











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软和TikTok使生成式人工智能具有一种“记忆”
2023年07月03日 由 daydream 发表
911679
0
当你在类似ChatGPT这样的生成式人工智能(AI)程序的提示中输入内容时,该程序会根据你输入的内容以及之前输入的内容给出回应。
你可以将这个聊天记录视为一种记忆形式。但是根据来自多个机构的研究人员的观点,这种记忆还不够,他们希望赋予生成式人工智能一种更有组织的记忆,可以增强其生成的内容。
加州大学圣塔芭芭拉分校的研究员Weizhi Wang和来自微软的合作者撰写的一篇论文,题为“Augmenting Language Models with Long-Term Memory”,并发布在arXiv预印论文服务器上,为语言模型添加了一个新组件。
问题在于ChatGPT和类似的程序无法一次性输入足够长的文本来形成非常长的上下文。
正如Wang和他的团队观察到的那样,"现有LLM(长期记忆模型)的输入长度限制阻碍了它们在处理长篇信息的能力,而这在现实场景中是至关重要的,因为长篇信息的处理能力超过固定大小的会话范围。"
以OpenAI的GPT-3为例,它最多能够接受2,000个标记作为输入,这包括字符或单词。你无法将一个包含5,000个字的文章或一部70,000个字的小说输入到程序中。
可以不断扩展输入的"窗口",但这会遇到一个棘手的计算问题。注意机制是所有大型语言程序(包括ChatGPT和GPT-4)的关键工具,它具有“二次”的计算复杂度(参见计算的“时间复杂度”)。这种复杂度意味着ChatGPT生成答案所需的时间与输入数据量的平方成正比。增加窗口的大小会增加所需的计算量。
正如Wang和他的团队指出的,一些学者已经试图提出一种简易的记忆机制。去年,Google的Yuhuai Wu等人提出了他们称之为Mememoizing Transformer的方法,它可以将过去的答案保存在记忆中以供将来使用。这个过程使其可以一次性处理65,000个标记。
但是Wang和他的团队指出,数据可能会变得“陈旧”。在训练Memory Transformer的过程中,记忆中的某些内容与神经网络不同步,因为神经权重或参数会被更新。
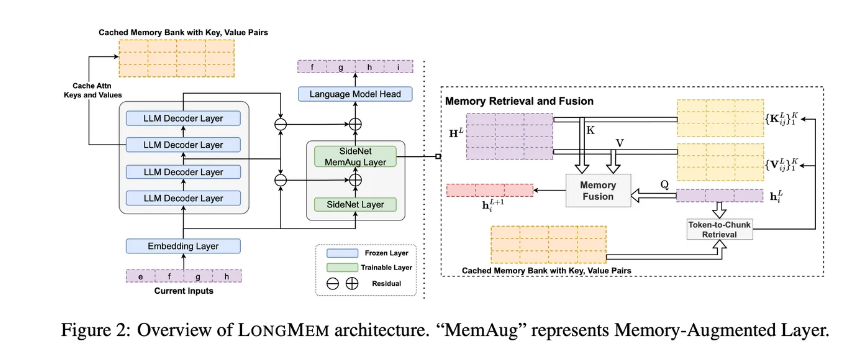
Wang和他的团队提出的解决方案被称为“语言模型增强与长期记忆”,或称为LongMem。它使用了一个传统的大型语言模型,并具有两个功能。在分析输入时,它将其中一些内容存储到记忆库中。它还将每个当前提示的输出传递给第二个名为SideNet的神经网络。
SideNet,也是一个语言模型,与第一个网络类似,其任务是将用户的当前提示与记忆内容进行比较,看是否存在相关的匹配。与Memory Transformer不同,SideNet可以独立于主语言模型进行训练。这样,它在选择不会过时的记忆内容方面变得越来越好。
Wang和他的团队进行了一些测试,比较了LongMem、Memorizing Transformer以及OpenAI的GPT-2语言模型。他们还将LongMem与其他语言模型的文献报道结果进行了比较,包括拥有1750亿参数的GPT-3。
他们使用了三个基于大量文本摘要的数据集进行任务测试,包括Project Gutenberg、arXiv文件服务器和ChapterBreak。
为了让你对这些任务的规模有所了解,ChapterBreak是由马萨诸塞大学阿默斯特分校的Simeng Sun等人于去年推出的,它会接收整本书的文本并测试语言模型,看看在给定一个章节作为输入的情况下,它能否准确地识别出若干候选段落中哪一个是下一章的开头。这样的任务需要对长距离依赖关系,如事件的时空变化和一种叫做"回溯"的技术进行深入理解,其中"下一章是对叙事中更早时刻的'回顾'。"引用了以往的内容。
而这些任务涉及处理数万甚至数十万个标记。
