











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






异步编程的未来:探索LangChain与LLM的AI技术
2023年07月11日 由 Alex 发表
788336
0
在本文中,我将介绍如何使用LangChain在长工作流中对LLM的异步调用。我们将通过一个包含完整代码的示例来比较顺序执行和异步调用。
以下是内容概述:
LangChain是一个用于开发由语言模型驱动的应用程序的框架。这就是LangChain的官方定义。这个框架是最近创建的,并且已经被用作构建由LLM驱动的工具的行业标准。
它是开源的,维护得很好,新功能在很短的时间内发布。
这个库的一个缺点是,由于这些特性是新的,我们不能使用Chat GPT来有效地帮助构建新代码。所以这意味着我们必须以“古老”的方式阅读文档、论坛和教程。
LangChain的文档。确实很好,但是没有很多具体的例子。
问题:我有一个数据帧有很多行,对于每一行我需要运行多个提示(链)到LLM,并将结果返回到我的数据帧。
当你有多行时,假设是10K,为每个响应运行3个提示(如果服务器没有过载),大约需要3-5秒,你最终需要等待数天才能完成工作流。
下面我将展示构建同步链的主要步骤和代码,并对数据子集进行计时。
对于这个例子,我将使用数据集Wine Reviews, license。
为此,我创建了两个链,一个用于摘要和情感,另一个将摘要作为输入提取特征。
下面是运行它的代码:
运行时间(10个示例):
这段代码的主要内容是链的构建块,如何以顺序方式运行它,以及完成这个循环所花费的时间。重要的是要记住,10个示例大约需要45秒,并且完整的数据集包含130K行。所以异步实现是在合理的时间内运行它的新希望。
有了问题和基线,让我们看看如何优化这段代码,使其运行得更快。
对于这个,我们将使用一个叫做异步调用的资源。
在我们的示例中,我们遍历数据帧的每一行,从中提取一些信息,将它们添加到提示符中,并调用GPT API以获得响应。响应之后,我们只需解析它并将其添加回数据帧。

这里的主要瓶颈是当我们调用GPT API时,因为我们的计算机必须等待该API的响应(大约3秒)。
因此,如果我们同时将所有调用发送到API,而不是安静地等待响应,会怎么样?这样,我们只需要等待一个响应,然后处理它们。这称为对API的异步调用。
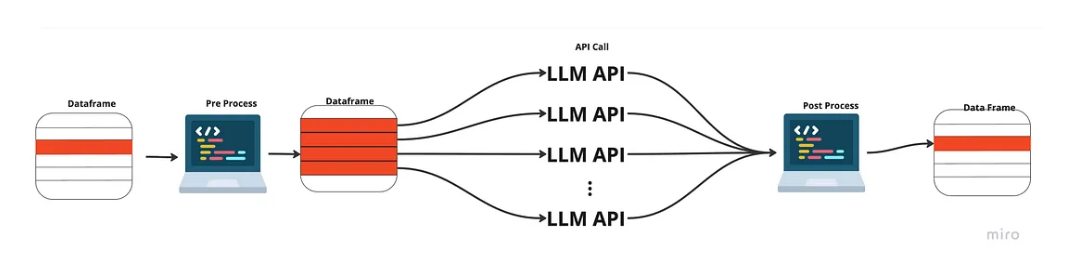
通过这种方式,我们按顺序进行预处理和后处理,但对 API 的调用不必等待最后一个响应返回后再发送下一个响应。
下面是异步链的代码:
在这段代码中,我们使用了async和await的Python语法。LangChain还提供了使用arun()函数异步运行链的代码。因此,在开始时,我们首先顺序处理每一行(可以优化),并创建多个“任务”,这些任务将并行等待API的响应,然后我们依次处理对最终所需格式的响应(也可以优化)。
运行时间(10个示例):
与顺序的相比:
我们可以看到在运行时几乎有10倍的改进。因此,对于较大的工作负载,我强烈建议使用这种方法。此外,我的代码充满了for循环,也可以进一步优化以提高性能。
当我不得不运行它时,我遇到了一些限制和障碍,我想和你们分享。
笔记本电脑不适合异步
在Jupyter笔记本上运行异步调用时,你可能会遇到一些问题。然而,只要问一下Chat GPT,它可能会帮你解决这个问题。我构建的代码是为了在.py文件中运行大型工作负载,因此可能需要进行一些更改才能在笔记本中运行。
输出键太多
第一个问题是我的链有多个键作为输出,而当时arun()只接受有一个键作为输出的链。所以为了解决这个问题,我必须把我的链分成两个。
并不是所有的链都是异步的
在我的提示中,我有一个使用矢量数据库进行示例和比较的逻辑,这需要顺序比较示例并将其添加到数据库中。这使得在整个链中对这个链接使用异步是不可行的。
LangChain是一个非常强大的工具,用于创建基于LLM的应用程序。
对于运行链的特定主题,对于高工作负载,我们看到了异步调用具有的潜在改进,因此我的建议是花时间了解代码在做什么,并拥有一个样板类(例如我的代码中提供的类)并异步运行它!
