











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






比较和评估 TorchVision 的物体检测模型
2023年07月03日 由 Alex 发表
657769
0
介绍
目标检测是计算机视觉中最流行的机器学习应用之一。检测模型预测图像中每个不同物体的类别类型和位置。对象检测模型具有广泛的应用,包括制造、监视、医疗保健等。TorchVision是一个Python包,它为计算机视觉用例扩展了PyTorch框架。但是如何系统地为特定用例找到最佳模型呢?本文将使用Comet来记录我的实验数据。
什么是目标检测
对象检测是一项计算机视觉任务,旨在识别图像中对象的实例并将其分配到特定的类。在较低的层次上,对象检测试图回答问题:“什么对象在哪里?”

探测海洋动物
目标检测算法一般分为两类:单阶段(RetinaNet、SSD、FCOS、YOLO等)和两阶段(Fast RCNN、Mask RCNN、FPN等)。在两阶段检测器中,一个模型用于提取目标的广义区域,另一个模型用于分类和进一步细化目标的位置。单级探测器一步就完成了这一切。单级探测器往往比两级探测器更快,计算成本更低,但精确度较低。
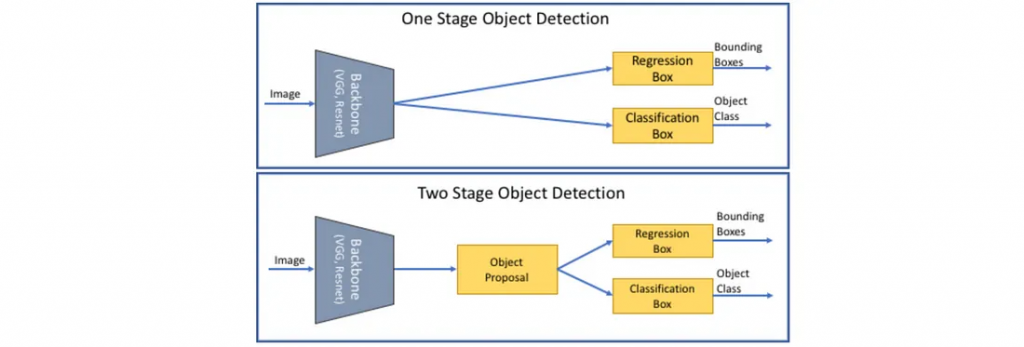
微调预训练模型
最好的目标检测模型是在成千上万的标记图像上训练的。更重要的是,图像数据集本身的计算处理成本很高。从头开始训练目标检测模型需要大量的时间和资源,而这些时间和资源并不总是可用的。训练几个目标检测模型进行比较需要更多的时间和资源。值得庆幸的是,我们不需要这么做。相反,我们可以使用迁移学习或微调预训练模型。
从本质上讲,这两种方法都允许我们利用从一个任务中学到的权重和偏差,并将它们重新用于新任务。通过利用预训练模型中的特征表示,我们不必从头开始训练新模型,从而节省了时间和计算资源。更重要的是,这些方法可以以很少的开销快速提高模型性能。
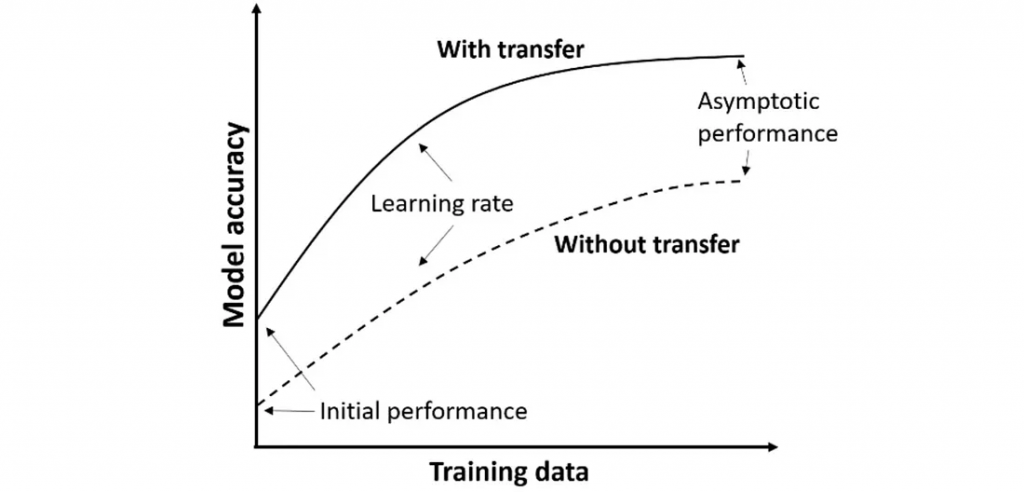
迁移学习和微调是相似的过程,但有一个关键的区别。在迁移学习中,所有之前训练过的层都被冻结,并且(可选地)添加额外的层用于重新训练。在微调中,所有之前训练过的层都被重新训练,但学习率非常低。在这两种情况下,模型通常会看到初始性能提高,改进斜率更陡,最终性能提高。
TorchVision的预训练模型