当Sun和他的团队进行这些ChapterBreak测试时,他们在去年的报告中称,主流语言模型“遇到了困难”。例如,大型的GPT-3只有28%的准确率。
然而,Wang和他的团队报告称,LongMem程序“令人惊讶地”击败了所有标准语言模型,包括GPT-3,获得了40.5%的最先进分数,尽管LongMem只有约6亿个神经参数,远少于GPT-3的1750亿个。
“Wang和他的团队写道:”在这些数据集上的显著改进表明,LONGMEM可以理解缓存记忆中过去的长上下文,从而很好地完成对未来输入的语言建模。"
微软的这项工作呼应了字节跳动(抖音的母公司)最近的研究。
在一篇于4月份发布在arXiv上的论文中,题为“Unleashing Infin-Length Input Capacity for Large-scale Language Models with Self-controlled Memory System”,字节跳动的研究员Xinnian Liang和他的同事开发了一个附加程序,使任何大型语言模型都能够存储非常长的对话序列。
实际上,他们认为,这个程序可以显著提高程序将每个新提示放入上下文并据此做出适当回应的能力,甚至比ChatGPT更好。
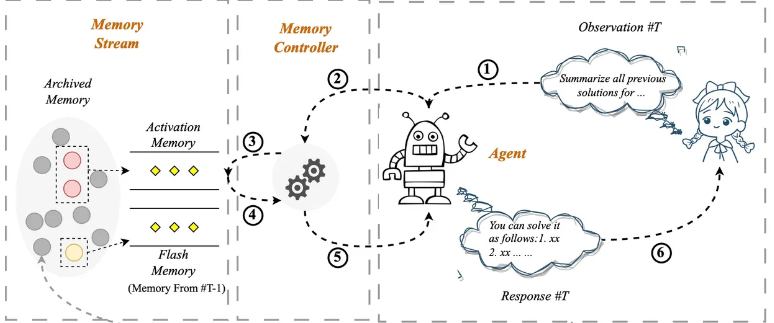
在所谓的“Self-Control Memory System”(SCM)中,用户在提示中键入的输入经由内存控制器进行评估,以判断是否需要查阅名为内存流的存档内存系统,该系统包含用户与程序之间的所有过去互动。它与Wang团队的SideNet及其相应的记忆库非常相似。
如果需要记忆,过去的输入集合将通过类似Pinecone的矢量数据库工具进行访问。用户的输入作为查询,与数据库中的内容进行相关性匹配。
有些用户查询不需要记忆,例如"给我讲个笑话"这样的随机请求,任何语言模型都可以处理。但是像"你还记得我们上周关于健身饮食的结论吗?"这样的用户提示需要访问过去的聊天记录。

在一种巧妙的处理中,用户的提示和所检索的记忆被合并在一起,论文称之为"输入融合" —— 而正是这段合并的文本成为语言模型的实际输入,进而生成其回应。
结果就是SCM在涉及到在对话中回顾数百轮早期内容的任务中能够超越ChatGPT,Liang和他的团队写道。他们将SCM连接到一个名为text-davinci-003的GPT-3版本,并测试它与ChatGPT在相同输入下的表现。

在一个包含4000个标记的超过100轮的对话系列中,当人类提示机器回忆起会话开始时所讨论的人的爱好时,"SCM系统对查询提供了准确的回答,展示了出色的记忆增强能力",他们写道,而与此形成对比的是,"与此相反,ChatGPT似乎被大量无关的历史数据分散了注意力。"
这项研究还可以对数千字长的文本进行摘要,例如报告。它通过迭代地摘要文本来实现这一点,也就是将第一个摘要存储在内存流中,然后与之前的摘要结合生成下一个摘要,依此类推。
SCM还可以使那些不是聊天机器人的大型语言模型表现得像聊天机器人一样。他们写道:“实验结果表明,我们的SCM系统使那些并非针对多轮对话进行优化的LLM(大型语言模型)能够达到与ChatGPT相当的多轮对话能力。"
微软和字节跳动的研究工作都可以看作是扩展语言模型最初意图的延伸。在ChatGPT和其前身——谷歌的Transformer之前,自然语言任务通常使用称为循环神经网络(RNN)的方式进行。循环神经网络是一种能够回溯早期输入数据并将其与当前输入进行比较的算法。
Transformer和像ChatGPT这样的LLM(大型语言模型)用更简单的方法——注意力机制取代了循环神经网络。注意力机制可以自动比较过去和现在的输入,因此过去的内容始终被纳入考量。
因此,微软和字节跳动的研究工作简单地通过显式地设计算法来更有组织地回忆过去的元素,从而扩展了注意力机制。添加记忆成为了一种基本的调整,很可能成为未来大型语言模型的标准部分,使得程序更常见地能够与过去的内容(如聊天记录)建立联系,或者处理非常长篇的整个文本。