对于只需要调用一次API的小型工作负载或应用程序,没有必要异步执行,但是如果你有一个样板类,只需添加一个同步函数,这样就可以轻松地使用。
来源:https://towardsdatascience.com/async-calls-for-chains-with-langchain-3818c16062ed
以下是内容概述:
1. 基础知识:什么是LangChain
2. 如何使用LangChain运行同步链
3. 如何使用LangChain运行单个异步链
4. 使用异步链进行长工作流技巧
基础知识:什么是LangChain
LangChain是一个用于开发由语言模型驱动的应用程序的框架。这就是LangChain的官方定义。这个框架是最近创建的,并且已经被用作构建由LLM驱动的工具的行业标准。
它是开源的,维护得很好,新功能在很短的时间内发布。
这个库的一个缺点是,由于这些特性是新的,我们不能使用Chat GPT来有效地帮助构建新代码。所以这意味着我们必须以“古老”的方式阅读文档、论坛和教程。
LangChain的文档。确实很好,但是没有很多具体的例子。
如何使用LangChain运行同步链
问题:我有一个数据帧有很多行,对于每一行我需要运行多个提示(链)到LLM,并将结果返回到我的数据帧。
当你有多行时,假设是10K,为每个响应运行3个提示(如果服务器没有过载),大约需要3-5秒,你最终需要等待数天才能完成工作流。
下面我将展示构建同步链的主要步骤和代码,并对数据子集进行计时。
对于这个例子,我将使用数据集Wine Reviews, license。
为此,我创建了两个链,一个用于摘要和情感,另一个将摘要作为输入提取特征。
下面是运行它的代码:
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.chains import SequentialChain
from langchain.callbacks import get_openai_callback
import time
import pandas as pd
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
class SummaryChain:
"""
Class for creating a summary chain for extracting main sentiment and summary from wine reviews.
Attributes
----------
df : pandas.DataFrame
The dataframe that contains the wine reviews.
llm : langchain.chat_models.ChatOpenAI
The language model for extracting the summary.
Methods
----------
build_chain():
Builds a SequentialChain for sentiment extraction.
generate_sequentially():
Generates sentiment and summary sequentially for each review in the dataframe.
"""
def __init__(self, df, llm):
self.df = df
self.llm = llm
def build_chain(self):
"""
Builds a SequentialChain for sentiment extraction.
Returns
-------
tuple
A tuple containing the built SequentialChain, the output parser, and the response format.