在实际应用中,我们经常做出选择来平衡准确性和速度。如果我们不能在生产环境中复制这些环境,那么模型在一组给定环境下的性能可能就无关紧要了。因此,在寻找“最佳”对象检测模型时,监视与你的特定用例相关的各种指标变得至关重要。
TorchVision的检测模块已经内置了几个预训练的模型。对于本教程,我们将比较Fast-RCNN,、Faster-RCNN,、Mask-RCNN、 RetinaNet和FCOS与ResNet50的MobileNet v2骨干网。这些模型中的每一个先前都是在COCO数据集上训练的。我们将下载训练好的模型,替换分类器头部以反映我们的目标类,并根据我们自己的数据上重新训练模型。
图像数据格式
在计算机视觉中,图像被表示为像素强度值矩阵。黑白(灰度)图像通常是二维的,而彩色图像通常是三维的,每个“层”代表红色、蓝色和绿色像素。
正如有多种表示图像的方法一样,我们也有多种表示标签和预测的方法。在本教程的完整代码中,我们将提供记录边界框,分割蒙版和多边形注释到实验跟踪工具的方法。但是当比较torchvision模型时,我们将只使用边界框,因为不是所有的模型都能够计算其他类型的预测。
更复杂的是,并非所有算法都以相同的方式格式化边界框注释。下面我们列出了一些你可能会遇到的最常见的边界框格式,但在本文中,我们将重点关注Pascal VOC和COCO格式。
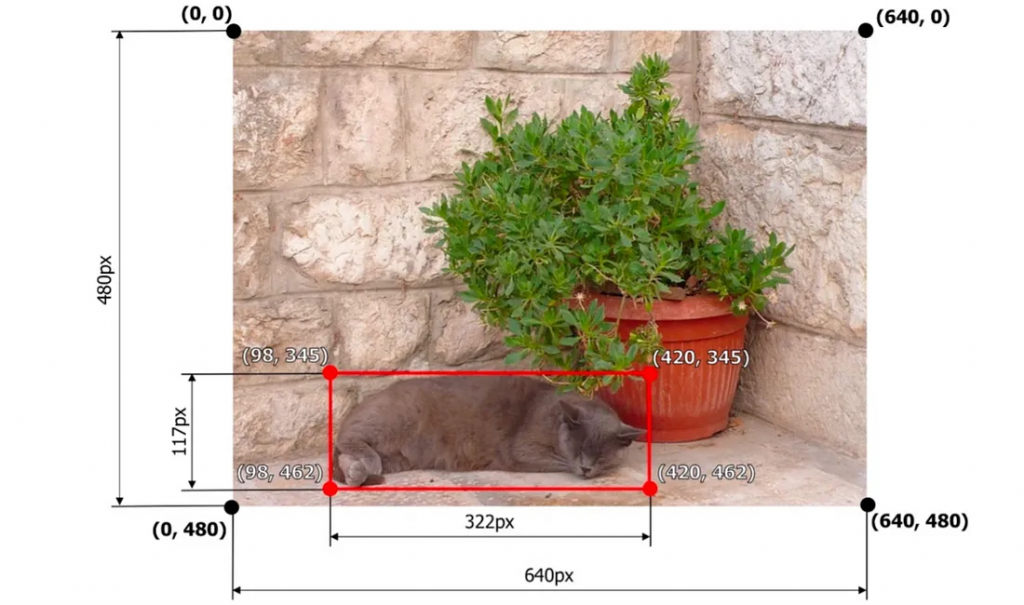
Pascal VOC:[xmin, ymin, xmax, ymax] → [98, 345, 420, 462]
Albumentations:normalized([x_min, y_min, x_max, y_max]) → [0.153125, 0.71875, 0.65625, 0.9625]
COCO:[xmin, ymin, width, height] → [98, 345, 322, 117]
YOLO:normalized([x_center, y_center, width, height]) → [0.4046875, 0.8614583, 0.503125, 0.24375]
目标检测的评价指标
评估目标检测模型的一种简单方法可能是二元分类(“匹配”或“不匹配”、“1”或“0”),但这种方法几乎没有留下细微差别的空间。我们可以做得更好!
联合路口(IoU)
用来比较个别边界框的标准评估指标是交并比,简称IoU。交并比评估了真实边界框与预测边界框之间的重叠程度,其取值范围在0到1之间。
