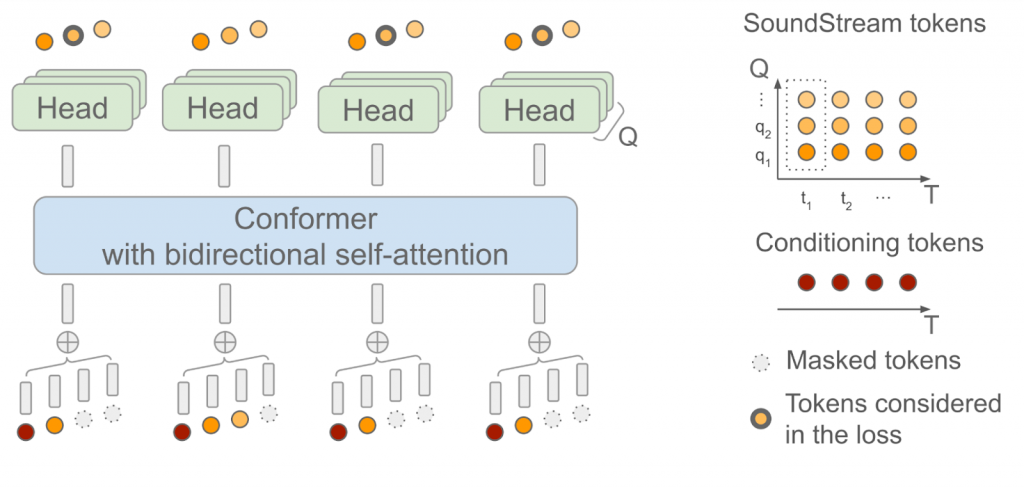
SoundStorm使用了双向注意力机制的Conformer模型架构,该架构将卷积和Transformer相结合。该架构可以捕捉序列标记中的局部和全局结构。该模型通过训练来预测由AudioLM生成的语义标记序列输入的SoundStream生成的音频标记。SoundStream模型采用了一种称为残差向量量化(RVQ)的方法,在每个时间步长上使用最多Q个标记来表示音频。随着每个时间步生成的标记数量从1增加到Q,重建的音频质量逐渐提升。
在推理过程中,SoundStorm首先将所有音频标记进行屏蔽,然后在多次迭代中填充屏蔽的标记。它从RVQ级别q = 1的粗略标记开始,并逐级细化,直到达到级别q = Q。这种方法实现了快速生成音频的能力。
SoundStorm具有快速生成音频的两个关键方面。首先,在每个RVQ级别的单次迭代中并行预测标记。其次,模型架构的设计使得计算复杂度对级别数量Q的影响较小。为支持这种推理方案,在训练过程中使用了精心设计的屏蔽方案,以模拟推理过程中使用的迭代过程。
与AudioLM相比,SoundStorm生成速度显著提高,快了两个数量级,并且在生成较长音频样本时能够实现更好的一致性。通过将SoundStorm与类似于SPEAR-TTS的文本到语义标记模型相结合,文本到语音合成可以扩展以处理更长的上下文。
此外,SoundStorm还可以生成具有多个发言者轮次的自然对话,使用户能够控制发言者的声音和生成的内容。值得注意的是,SoundStorm不仅限于语音合成。例如,MusicLM有效地使用SoundStorm来合成更长的音乐输出。
这项工作解决的挑战是使用自回归解码方法生成长序列音频标记时推理时间较慢的问题。自回归解码虽然能确保高音质,但是它逐个生成标记,导致推理计算开销较大,特别是对于较长的序列来说。SoundStorm提出了一种新方法,通过引入适用于音频标记的架构和受MaskGIT启发的解码方案,实现了标记的并行生成。通过这种方式,SoundStorm显著减少了推理时间,使音频生成更加高效,同时不会牺牲生成音频的质量和一致性。
许多生成式音频模型,包括AudioLM,使用自回归解码,逐个生成标记。虽然这种方法确保高音质,但在处理较长的序列时可能计算较慢。
来源:https://analyticsindiamag.com/google-unveils-soundstorm-for-parallel-audio-generation-from-discrete-conditioning-tokens/
SoundStorm通过两个创新组件来解决生成较长音频标记序列的问题:
- 针对SoundStream神经编解码器生成的音频标记的独特特性进行了定制化的架构设计。
- 采用了一种受到MaskGIT启发的解码方案,MaskGIT是一种最近引入的图像生成方法,专为音频标记操作而设计。
与AudioLM的自回归解码方法相比,SoundStorm实现了标记的并行生成,从而将长序列的推断时间缩短了100倍。此外,SoundStorm在保持音频质量的同时,在语音和声学条件上提供了更高的一致性。