"""
llm = self.llm
sentiment_schema = ResponseSchema(
name="sentiment",
description="The main sentiment of the review, limited to 3 words.",
)
summary_schema = ResponseSchema(
name="summary",
description="Brief Summary of the review, limited to one paragraph.",
)
sentiment_response_schemas = [sentiment_schema, summary_schema]
output_parser = StructuredOutputParser.from_response_schemas(
sentiment_response_schemas
)
response_format = output_parser.get_format_instructions()
sentiment_prompt = ChatPromptTemplate.from_template(
"""Act like an expert somellier. Your goal is to extract the main sentiment from wine reviews, delimited by triple dashes. Limit the sentiment to 3 words. \
Review: {review}
{response_format}
"""
)
sentiment_chain = LLMChain(
llm=llm, prompt=sentiment_prompt, output_key="sentiment"
)
chain = SequentialChain(
chains=[sentiment_chain],
input_variables=["review"] + ["response_format"],
output_variables=["sentiment"],
verbose=False,
)
return chain, output_parser, response_format
def generate_sequentially(self):
"""
Generates sentiment and summary sequentially for each review in the dataframe.
The extracted sentiments, summaries, and costs are added to the dataframe.
"""
df = self.df
chain, output_parser, response_format = self.build_chain()
for _, row in df.iterrows():
review = row["description"]
unique_id = row["unique_id"]
inputs = {
"review": review,
"response_format": response_format,
}
with get_openai_callback() as cb:
resp = chain.run(inputs)
cost = cb.total_cost
summary = output_parser.parse(resp)["summary"]
sentiment = output_parser.parse(resp)["sentiment"]
df.loc[
df["unique_id"] == unique_id, ["summary", "sentiment", "sentiment_cost"]
] = [summary, sentiment, cost]
class CharacteristicsChain:
"""
Class for creating a chain for extracting top five main characteristics of the wine.
Attributes
df : pandas.DataFrame
The dataframe that contains the wine reviews.
llm : langchain.chat_models.ChatOpenAI
The language model for extracting the characteristics.
Methods
build_chain():
Builds a SequentialChain for characteristic extraction.
generate_sequentially():
Generates characteristics sequentially for each wine in the dataframe.
"""
def __init__(self, df, llm):
self.df = df
self.llm = llm
def build_chain(self):
"""
Builds a SequentialChain for characteristic extraction.
Returns
tuple
A tuple containing the built SequentialChain, the output parser, and the response format.
"""
llm = self.llm
characteristics_schema = []
for i in range(1, 6):
characteristics_schema.append(
ResponseSchema(
name=f"characteristic_{i}",
description=f"The number {i} characteristic. One or two words long.",
)
)
output_parser = StructuredOutputParser.from_response_schemas(
characteristics_schema
)
response_format = output_parser.get_format_instructions()
characteristics_prompt = ChatPromptTemplate.from_template(
"""
Act like an expert somellier. You will receive the name, the summary of the review and the county of origin of a given wine, delimited by triple dashes.
Your goal is to extract the top five main characteristics of the wine.
Wine Name: {wine_name}
Country: {country}
Summary Review: {summary}
---
{response_format}
"""
)
characteristics_chain = LLMChain(
llm=llm, prompt=characteristics_prompt, output_key="characteristics"
)
chain = SequentialChain(
chains=[characteristics_chain],
input_variables=["wine_name", "summary", "country"] + ["response_format"], output_variables=["characteristics"],
verbose=False,
)
return chain, output_parser, response_format
def generate_sequentially(self):
"""
Generates characteristics sequentially for each wine in the dataframe.
The extracted characteristics and costs are added to the dataframe.