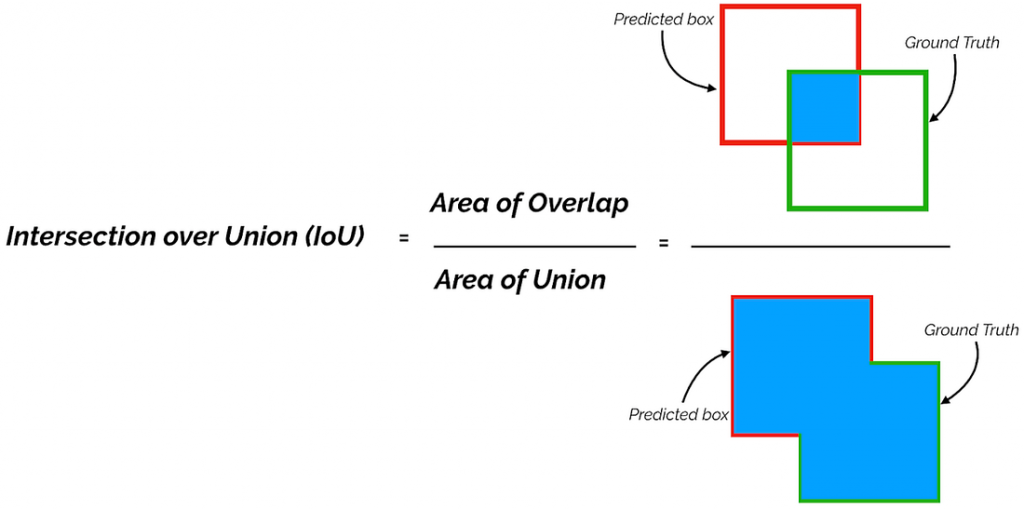
Union 上的交叉点,图片来自 Shivy Yohanandan 《Towards Data Science》

地面真实边界框和预测边界框的交集和并集之间的差异
对于图像中的每组边界框,计算IoU,并应用一个阈值。如果IoU达到阈值,则将其标记为“真阳性(true positive)”。所有未被标记为“真阳性”的预测被标记为“假阳性(false positive)”,而在“真实结果(ground truth)”注释列表中剩下的项目被标记为“假阴性(false negative)”。将检测结果标记为TP(真阳性)、FP(假阳性)或FN(假阴性)的决策完全依赖于IoU阈值的选择。IoU阈值通常设定为0.5,但你可以尝试不同的数值。计算了混淆矩阵后,就可以计算精确度和召回率。

真阳性、假阳性和假阴性;请注意,我们不计算对象检测中的真阴性。
平均精确度(mAP)和平均召回率(mAR)
精度(也称为特异性)是模型在识别相关对象时的精确程度。精度方程为:
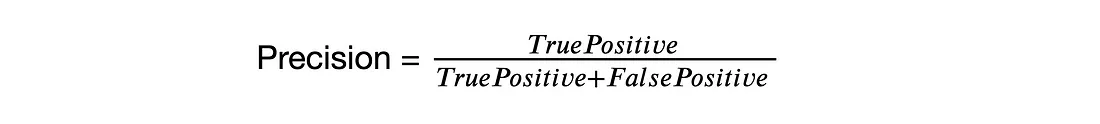
召回率(也称为灵敏度)衡量模型检测所有基本事实的能力。召回率方程为:
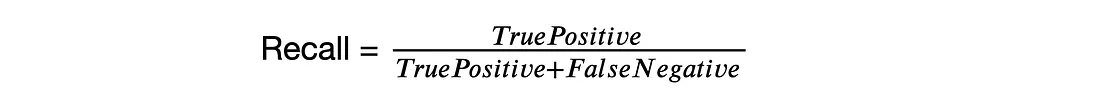
在完美的世界里,我们的完美模型的精度和召回率为1,这意味着它预测了零假阴性和零假阳性。但在现实世界中,这通常是不可能实现的。准确率-召回率曲线绘制了不同置信度阈值下的准确率与召回率的关系。该曲线下的面积也称为平均精度(AP)。平均召回(AR)描述了召回-loU曲线下面积的两倍。
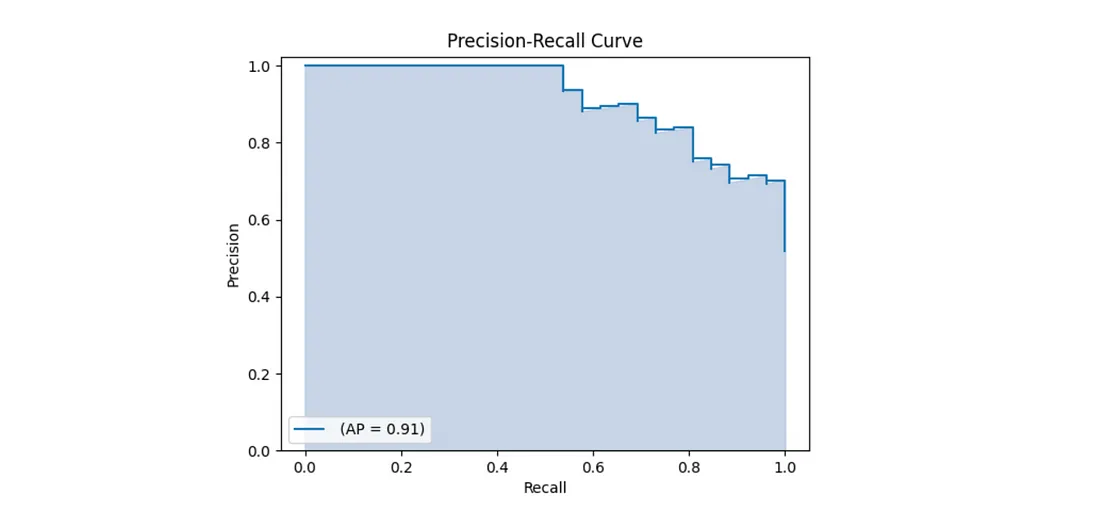
平均精度等于PR曲线下的面积
平均平均精度(mAP)和平均召回率(mAR)是通过在所有类别或所有IoU阈值上取AP或AR的加权平均值来计算的。它们是对象检测的两个最常见的评估指标,用于评估流行的计算机视觉竞赛(如COCO和Pascal VOC挑战)中的提交。我们可以从mAP和mAR中获得许多其他指标,包括跨尺度的mAP,不同的IoU阈值,以及每个图像的最小检测数量。
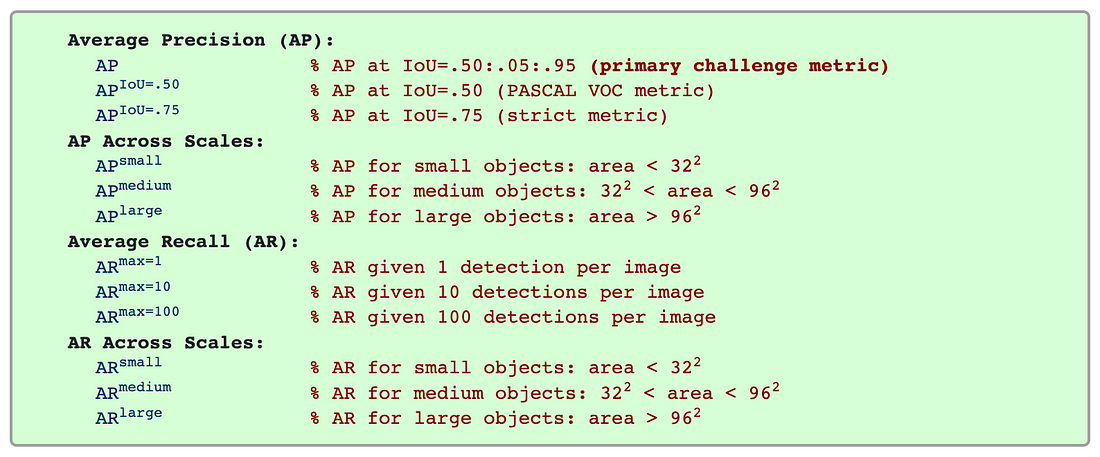
其他指标
