











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






可以分类胸透的谷歌新AI
2019年12月04日 由 TGS 发表
663298
0
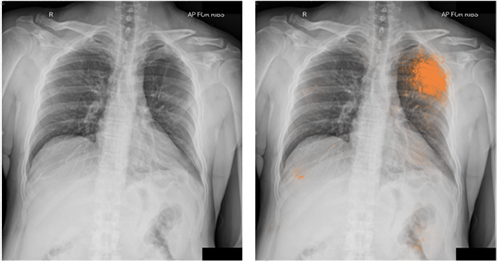 用机器学习算法分析胸部X光图像说起来容易,但实际上却是很难的一件事,因为训练这些算法所需的临床数据,大都是通过基于规则的自然语言处理或人工注释获得的,这两种方法往往具有潜在的不一致性和错误。此外,收集代表充分多样化的病例谱的数据集,以及仅使用图像建立有临床意义的标签,更是具有挑战性的任务。
用机器学习算法分析胸部X光图像说起来容易,但实际上却是很难的一件事,因为训练这些算法所需的临床数据,大都是通过基于规则的自然语言处理或人工注释获得的,这两种方法往往具有潜在的不一致性和错误。此外,收集代表充分多样化的病例谱的数据集,以及仅使用图像建立有临床意义的标签,更是具有挑战性的任务。为了在X光图像分类方面取得进展,谷歌的研究人员设计了人工智能模型来识别人类胸部X光的四个发现:气胸(肺萎陷)、结节、肿块、肺树状物填充。在《自然》杂志上发表的一篇论文中,谷歌研究小组称,在由人类专家进行的一项独立评估中,他们的系列模型展示出了“放射学家水平”的表现。
这项研究发表的前几个月,谷歌人工智能和美国西北医学院的科学家们创造了一个模型,能够比平均有8年经验的人类放射科医生更好地通过筛查试验检测肺癌。大约一年前,纽约大学使用谷歌的Inception v3机器学习模型来检测肺癌。这两个过往事实,简单诠释了谷歌这次成功背后所做的准备与努力。
新的人工智能模型利用了来自两个未经鉴定数据集的600000多幅图像,其中第一组是与阿波罗医院合作开发的,由多年来从多个地点收集的X射线组成。至于第二个语料库,它是美国国立卫生研究院发布的一组可公开获取的ChestX-ray14图像,该图像在历史上曾作为人工智能的资源,但在准确性方面存在缺陷。
 研究人员开发了一个基于文本的系统,利用与每一张X光片相关联的放射学报告提取标签,然后应用该系统为来自阿波罗医院数据集的560000多张图像提供标签。为了减少基于文本的标签提取引入的错误,并为多个Chest-Ray14图像提供相关标签,他们招募放射科医师来审查两个语料库上的37000幅图像。三名放射科医生审查了所有最终的调谐和测试集图像,并在线讨论解决了分歧。
研究人员开发了一个基于文本的系统,利用与每一张X光片相关联的放射学报告提取标签,然后应用该系统为来自阿波罗医院数据集的560000多张图像提供标签。为了减少基于文本的标签提取引入的错误,并为多个Chest-Ray14图像提供相关标签,他们招募放射科医师来审查两个语料库上的37000幅图像。三名放射科医生审查了所有最终的调谐和测试集图像,并在线讨论解决了分歧。最终的结果是,虽然模型总体上达到了专家级的准确度,但面对不同数据库,性能会有所不同。例如,对CHEST-Ray14图像的敏感度约为79%,但对于其他数据集上的相同图像却仅为52%。
研究小组希望,通过一个ChestX-ray14数据集判定标签数据库为更好的方法奠定基础。虽然这个新模型的稳定性还有待商榷,但已经可以应用到专项医疗活动中,这是人工智能医疗领域的又一小步。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
人工智能预测肺癌免疫治疗成功








广告


写评论取消
回复取消