"""
df = self.df
chain, output_parser, response_format = self.build_chain()
for _, row in df.iterrows():
summary = row["summary"]
country = row["country"]
unique_id = row["unique_id"]
title = row["title"]
inputs = {
"summary": summary,
"wine_name": title,
"country": country,
"response_format": response_format,
}
with get_openai_callback() as cb:
resp = chain.run(inputs)
cost = cb.total_cost
characteristics = [
output_parser.parse(resp)[f"characteristic_{i}"] for i in range(1, 6)
]
df.loc[
df.unique_id == unique_id,
[
"characteristic_1",
"characteristic_2",
"characteristic_3",
"characteristic_4",
"characteristic_5",
"cost_characteristics",
],
] = characteristics + [cost]
######### RUNNING THE CODE #########
llm = ChatOpenAI(
temperature=0.0,
request_timeout=15,
model_name="gpt-3.5-turbo",
)
df = pd.read_csv('wine_subset.csv')
# Summary Chain - Sequential
s = time.perf_counter()
summary_chain = SummaryChain(llm=llm,df=df)
summary_chain.generate_sequentially()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Summary Chain (Sequential) executed in {elapsed:0.2f} seconds." + "\033[0m")
# Characteristics Chain - Sequential
s = time.perf_counter()
characteristics_chain = CharacteristicsChain(llm=llm,df=df)
characteristics_chain.generate_sequentially()
elapsed = time.perf_counter() - s
print("\033[1m" + f"Characteristics Chain (Sequential) executed in {elapsed:0.2f} seconds." + "\033[0m")
运行时间(10个示例):
摘要链(顺序)在22.59秒内执行。
特征链(顺序)在22.85秒内执行。
这段代码的主要内容是链的构建块,如何以顺序方式运行它,以及完成这个循环所花费的时间。重要的是要记住,10个示例大约需要45秒,并且完整的数据集包含130K行。所以异步实现是在合理的时间内运行它的新希望。
有了问题和基线,让我们看看如何优化这段代码,使其运行得更快。
如何使用LangChain运行单个异步链
对于这个,我们将使用一个叫做异步调用的资源。
在我们的示例中,我们遍历数据帧的每一行,从中提取一些信息,将它们添加到提示符中,并调用GPT API以获得响应。响应之后,我们只需解析它并将其添加回数据帧。
这里的主要瓶颈是当我们调用GPT API时,因为我们的计算机必须等待该API的响应(大约3秒)。
因此,如果我们同时将所有调用发送到API,而不是安静地等待响应,会怎么样?这样,我们只需要等待一个响应,然后处理它们。这称为对API的异步调用。
通过这种方式,我们按顺序进行预处理和后处理,但对 API 的调用不必等待最后一个响应返回后再发送下一个响应。
下面是异步链的代码:
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.chains import SequentialChain
import time
import pandas as pd
import asyncio
from langchain.callbacks import get_openai_callback
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
class SummaryChain:
"""
Class for creating a summary chain for extracting main sentiment and summary from wine reviews.
Attributes
df : pandas.DataFrame
The dataframe that contains the wine reviews.
llm : langchain.chat_models.ChatOpenAI
The language model for extracting the summary.
Methods
build_chain():
Builds a SequentialChain for sentiment extraction.
generate_concurrently():
Generates sentiment and summary concurrently for each review in the dataframe.
async_generate(chain, inputs, unique_id):
Asynchronous task to extract sentiment and summary from a single review.
"""
def __init__(self, df, llm):
self.df = df
self.llm = llm
def build_chain(self):
"""
Builds a SequentialChain for sentiment extraction.
Returns
tuple
A tuple containing the built SequentialChain, the output parser, and the response format.
"""
llm = self.llm
sentiment_schema = ResponseSchema(
name="sentiment",
description="The main sentiment of the review, limited to 3 words.",
)
summary_schema = ResponseSchema(
name="summary",
description="Brief Summary of the review, limited to one paragraph.",
)
sentiment_response_schemas = [sentiment_schema, summary_schema]
output_parser = StructuredOutputParser.from_response_schemas(
sentiment_response_schemas
)
response_format = output_parser.get_format_instructions()
## sentiment and Summary Chain
sentiment_prompt = ChatPromptTemplate.from_template(
"""Act like an expert somellier. Your goal is to extract the main sentiment from wine reviews, delimited by triple dashes. Limit the sentiment to 3 words. \
Review: {review}
{response_format}
"""
)
sentiment_chain = LLMChain(llm=llm, prompt=sentiment_prompt, output_key="sentiment")
chain = SequentialChain(
chains=[sentiment_chain],
input_variables=["review"] + ["response_format"],
output_variables=["sentiment"],
verbose=False,
)
return chain, output_parser, response_format
async def generate_concurrently(self):
"""
Generates sentiment and summary concurrently for each review in the dataframe.