如果我们正在构建一个模型来检测非常大的对象(相对于图像的视野),我们可能愿意考虑具有较差的“AP_small”分数的模型,因为这个指标与我们的用例不太相关。如果我们打算使用我们的模型来帮助医学诊断,我们可能会更加强调mAR值而不是mAP值,因为不遗漏任何阳性样本可能比遗漏阴性样本更重要。
在本文中,我们使用由COCO评估器和torchmetrics.detection模块计算的mAP和mAR值的组合。我们还将把所有相关的值记录到DataFrame中,以便更全面地了解不同模型在不同场景中的表现。最后,我们将相应地选择“最佳”模型。
比较目标检测模型的挑战
由于许多原因,比较对象检测模型可能具有挑战性。当涉及到输入大小和形状、注释格式和其他数据集属性时,不同的模型有不同的要求。超参数因算法而异,跟踪哪个值产生哪个结果可能很快就会变得乏味和压倒性。
大多数计算机视觉管道都以某种形式包含图像增强,因此数据集版本控制对于重复性和可解释性至关重要。更重要的是,当涉及到对象检测时,性能指标只能说明部分情况。通常,有必要可视化预测注释,以了解哪些地方是正确的,哪些地方是错误的。
更重要的是,图像数据集本身的计算处理成本很高。从头开始训练目标检测模型需要大量的时间和资源,而这些时间和资源并不总是可用的。训练多个目标检测模型进行比较需要更多的时间和资源。
在实际中,我们经常做出选择来平衡准确性和速度。如果我们不能在生产环境中复制这些环境,那么模型在给定环境下的性能可能就无关紧要了。因此,在寻找“最佳”对象检测模型时,监视与你的特定用例相关的广泛度量变得至关重要。
使用Comet进行对象检测
显然,比较目标检测模型并不像最小化单个损失函数那么简单。我们需要计算和记录相当广泛的指标,其中一些需要可视化才能完全理解,每个模型都有自己的图形定义、超参数集、代码输出和其他特征。为了帮助跟踪所有这些移动的部分,我们将记录我们的输入、指标和输出到实验跟踪工具Comet。通过在实验跟踪工具中可视化我们的数据,我们将能够更全面地了解我们的每个模型的行为,在哪种情况下以及使用哪种数据。
在本文中,我们将使用Penn-Fudan数据集,该数据集由170张图像组成,标有345个行人实例。行人检测有多种应用,包括监视、训练自动驾驶汽车和其他交通安全应用。由于我们使用的是PyTorch,我们需要定义一个自定义数据集类,它继承自torch.utils.data.Dataset类。

来自 PennFudan 数据集的示例图像,带有边界框和掩模标签
所有的模型在TorchVision的检测模块使用Pascal VOC格式,因此我们将在Dataset类中相应地格式化边界框。然后,我们需要将模型的预测标签从Pascal VOC转换为COCO格式,以便与COCO评估器和Comet一起使用。