来源:https://www.zdnet.com/article/microsoft-tiktok-give-generative-ai-a-sort-of-memory/
你可以将这个聊天记录视为一种记忆形式。但是根据来自多个机构的研究人员的观点,这种记忆还不够,他们希望赋予生成式人工智能一种更有组织的记忆,可以增强其生成的内容。
加州大学圣塔芭芭拉分校的研究员Weizhi Wang和来自微软的合作者撰写的一篇论文,题为“Augmenting Language Models with Long-Term Memory”,并发布在arXiv预印论文服务器上,为语言模型添加了一个新组件。
问题在于ChatGPT和类似的程序无法一次性输入足够长的文本来形成非常长的上下文。
正如Wang和他的团队观察到的那样,"现有LLM(长期记忆模型)的输入长度限制阻碍了它们在处理长篇信息的能力,而这在现实场景中是至关重要的,因为长篇信息的处理能力超过固定大小的会话范围。"
以OpenAI的GPT-3为例,它最多能够接受2,000个标记作为输入,这包括字符或单词。你无法将一个包含5,000个字的文章或一部70,000个字的小说输入到程序中。
可以不断扩展输入的"窗口",但这会遇到一个棘手的计算问题。注意机制是所有大型语言程序(包括ChatGPT和GPT-4)的关键工具,它具有“二次”的计算复杂度(参见计算的“时间复杂度”)。这种复杂度意味着ChatGPT生成答案所需的时间与输入数据量的平方成正比。增加窗口的大小会增加所需的计算量。
正如Wang和他的团队指出的,一些学者已经试图提出一种简易的记忆机制。去年,Google的Yuhuai Wu等人提出了他们称之为Mememoizing Transformer的方法,它可以将过去的答案保存在记忆中以供将来使用。这个过程使其可以一次性处理65,000个标记。
但是Wang和他的团队指出,数据可能会变得“陈旧”。在训练Memory Transformer的过程中,记忆中的某些内容与神经网络不同步,因为神经权重或参数会被更新。
Wang和他的团队提出的解决方案被称为“语言模型增强与长期记忆”,或称为LongMem。它使用了一个传统的大型语言模型,并具有两个功能。在分析输入时,它将其中一些内容存储到记忆库中。它还将每个当前提示的输出传递给第二个名为SideNet的神经网络。
SideNet,也是一个语言模型,与第一个网络类似,其任务是将用户的当前提示与记忆内容进行比较,看是否存在相关的匹配。与Memory Transformer不同,SideNet可以独立于主语言模型进行训练。这样,它在选择不会过时的记忆内容方面变得越来越好。
Wang和他的团队进行了一些测试,比较了LongMem、Memorizing Transformer以及OpenAI的GPT-2语言模型。他们还将LongMem与其他语言模型的文献报道结果进行了比较,包括拥有1750亿参数的GPT-3。
他们使用了三个基于大量文本摘要的数据集进行任务测试,包括Project Gutenberg、arXiv文件服务器和ChapterBreak。
为了让你对这些任务的规模有所了解,ChapterBreak是由马萨诸塞大学阿默斯特分校的Simeng Sun等人于去年推出的,它会接收整本书的文本并测试语言模型,看看在给定一个章节作为输入的情况下,它能否准确地识别出若干候选段落中哪一个是下一章的开头。这样的任务需要对长距离依赖关系,如事件的时空变化和一种叫做"回溯"的技术进行深入理解,其中"下一章是对叙事中更早时刻的'回顾'。"引用了以往的内容。
而这些任务涉及处理数万甚至数十万个标记。
当Sun和他的团队进行这些ChapterBreak测试时,他们在去年的报告中称,主流语言模型“遇到了困难”。例如,大型的GPT-3只有28%的准确率。
