











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用分布式数据集上的联合学习使LLM适应下游任务
2023年07月11日 由 Alex 发表
464236
0
大型语言模型(LLM),如GPT,已经成为自然语言处理(NLP)中的革命性工具,因为它们能够理解和生成类似人类的文本。这些模型在大量不同的数据上进行训练,使它们能够学习模式、语言结构和上下文关系。它们作为基础模型,可以定制为广泛的下游任务,使它们具有高度的通用性。
下游任务,如分类,可以包括基于预定义标准的文本分析和分类,帮助完成情感分析或垃圾邮件检测等任务。在封闭式问答(QA)中,他们可以根据给定的上下文提供精确的答案。在生成任务中,它们可以生成类似人类的文本,比如写故事或写诗。即使是头脑风暴,LLM也可以利用他们庞大的知识基础产生创造性和连贯的想法。
LLM的适应性和多功能性使其成为广泛应用的宝贵工具,使企业,研究人员和个人能够以卓越的效率和准确性完成各种任务。
使用特定于任务的模块对LLM进行参数有效的微调已经得到了重视。这种方法包括保持预训练的LLM层固定,同时根据手头的特定任务调整较小的附加参数集。已经开发了各种技术来促进这个过程,包括提示调优、p调优、适配器、LoRA等。
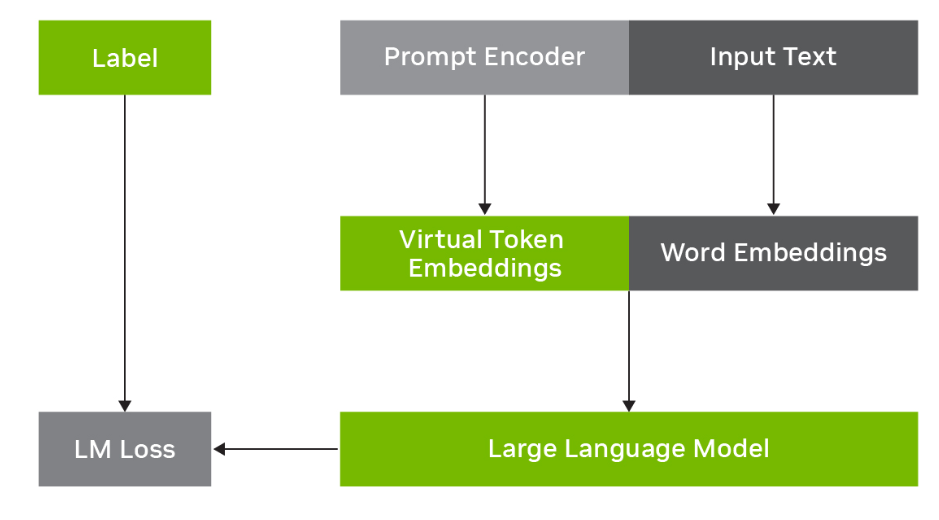
例如,p调优涉及冻结LLM并学习预测与原始输入文本结合的虚拟令牌嵌入,如下图所示。特定于任务的虚拟令牌嵌入由提示编码器网络预测,该网络与输入词嵌入一起被馈送到LLM中,以提高推理时下游任务的性能。它是参数高效的,因为只需在输入文本和标签上训练提示编码器参数,而基本的LLM参数可以保持固定。
由于监管限制和复杂的官僚程序,使用私人数据来训练人工智能模型带来了重大挑战。隐私法规和数据保护法通常禁止共享敏感信息,限制了传统数据共享方法的可行性。此外,数据注释是模型训练的一个关键方面,它需要大量的成本和大量的时间和精力。
认识到数据是一种有价值的资产,联邦学习(FL)已经成为解决这些问题的一种技术。FL通过共享模型而不是原始数据来绕过传统的模型训练过程。参与的客户端在本地使用各自的私有数据集训练模型,并汇总更新的模型参数。这既保护了底层数据的隐私,又从培训过程中获得的知识中获益。
不需要直接的数据交换,这降低了与数据隐私法规相关的遵从性风险,并将繁重的数据注释成本分配给联合中的协作者。
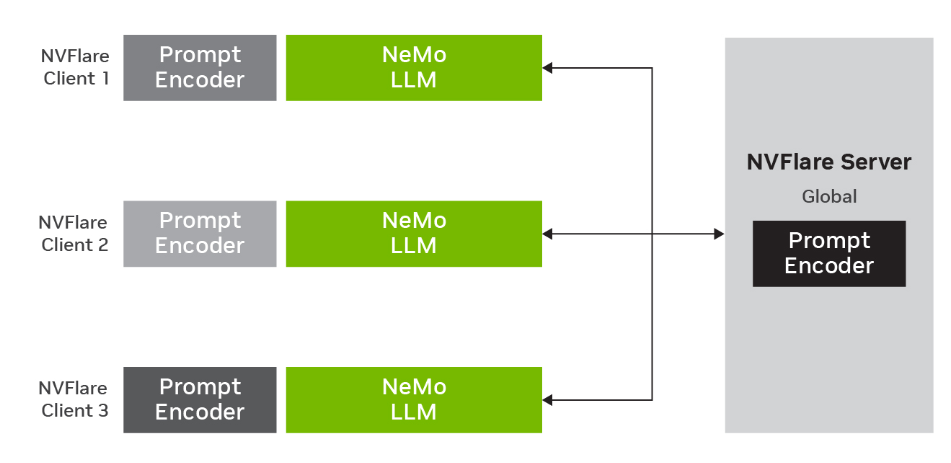
下图显示了使用全局模型和三个客户机的联合p调优。LLM参数保持固定,而提示编码器参数在本地数据上进行训练。局部训练后,新的参数在服务器上聚合,更新全局模型,以进行下一轮联邦学习。
FL通过利用分散的数据源使LLM适应下游任务。通过在不共享原始数据的情况下跨多个参与者协作训练LLM可以通过利用集体知识和将模型暴露于更广泛的语言模式来增强LLM的准确性、稳健性和普遍性。此外,FL提供了各种模型适应和推理选项,包括在聚合数据上训练的全局模型和为个人客户量身定制的个性化模型。
本节提供了一个使用p调优从NVIDIA NeMo框架为下游任务联合适应LLM的示例。NeMo和NVIDIA Flare都是由NVIDIA开发的开源工具包。这种微调过程是高效的,因为只需要交换几百万个参数,从而大大减少了通信负担。