单实验视图
为了很好地理解我们的每个模型是如何执行的,以及使用哪些超参数,我们将从在实验级别检查我们的结果开始。
存储超参数
跟踪我们的超参数对于重复性和可解释性至关重要。模型超参数可以影响模型性能、计算选择和保留哪些信息用于分析。超参数因算法而异,有些比其他更重要,因此这个关键任务很快就会变得乏味和混乱。
在这里,我们只用一个命令记录重要的超参数。对于我们的项目,我们将监视以下超参数,我们可以通过简单地编辑相关的键值对来调整:
hyper_params = {
"lr" : 0.0005,
"momentum" : 0.9,
"weight_decay" : 0.0005,
"step_size" : 3,
"gamma" : 0.1,
"num_epochs" : 1,
"num_classes" : 2,
"model_name": "mask_rcnn",
"backbone" : "retinanet50",
"feature_extract": False
}
experiment.log_parameters(hyper_params)有时候,对一种模式有效的指标可能完全不适用于另一种模式。例如,FCOS模型倾向于与爆炸梯度做斗争。当使用它时,我们必须显著降低学习率以适应这一点。然而,如果我们在像Fast-RCNN这样的模型(通常是我们表现最好的模型之一)上使用降低的学习率,它的表现就会异常糟糕,因为它无法真正“学习”我们数据集的特征映射。
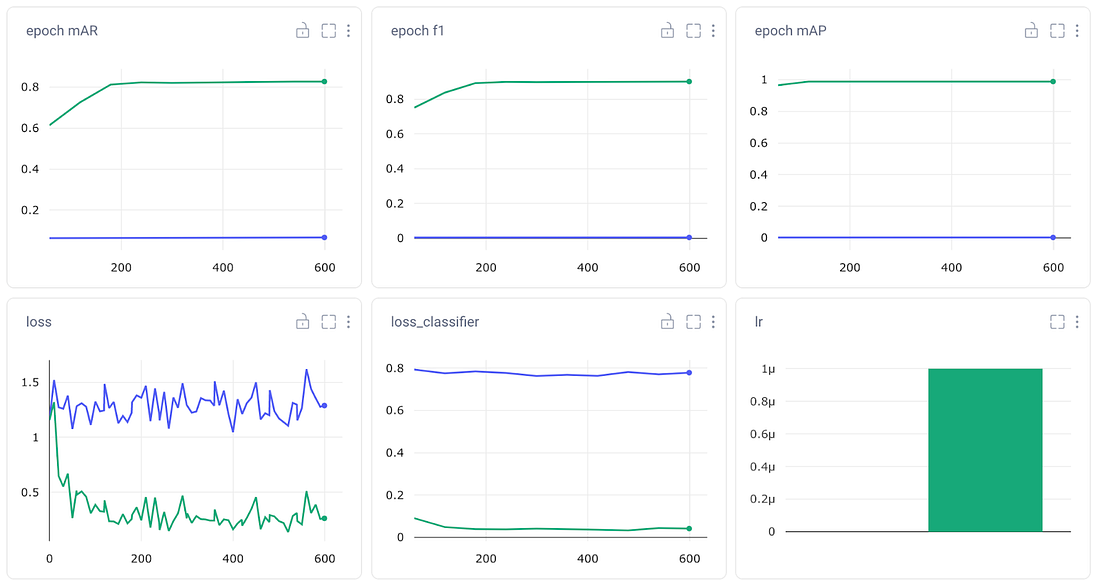
由于我们在本文中专注于比较不同的模型,我们将主要保持超参数恒定(学习率除外)。但是,如果我们希望优化单个模型的超参数,我们也可以将值列表传递给每个超参数键,并使用优化器对它们进行迭代。
可视化输出
系统指标
由于对象检测是一项资源密集型任务,我们还需要监控系统指标,包括CPU和GPU的使用情况。这也可以帮助诊断管道中的瓶颈,帮助提高再现性,并调试崩溃的实验。
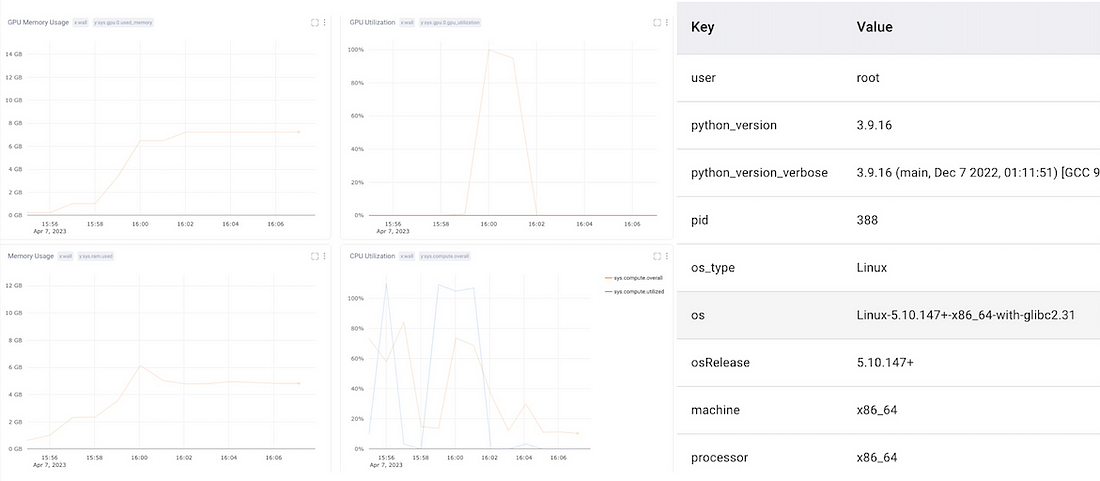
评估指标
我们的每个PyTorch检测模型都内置了相关的评估指标。Comet与PyTorch集成,因此这些预定义的指标将自动记录到实验中。这在比较同一模型的多次运行或具有相同评估指标的不同对象检测模型时这非常有用,但是我们选择的PyTorch模型并不都具有相同的内置指标。我们仍将使用这些自动记录的图表来获得模型性能的初步印象,但我们希望记录一些我们自己的指标,以便进行跨实验比较。