然而,Wang和他的团队报告称,LongMem程序“令人惊讶地”击败了所有标准语言模型,包括GPT-3,获得了40.5%的最先进分数,尽管LongMem只有约6亿个神经参数,远少于GPT-3的1750亿个。
“Wang和他的团队写道:”在这些数据集上的显著改进表明,LONGMEM可以理解缓存记忆中过去的长上下文,从而很好地完成对未来输入的语言建模。"
微软的这项工作呼应了字节跳动(抖音的母公司)最近的研究。
在一篇于4月份发布在arXiv上的论文中,题为“Unleashing Infin-Length Input Capacity for Large-scale Language Models with Self-controlled Memory System”,字节跳动的研究员Xinnian Liang和他的同事开发了一个附加程序,使任何大型语言模型都能够存储非常长的对话序列。
实际上,他们认为,这个程序可以显著提高程序将每个新提示放入上下文并据此做出适当回应的能力,甚至比ChatGPT更好。
在所谓的“Self-Control Memory System”(SCM)中,用户在提示中键入的输入经由内存控制器进行评估,以判断是否需要查阅名为内存流的存档内存系统,该系统包含用户与程序之间的所有过去互动。它与Wang团队的SideNet及其相应的记忆库非常相似。
如果需要记忆,过去的输入集合将通过类似Pinecone的矢量数据库工具进行访问。用户的输入作为查询,与数据库中的内容进行相关性匹配。
有些用户查询不需要记忆,例如"给我讲个笑话"这样的随机请求,任何语言模型都可以处理。但是像"你还记得我们上周关于健身饮食的结论吗?"这样的用户提示需要访问过去的聊天记录。
在一种巧妙的处理中,用户的提示和所检索的记忆被合并在一起,论文称之为"输入融合" —— 而正是这段合并的文本成为语言模型的实际输入,进而生成其回应。
结果就是SCM在涉及到在对话中回顾数百轮早期内容的任务中能够超越ChatGPT,Liang和他的团队写道。他们将SCM连接到一个名为text-davinci-003的GPT-3版本,并测试它与ChatGPT在相同输入下的表现。
在一个包含4000个标记的超过100轮的对话系列中,当人类提示机器回忆起会话开始时所讨论的人的爱好时,"SCM系统对查询提供了准确的回答,展示了出色的记忆增强能力",他们写道,而与此形成对比的是,"与此相反,ChatGPT似乎被大量无关的历史数据分散了注意力。"
这项研究还可以对数千字长的文本进行摘要,例如报告。它通过迭代地摘要文本来实现这一点,也就是将第一个摘要存储在内存流中,然后与之前的摘要结合生成下一个摘要,依此类推。
SCM还可以使那些不是聊天机器人的大型语言模型表现得像聊天机器人一样。他们写道:“实验结果表明,我们的SCM系统使那些并非针对多轮对话进行优化的LLM(大型语言模型)能够达到与ChatGPT相当的多轮对话能力。"
微软和字节跳动的研究工作都可以看作是扩展语言模型最初意图的延伸。在ChatGPT和其前身——谷歌的Transformer之前,自然语言任务通常使用称为循环神经网络(RNN)的方式进行。循环神经网络是一种能够回溯早期输入数据并将其与当前输入进行比较的算法。
Transformer和像ChatGPT这样的LLM(大型语言模型)用更简单的方法——注意力机制取代了循环神经网络。注意力机制可以自动比较过去和现在的输入,因此过去的内容始终被纳入考量。
因此,微软和字节跳动的研究工作简单地通过显式地设计算法来更有组织地回忆过去的元素,从而扩展了注意力机制。添加记忆成为了一种基本的调整,很可能成为未来大型语言模型的标准部分,使得程序更常见地能够与过去的内容(如聊天记录)建立联系,或者处理非常长篇的整个文本。
来源:https://www.zdnet.com/article/microsoft-tiktok-give-generative-ai-a-sort-of-memory/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消