在该情感分析任务中,具有200亿个参数的NeMo Megatron-GPT模型可以使用p-tuning进行有效微调。它使用Financial PhraseBank数据集,其中。包含从散户投资者的角度对金融新闻头条的看法。
示例输入和模型预测下图所示。总的来说,这些数据包含1800对标题和相应的情绪标签。在p调优中,一个可训练的提示编码器网络只更新了5000万个参数(占全部20B参数的0.25%)。对于FL实验,数据被分成三组,对应于每个网站的600个标题和情感对。客户机使用相同的验证集来支持直接比较。

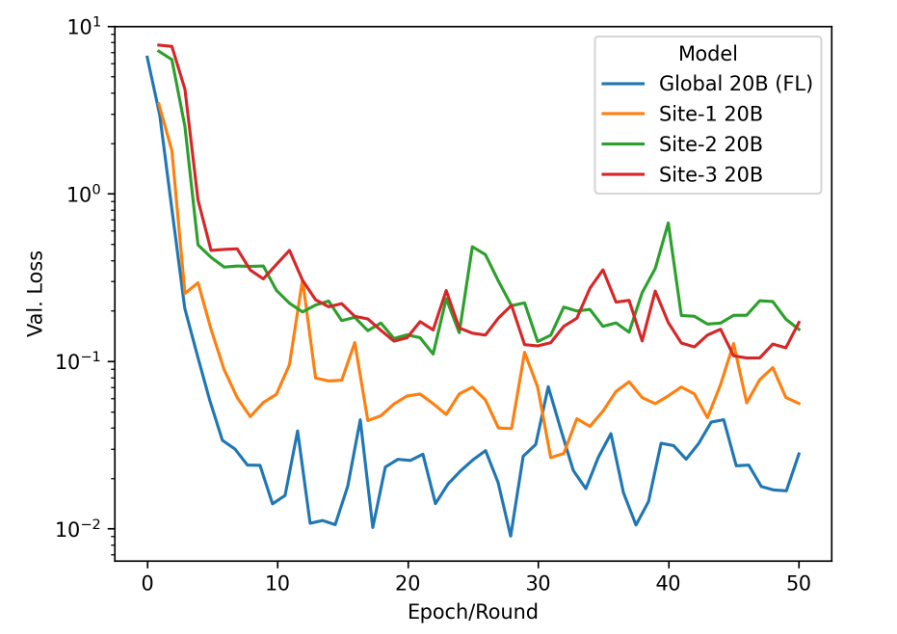
下图比较了以集中式方式训练模型与以联邦方式训练模型50次(或FL轮)的情况。在这两种设置中,调整后的模型在下游任务上的表现相当,在验证集上实现了类似的低损失。下图只比较了在本地数据集上训练的每个客户端与使用FL进行p调优的模型。通过有效地利用协作中可用的更大的训练集,可以看到使用联合p调优的全局模型的明显优势,并且比单独使用数据进行训练的客户端实现更低的损失。
总的来说,这篇文章强调了联邦p调优在使LLM适应下游任务方面的潜力,强调了FL在实现协作学习以保护隐私和提高模型性能方面的好处。一些关键的结论是:
1. 像GPT这样的大型语言模型已经彻底改变了NLP,为分类、问答、生成和头脑风暴等各种下游任务提供了多功能性。
2. 联邦学习通过共享模型参数而不是原始数据来解决与私有数据相关的挑战,从而确保隐私并降低遵从性风险。
3. 带有特定于任务的模块的微调LLM,如prompt-tuning或p-tuning,可以有效地适应特定的任务。
4. FL促进了协作训练和推理,从而提高了模型的性能。
来源:https://developer.nvidia.com/blog/adapting-llms-to-downstream-tasks-using-federated-learning-on-distributed-datasets/
下游任务,如分类,可以包括基于预定义标准的文本分析和分类,帮助完成情感分析或垃圾邮件检测等任务。在封闭式问答(QA)中,他们可以根据给定的上下文提供精确的答案。在生成任务中,它们可以生成类似人类的文本,比如写故事或写诗。即使是头脑风暴,LLM也可以利用他们庞大的知识基础产生创造性和连贯的想法。
LLM的适应性和多功能性使其成为广泛应用的宝贵工具,使企业,研究人员和个人能够以卓越的效率和准确性完成各种任务。
LLM对下游任务的适应
使用特定于任务的模块对LLM进行参数有效的微调已经得到了重视。这种方法包括保持预训练的LLM层固定,同时根据手头的特定任务调整较小的附加参数集。已经开发了各种技术来促进这个过程,包括提示调优、p调优、适配器、LoRA等。
例如,p调优涉及冻结LLM并学习预测与原始输入文本结合的虚拟令牌嵌入,如下图所示。特定于任务的虚拟令牌嵌入由提示编码器网络预测,该网络与输入词嵌入一起被馈送到LLM中,以提高推理时下游任务的性能。它是参数高效的,因为只需在输入文本和标签上训练提示编码器参数,而基本的LLM参数可以保持固定。
联邦学习
由于监管限制和复杂的官僚程序,使用私人数据来训练人工智能模型带来了重大挑战。隐私法规和数据保护法通常禁止共享敏感信息,限制了传统数据共享方法的可行性。此外,数据注释是模型训练的一个关键方面,它需要大量的成本和大量的时间和精力。