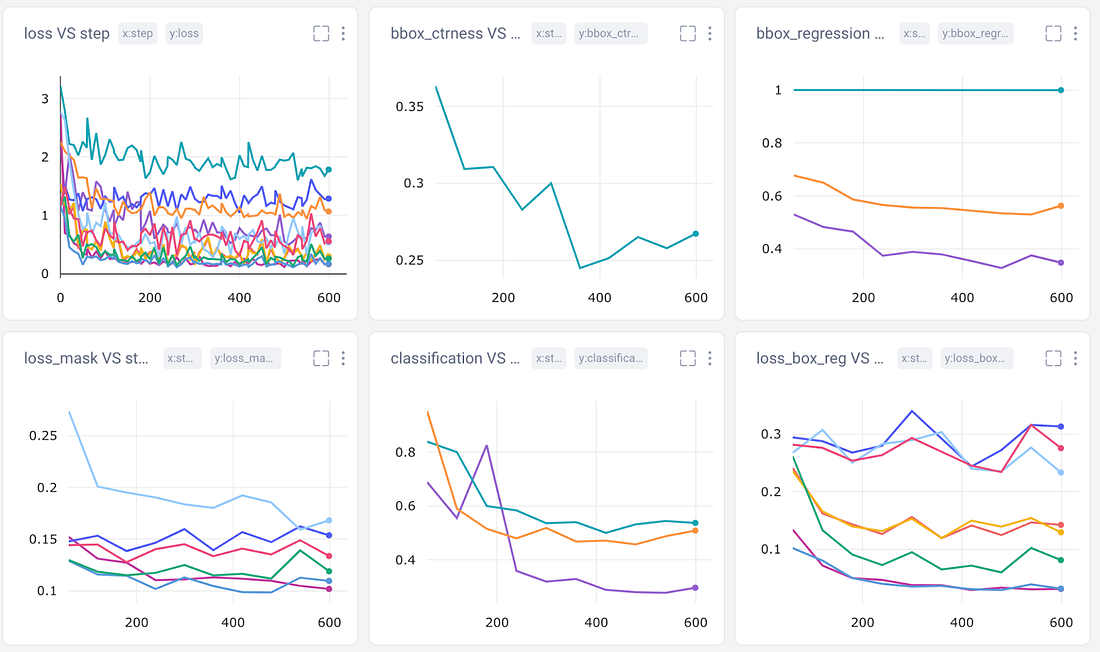
我们能手动记录任何我们想要的指标、资产、工件或图形。在本教程中,我们将跟踪:
1. 每个时期所有验证图像的平均精度(mAP)
2. 每个时期所有验证图像的平均召回率(mAR)
3. TorchMetric的12个指标用于描述每个图像的目标检测性能
4. TorchVision的相关代码文件(engine.py, transforms.py等)
5. 各种模型的图形定义
6. 验证数据集中的每个图像,以及我们的模型预测的边界框,以及它们相应的标签和置信度得分。
log_metric(name, value, step=None, epoch=None, include_context=True)
log_metrics(dict, prefix=None, step=None, epoch=None)
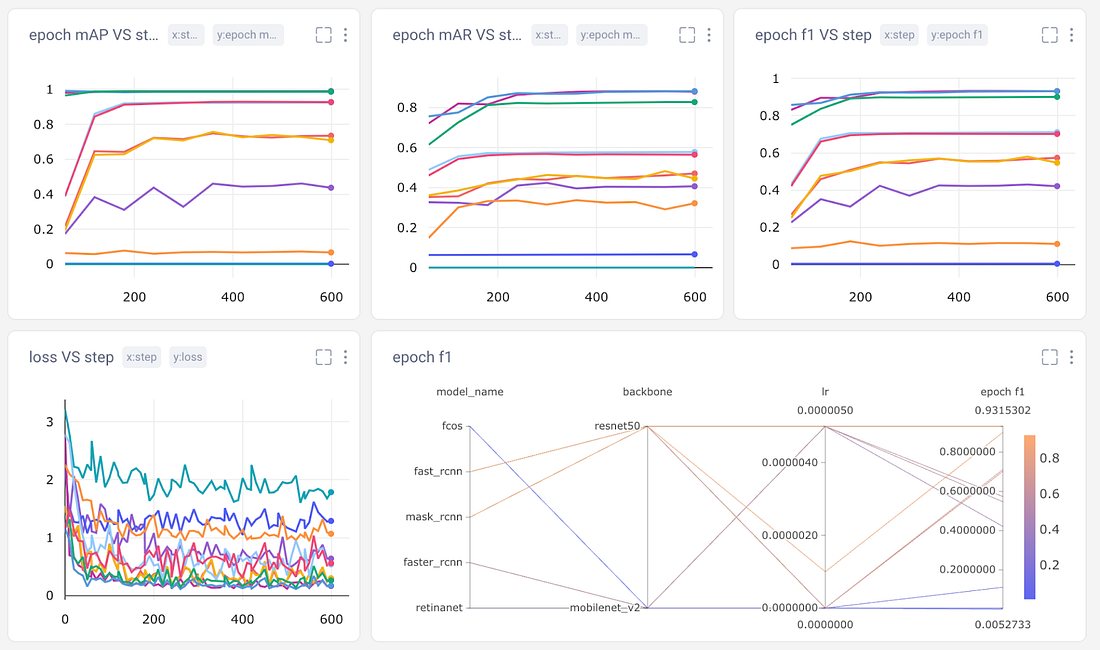
图形选项卡
对于图像数据集来说,了解模型的正确位置和错误位置可能特别困难。损失指标和其他数值并不总是能说明全部情况,而且很难可视化。因此,我们还将记录每个模型每个时期的每个验证图像及其预测的边界框。翻阅模型的预测也有助于了解我们的模型是如何随着时间的推移而改进的。

要将图像记录到Comet,我们只需使用log_image方法:
experiment.log_image(image, name, annotations, metadata)
或者,我们也可以将注释传递给metadata参数:
experiment.log_image(…, metadata = { "annotations": annotations })在任何情况下,图像注释都应该是JSON格式,边界框应该是COCO格式。边界框既可以作为字典传递(如下所示),也可以作为列表的列表传递。请注意,应该为每个边界框创建一个新实例,并且多边形点以格式[x1, y1, x2, y2,…,xn, yn]传递。
[
{
"imageId": "7d045ad5a96b45f8b5e770d817ac429b",
"experimentKey": "someExperimentKey",
"metadata": {