此外,该论文还展示了通过将SoundStorm与SPEAR-TTS的文本到语义建模阶段相结合,可以合成高质量、自然的对话。这使得可以通过转录文本来控制口头内容,使用短语音提示来选择说话者的声音,通过转录注释来控制对话者的交替。所提供的示例证明了SoundStorm及其与SPEAR-TTS的整合在产生具有说服力的对话方面的能力。
底层技术
在他们之前关于AudioLM的研究中,研究人员展示了一种生成音频的两步过程。第一步是语义建模,根据先前的语义标记或条件信号生成语义标记。第二步是声学建模,重点是从语义标记中生成声学标记。
然而,在SoundStorm中,研究人员特别处理了声学建模步骤,并旨在将较慢的自回归解码方法替换为更快的并行解码方法。
SoundStorm使用了双向注意力机制的Conformer模型架构,该架构将卷积和Transformer相结合。该架构可以捕捉序列标记中的局部和全局结构。该模型通过训练来预测由AudioLM生成的语义标记序列输入的SoundStream生成的音频标记。SoundStream模型采用了一种称为残差向量量化(RVQ)的方法,在每个时间步长上使用最多Q个标记来表示音频。随着每个时间步生成的标记数量从1增加到Q,重建的音频质量逐渐提升。
在推理过程中,SoundStorm首先将所有音频标记进行屏蔽,然后在多次迭代中填充屏蔽的标记。它从RVQ级别q = 1的粗略标记开始,并逐级细化,直到达到级别q = Q。这种方法实现了快速生成音频的能力。
SoundStorm具有快速生成音频的两个关键方面。首先,在每个RVQ级别的单次迭代中并行预测标记。其次,模型架构的设计使得计算复杂度对级别数量Q的影响较小。为支持这种推理方案,在训练过程中使用了精心设计的屏蔽方案,以模拟推理过程中使用的迭代过程。
与AudioLM相比,SoundStorm生成速度显著提高,快了两个数量级,并且在生成较长音频样本时能够实现更好的一致性。通过将SoundStorm与类似于SPEAR-TTS的文本到语义标记模型相结合,文本到语音合成可以扩展以处理更长的上下文。
此外,SoundStorm还可以生成具有多个发言者轮次的自然对话,使用户能够控制发言者的声音和生成的内容。值得注意的是,SoundStorm不仅限于语音合成。例如,MusicLM有效地使用SoundStorm来合成更长的音乐输出。
为什么这一点很重要?
这项工作解决的挑战是使用自回归解码方法生成长序列音频标记时推理时间较慢的问题。自回归解码虽然能确保高音质,但是它逐个生成标记,导致推理计算开销较大,特别是对于较长的序列来说。SoundStorm提出了一种新方法,通过引入适用于音频标记的架构和受MaskGIT启发的解码方案,实现了标记的并行生成。通过这种方式,SoundStorm显著减少了推理时间,使音频生成更加高效,同时不会牺牲生成音频的质量和一致性。
许多生成式音频模型,包括AudioLM,使用自回归解码,逐个生成标记。虽然这种方法确保高音质,但在处理较长的序列时可能计算较慢。
来源:https://analyticsindiamag.com/google-unveils-soundstorm-for-parallel-audio-generation-from-discrete-conditioning-tokens/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消