The extracted sentiments, summaries, and costs are added to the dataframe.
"""
df = self.df
chain, output_parser, response_format = self.build_chain()
tasks = []
for _, row in df.iterrows():
review = row["description"]
unique_id = row["unique_id"]
inputs={
"review": review,
"response_format": response_format,
}
tasks.append(self.async_generate(chain, inputs, unique_id))
results = await asyncio.gather(*tasks)
for unique_id, response, cost in results:
summary = output_parser.parse(response)["summary"]
sentiment = output_parser.parse(response)["sentiment"]
df.loc[df["unique_id"] == unique_id, ["summary", "sentiment", "sentiment_cost"]] = [summary, sentiment, cost]
async def async_generate(self, chain, inputs, unique_id):
"""
Asynchronous task to extract sentiment and summary from a single review.
Parameters
chain : SequentialChain
The SequentialChain used for sentiment extraction.
inputs : dict
The inputs for the chain.
unique_id : any
The unique identifier for the review.
Returns
tuple
A tuple containing the unique identifier, the extracted sentiment and summary, and the cost.
"""
with get_openai_callback() as cb:
resp = await chain.arun(inputs)
return unique_id, resp, cb.total_cost
class CharacteristicsChain:
"""
Class for creating a chain for extracting top five main characteristics of the wine.
Attributes
df : pandas.DataFrame
The dataframe that contains the wine reviews.
llm : langchain.chat_models.ChatOpenAI
The language model for extracting the characteristics.
Methods
build_chain():
Builds a SequentialChain for characteristic extraction.
generate_concurrently():
Generates characteristics concurrently for each wine in the dataframe.
async_generate(chain, inputs, unique_id):
Asynchronous task to extract characteristics from a single wine.
"""
def __init__(self, df, llm):
self.df = df
self.llm = llm
def build_chain(self):
"""
Builds a SequentialChain for characteristic extraction.
Returns
tuple
A tuple containing the built SequentialChain, the output parser, and the response format.
"""
llm = self.llm
characteristics_schema = []
for i in range(1, 6):
characteristics_schema.append(
ResponseSchema(
name=f"characteristic_{i}",
description=f"The number {i} characteristic. One or two words long.",
)
)
output_parser = StructuredOutputParser.from_response_schemas(characteristics_schema)
response_format = output_parser.get_format_instructions()
characteristics_prompt = ChatPromptTemplate.from_template(
"""
Act like an expert somellier. You will receive the name, the summary of the review and the county of origin of a given wine, delimited by triple dashes.
Your goal is to extract the top five main characteristics of the wine.
Wine Name: {wine_name}
Country: {country}
Summary Review: {summary}
{response_format}
"""
)
characteristics_chain = LLMChain(
llm=llm, prompt=characteristics_prompt, output_key="characteristics"
)
chain = SequentialChain(
chains=[characteristics_chain],
input_variables=["wine_name", "summary", "country"]
+ ["response_format"],
output_variables=["characteristics"],
verbose=False,
)
return chain, output_parser, response_format
async def generate_concurrently(self):
"""
Generates characteristics concurrently for each wine in the dataframe.
The extracted characteristics and costs are added to the dataframe.
"""
df = self.df
chain, output_parser, response_format = self.build_chain()
asks = []
for _, row in df.iterrows():
summary = row["summary"]
country = row["country"]
unique_id = row["unique_id"]
title = row["title"]
inputs={
"summary": summary,
"wine_name": title,
"country":country,
"response_format": response_format,
}
tasks.append(self.async_generate(chain, inputs, unique_id))
results = await asyncio.gather(*tasks)
for unique_id, response, cost in results:
characteristic_1 = output_parser.parse(
response)["characteristic_1"]
characteristic_2 = output_parser.parse(
response)["characteristic_2"]
characteristic_3 = output_parser.parse(
response)["characteristic_3"]
characteristic_4 = output_parser.parse(
response)["characteristic_4"]
characteristic_5 = output_parser.parse(
response)["characteristic_5"]
df.loc[df.unique_id == unique_id, [
"characteristic_1",
"characteristic_2",
"characteristic_3",
"characteristic_4",
"characteristic_5",
"cost_characteristics"
]] = [
characteristic_1,
characteristic_2,
characteristic_3,
characteristic_4,
characteristic_5,
cost,
]
async def async_generate(self, chain, inputs, unique_id):
"""
Asynchronous task to extract characteristics from a single wine.