"annotations": [
{
"name": "some name",
"data": [
{
"label": "person",
"score": 0.8004001479832858,
"boxes": [
{
"x": 0,
"y": 40,
"width": 40,
"height": 40
}
],
"points": [
[
230,
32,
30,
40,
50,
10,
23,
54,
94,
20
],
[
230,
32,
30,
40,
50,
10,
23,
54,
94,
20
]
]
}
]
}
]
}
}
]
项目级别视图
由于我们在本教程中比较对象检测模型,因此我们可以使用跟踪工具的最重要的方法之一是创建一个整体的项目级视图。Comet自动生成一个基本的模型性能面板,但是我们也能够针对特定用例自定义面板。
图像面板
图像面板允许我们可视化每次实验运行的不同模型的预测。使用步进滑块浏览每个模型的预测,或单击单个图像以进行更仔细的查看。
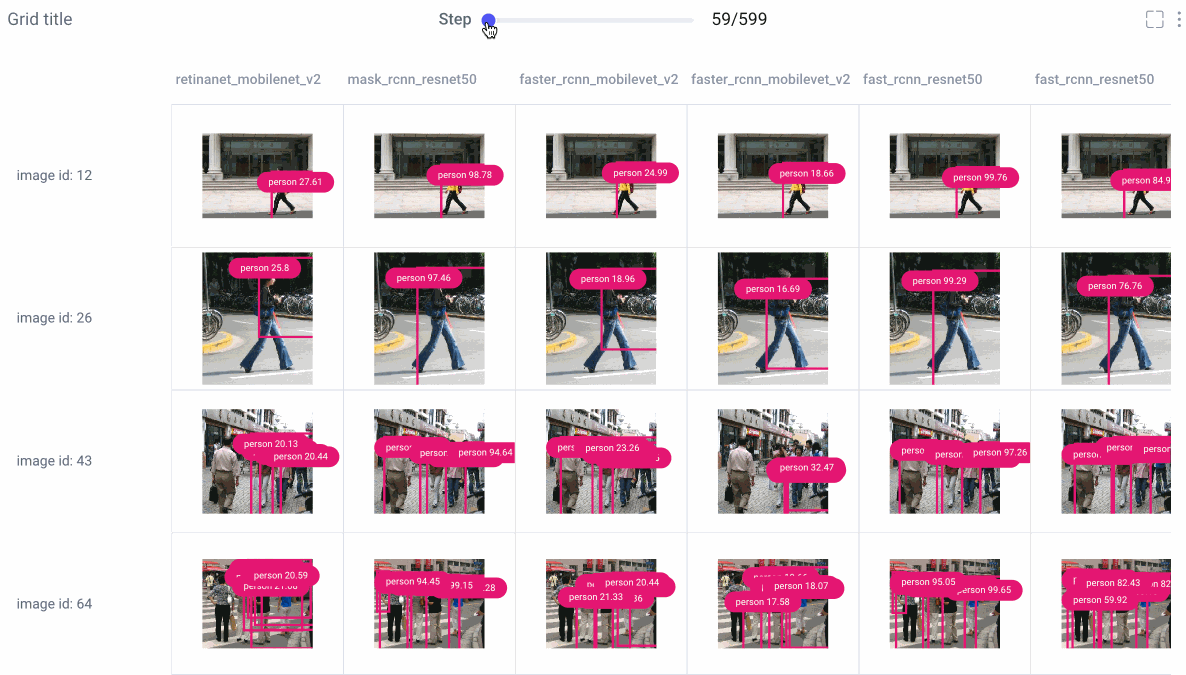
从那里,选择平滑图像或以灰度渲染图像,选择要检查的类标签,并使用滑动条设置置信度阈值。

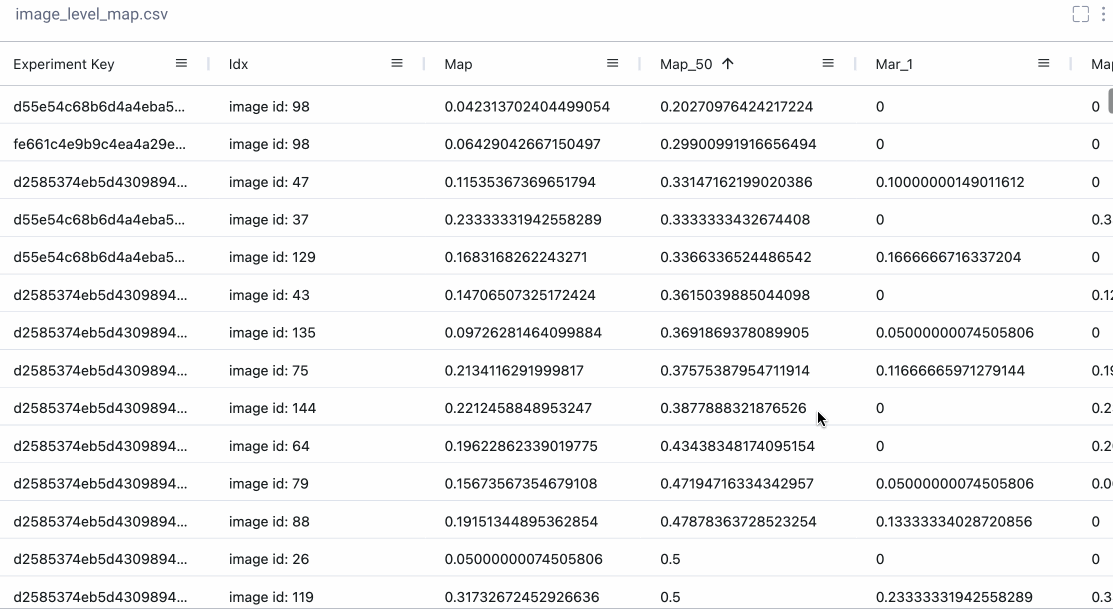
数据面板
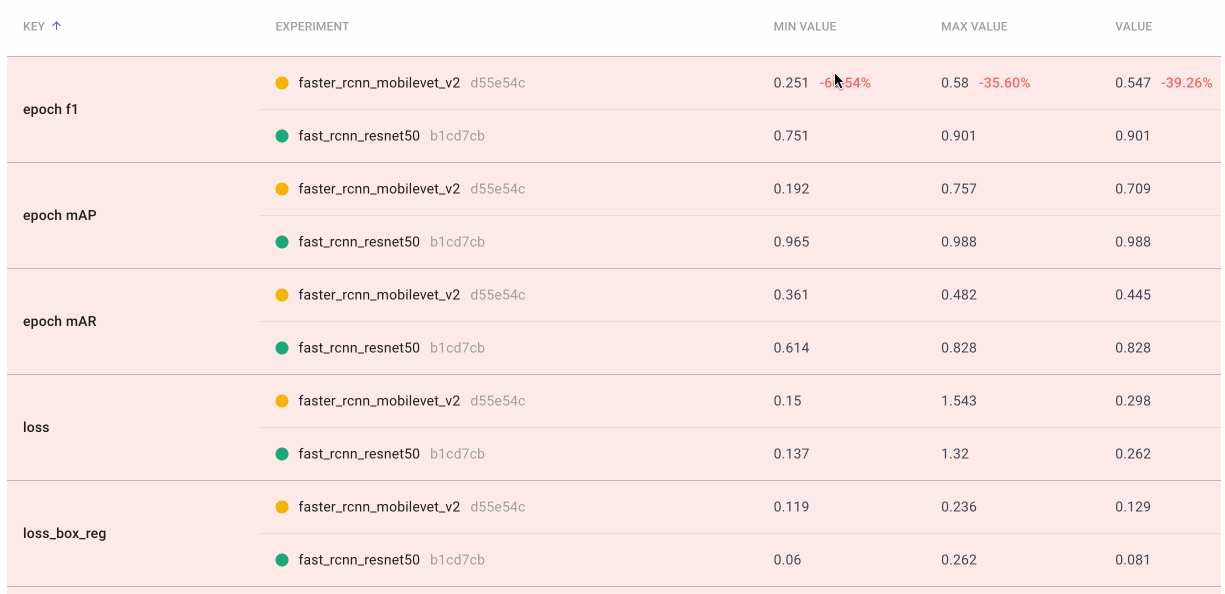
有时我们真的想深入研究数字。使用Comet的数据面板,我们可以将任何csv、 DataFrame或表记录到我们的项目中,并在UI中以交互方式探索它。我们记录了TorchMetric的mean_ap模块中的所有12个评估指标,如下所示。如果给定的指标与特定图像无关,则其值为-1(例如,如果图像没有预测任何“大”边界框,则该图像的mAP_large将为-1)mAP_large。我们可以对列重新排序、排序和过滤值。下面,我们比较最基本的mAP和mAR测量方法,然后对它们进行排序,看看精确度和召回率在哪些方面存在很大差异。或者,我们也可以检查我们在工具箱中作为附加工具记录的epoch f1-score。
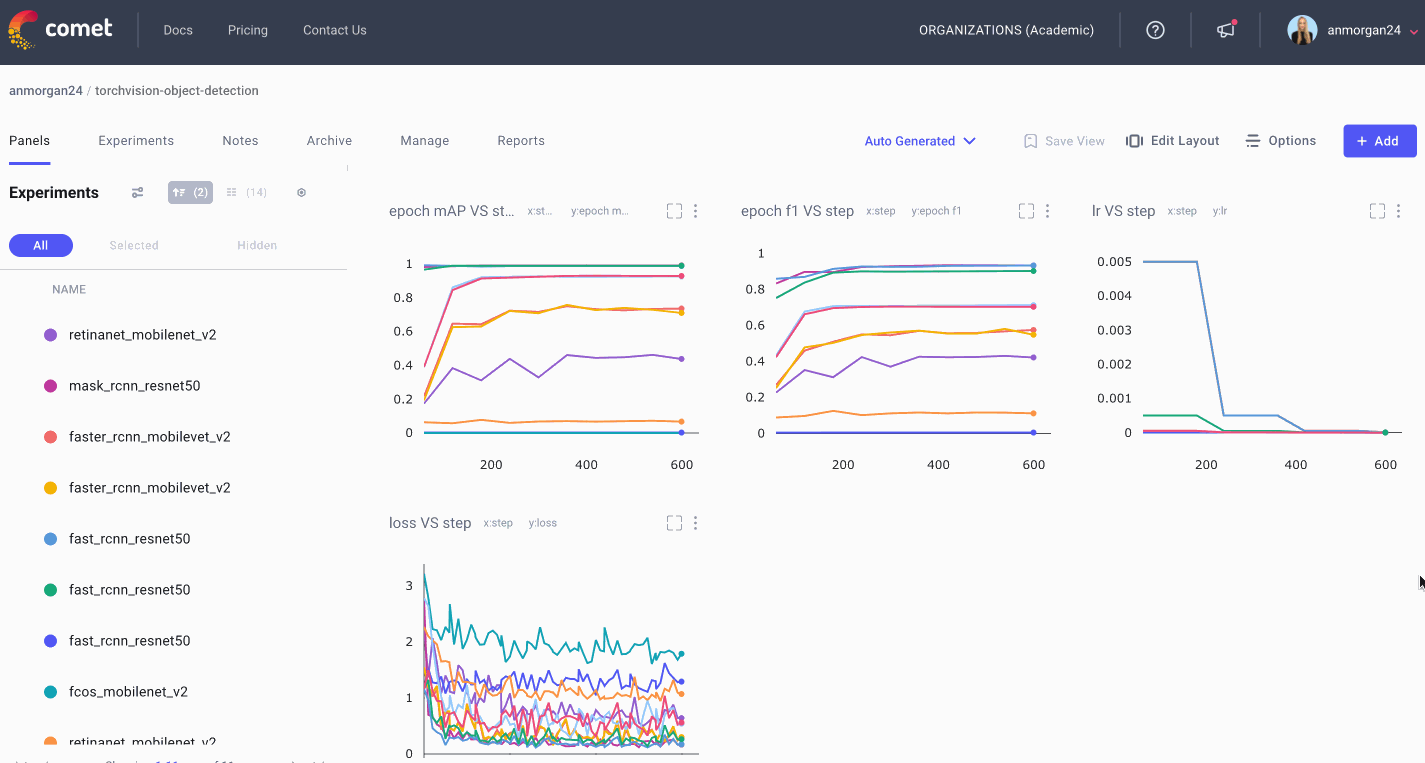
多个仪表板