认识到数据是一种有价值的资产,联邦学习(FL)已经成为解决这些问题的一种技术。FL通过共享模型而不是原始数据来绕过传统的模型训练过程。参与的客户端在本地使用各自的私有数据集训练模型,并汇总更新的模型参数。这既保护了底层数据的隐私,又从培训过程中获得的知识中获益。
不需要直接的数据交换,这降低了与数据隐私法规相关的遵从性风险,并将繁重的数据注释成本分配给联合中的协作者。
下图显示了使用全局模型和三个客户机的联合p调优。LLM参数保持固定,而提示编码器参数在本地数据上进行训练。局部训练后,新的参数在服务器上聚合,更新全局模型,以进行下一轮联邦学习。
联合LLM对下游任务的适应
FL通过利用分散的数据源使LLM适应下游任务。通过在不共享原始数据的情况下跨多个参与者协作训练LLM可以通过利用集体知识和将模型暴露于更广泛的语言模式来增强LLM的准确性、稳健性和普遍性。此外,FL提供了各种模型适应和推理选项,包括在聚合数据上训练的全局模型和为个人客户量身定制的个性化模型。
用于情感分析的联合调优
本节提供了一个使用p调优从NVIDIA NeMo框架为下游任务联合适应LLM的示例。NeMo和NVIDIA Flare都是由NVIDIA开发的开源工具包。这种微调过程是高效的,因为只需要交换几百万个参数,从而大大减少了通信负担。
在该情感分析任务中,具有200亿个参数的NeMo Megatron-GPT模型可以使用p-tuning进行有效微调。它使用Financial PhraseBank数据集,其中。包含从散户投资者的角度对金融新闻头条的看法。
示例输入和模型预测下图所示。总的来说,这些数据包含1800对标题和相应的情绪标签。在p调优中,一个可训练的提示编码器网络只更新了5000万个参数(占全部20B参数的0.25%)。对于FL实验,数据被分成三组,对应于每个网站的600个标题和情感对。客户机使用相同的验证集来支持直接比较。
下图比较了以集中式方式训练模型与以联邦方式训练模型50次(或FL轮)的情况。在这两种设置中,调整后的模型在下游任务上的表现相当,在验证集上实现了类似的低损失。下图只比较了在本地数据集上训练的每个客户端与使用FL进行p调优的模型。通过有效地利用协作中可用的更大的训练集,可以看到使用联合p调优的全局模型的明显优势,并且比单独使用数据进行训练的客户端实现更低的损失。
结论
总的来说,这篇文章强调了联邦p调优在使LLM适应下游任务方面的潜力,强调了FL在实现协作学习以保护隐私和提高模型性能方面的好处。一些关键的结论是:
1. 像GPT这样的大型语言模型已经彻底改变了NLP,为分类、问答、生成和头脑风暴等各种下游任务提供了多功能性。
2. 联邦学习通过共享模型参数而不是原始数据来解决与私有数据相关的挑战,从而确保隐私并降低遵从性风险。
3. 带有特定于任务的模块的微调LLM,如prompt-tuning或p-tuning,可以有效地适应特定的任务。
4. FL促进了协作训练和推理,从而提高了模型的性能。
来源:https://developer.nvidia.com/blog/adapting-llms-to-downstream-tasks-using-federated-learning-on-distributed-datasets/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消