Parameters
chain : SequentialChain
The SequentialChain used for characteristic extraction.
inputs : dict
The inputs for the chain.
unique_id : any
The unique identifier for the wine.
Returns
tuple
A tuple containing the unique identifier, the extracted characteristics, and the cost.
"""
with get_openai_callback() as cb:
resp = await chain.arun(inputs)
return unique_id, resp, cb.total_cost
######### RUNNING THE CODE #########
llm = ChatOpenAI(
temperature=0.0,
request_timeout=15,
model_name="gpt-3.5-turbo",
)
df = pd.read_csv('wine_subset.csv')
# Issue Chain
s = time.perf_counter()
summary_chain = SummaryChain(llm=llm,df=df)
asyncio.run(summary_chain.generate_concurrently())
elapsed = time.perf_counter() - s
print("\033[1m" + f"Summary Chain (Async) executed in {elapsed:0.2f} seconds." + "\033[0m")
# Characteristics Chain
s = time.perf_counter()
characteristics_chain = CharacteristicsChain(llm=llm,df=df)
asyncio.run(characteristics_chain.generate_concurrently())
elapsed = time.perf_counter() - s
print("\033[1m" + f"Characteristics Chain (Async) executed in {elapsed:0.2f} seconds." + "\033[0m")
df.to_csv('checkpoint.csv')
在这段代码中,我们使用了async和await的Python语法。LangChain还提供了使用arun()函数异步运行链的代码。因此,在开始时,我们首先顺序处理每一行(可以优化),并创建多个“任务”,这些任务将并行等待API的响应,然后我们依次处理对最终所需格式的响应(也可以优化)。
运行时间(10个示例):
摘要链(异步)在3.35秒内执行。
特征链(异步)在2.49秒内执行。
与顺序的相比:
摘要链(顺序)在22.59秒内执行。
特征链(顺序)在22.85秒内执行。
我们可以看到在运行时几乎有10倍的改进。因此,对于较大的工作负载,我强烈建议使用这种方法。此外,我的代码充满了for循环,也可以进一步优化以提高性能。
使用异步链进行长工作流的实现技巧
当我不得不运行它时,我遇到了一些限制和障碍,我想和你们分享。
笔记本电脑不适合异步
在Jupyter笔记本上运行异步调用时,你可能会遇到一些问题。然而,只要问一下Chat GPT,它可能会帮你解决这个问题。我构建的代码是为了在.py文件中运行大型工作负载,因此可能需要进行一些更改才能在笔记本中运行。
输出键太多
第一个问题是我的链有多个键作为输出,而当时arun()只接受有一个键作为输出的链。所以为了解决这个问题,我必须把我的链分成两个。
并不是所有的链都是异步的
在我的提示中,我有一个使用矢量数据库进行示例和比较的逻辑,这需要顺序比较示例并将其添加到数据库中。这使得在整个链中对这个链接使用异步是不可行的。
结论
LangChain是一个非常强大的工具,用于创建基于LLM的应用程序。
对于运行链的特定主题,对于高工作负载,我们看到了异步调用具有的潜在改进,因此我的建议是花时间了解代码在做什么,并拥有一个样板类(例如我的代码中提供的类)并异步运行它!
对于只需要调用一次API的小型工作负载或应用程序,没有必要异步执行,但是如果你有一个样板类,只需添加一个同步函数,这样就可以轻松地使用。
来源:https://towardsdatascience.com/async-calls-for-chains-with-langchain-3818c16062ed

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消