现在我们已经构建了所有这些面板,我们需要一种方法来保持它们的组织性!为此,我们构建并保存多个仪表板,每个仪表板将用于不同的目的。我们将保留Comet为我们构建的自动生成仪表板,并将其余面板组织为另外四个仪表板。我们有一个项目概览仪表板,它为我们提供了一个非常基本的项目统计概况(使用的参数,运行的实验数量,以及实现的一些最佳指标)。我们将把我们的图像面板和数据面板到调试仪表板,我们将存储我们的情节和图表在指标仪表板。现在,我们可以轻松地浏览我们所有的面板,找到我们正在寻找的内容!
准确度与速度的权衡
在本文的开始,我们简要地探讨了机器学习的准确性和速度权衡。精度和准确度越高的模型往往会消耗更多的计算资源,而速度越快的模型往往精度越低。回到这个想法,我们将比较四种模型的总体速度和准确性,以便了解哪种模型最适合哪种场景。
我们创建了一个名为“精度-速度权衡”的最终仪表板,并绘制了四种不同模型的一些基本评估和系统指标:Mask RCNN,、Fast RCNN、RetinaNet和FCOS。请记住,这两个RCNN模型都是两阶段的目标检测模型,通常计算成本更高。RetinaNet和FCOS都是单级模型。
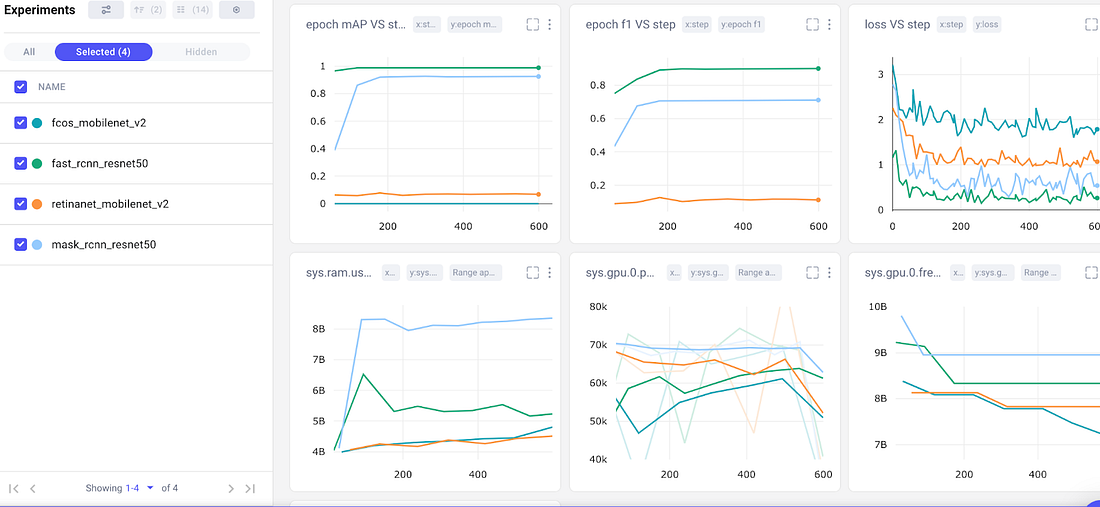
我们的四个基本模型的准确度与速度权衡仪表板
我们的两阶段目标检测模型(上面的绿色和浅蓝色)在平均精度、epoch f1 分数和损失方面都远远优于单阶段模型。然而,移到图表的最后一行,我们可以看到它们的计算成本也要高得多。Mask RCNN是所有模型中最慢的,这一点也不奇怪,因为它实际上是基于Fast RCNN的,但是产生了额外的输出。
对于通用的目标检测模型,我们可以得出结论,Fast RCNN在边界框预测方面表现最好。它具有最高的mAP和f1,最低的损耗,并且比Mask RCNN消耗的内存少得多。但是“最佳”模型是主观的,完全取决于你的用例!如果我们希望将我们的模型部署到移动设备上,那么Fast RCNN的内存要求可能会使其不符合我们的考虑。
结论
比较和记录对象检测模型可能是一项乏味而繁重的任务,但是当你拥有Comet这样的实验跟踪工具时,你可以将注意力集中在真正重要的地方。Comet是一个强大的工具,用于跟踪模型、数据集和指标,以保持实验的组织性、可重复性和可解释性。
来源:https://medium.com/towards-artificial-intelligence/compare-and-evaluate-object-detection-models-from-torchvision-474e69724e7d

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消