











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






(PyTorch)50行代码实现对抗生成网络(GAN)
2019年09月12日 由 sunlei 发表
127395
0

2014年,蒙特利尔大学(University of Montreal)的伊恩•古德费洛(Ian Goodfellow)和他的同事发表了一篇令人震惊的论文,向全世界介绍了GANs,即生成式对抗网络。通过计算图和博弈论的创新结合,他们表明,如果有足够的建模能力,两个相互竞争的模型将能够通过普通的反向传播进行协同训练。
这些模型扮演两个截然不同的角色(字面意思是对抗性的)给定一些真实的数据集R, G是生成器,试图创建看起来像真实数据的假数据,而D是鉴别器,从真实数据集或G中获取数据并标记差异。古德费罗的比喻(也是一个很好的比喻)是G就像一组伪造者试图将真实的绘画与他们的作品相匹配,而D则是一组侦探试图分辨两者不同之处。(除了在这种情况下,伪造者G永远看不到原始数据——只有D的判断。他们就像盲人伪造者一样。)
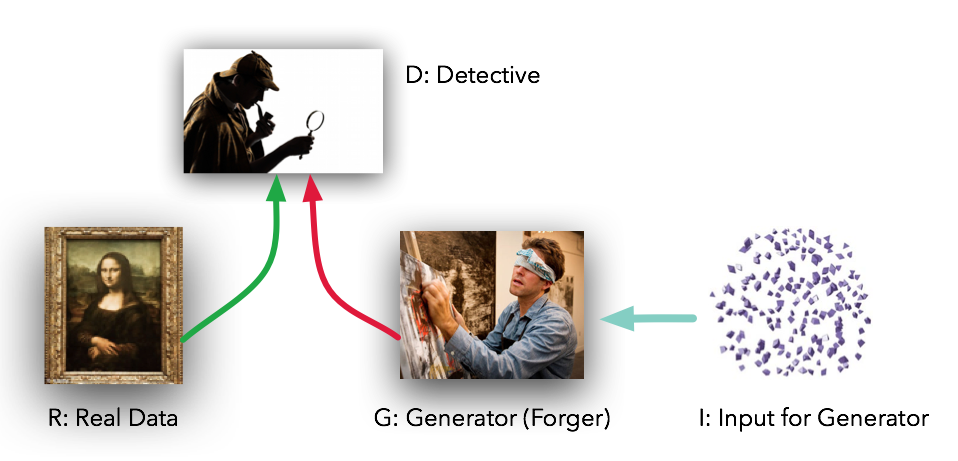
在理想的情况下,随着时间的推移,D和G都会变得更好,直到G本质上成为真品的“伪造大师”,而D则不知所措,“无法区分这两种分布”。
在实践中,古德费洛所展示的是,G将能够在原始数据集上执行一种无监督学习的形式,以一种(可能)低得多的维度的方式来表示数据。正如杨立昆(Yann LeCun)所言,无监督学习是真正人工智能的“蛋糕”。
这个强大的技术似乎需要大量的代码才能开始,对吗?不。使用PyTorch,我们实际上可以用50行代码创建一个非常简单的GAN。实际上只有5个组成部分需要考虑:
- R:原始的、真实的数据集
- I:作为熵源进入生成器的随机噪声
- G:试图复制/模拟原始数据集的生成器
- D:鉴别器,用来区分G和R的输出
- 在实际的“训练”循环中,我们教G欺骗D, D提防G。
1.)R:在我们的例子中,我们将从最简单的R-钟形曲线开始。此函数接受平均值和标准偏差,并返回一个函数,该函数使用这些参数从高斯函数中提供正确形状的样本数据。在我们的示例代码中,我们将使用平均值4.0和标准偏差1.25。

2.)I:生成器的输入也是随机的,但是为了让我们的工作更困难一点,我们用均匀分布而不是正态分布。这意味着我们的模型G不能简单地移动/缩放输入来复制R,而是必须以非线性的方式重塑数据。

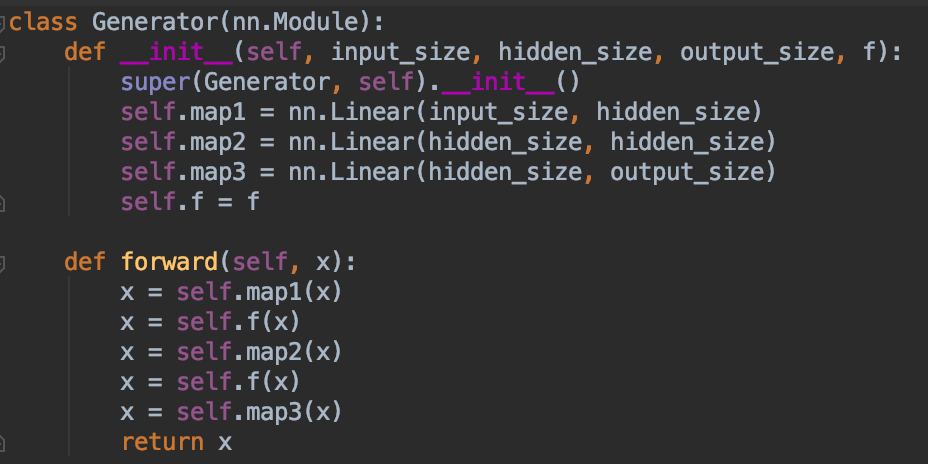
3.)G:生成器是一个标准的前馈图——两个隐层,三个线性映射。我们用的是双曲正切激活函数,因为我们太老派了。G将从I中得到均匀分布的数据样本以某种方式模拟R的正态分布样本而不需要看到R。
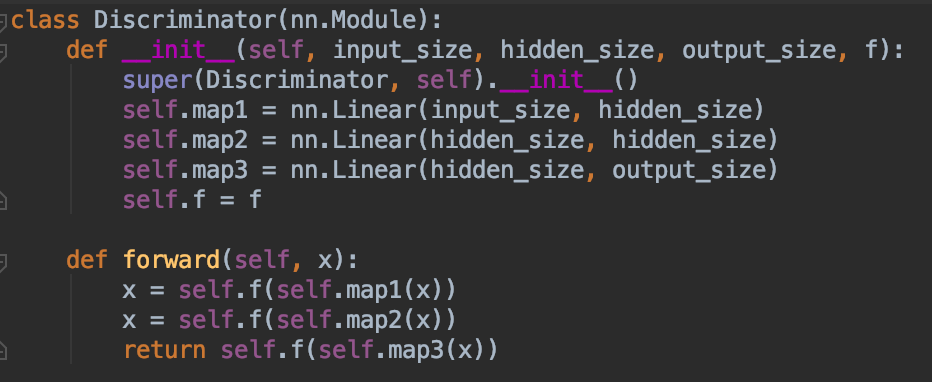
4.)D:鉴别器代码与G的生成器代码非常相似;一个包含两个隐层和三个线性映射的前馈图。这里的激活函数是一个S形,没什么特别的。它将从R或G中获取样本,并输出一个介于0和1之间的标量,解释为“假的”和“真实的”。换句话说,这是神经网络所能得到的最脆弱的东西。
5.)最后,训练循环在两种模式之间交替进行:第一种模式是真实数据的训练D,另一种模式是虚假数据的训练D,具有准确的标签(可以将其视为警察学院);然后用不准确的标签训练G去愚弄D(这更像是《十一罗汉》中的准备蒙太奇)。这是一场正义与邪恶之间的战争。
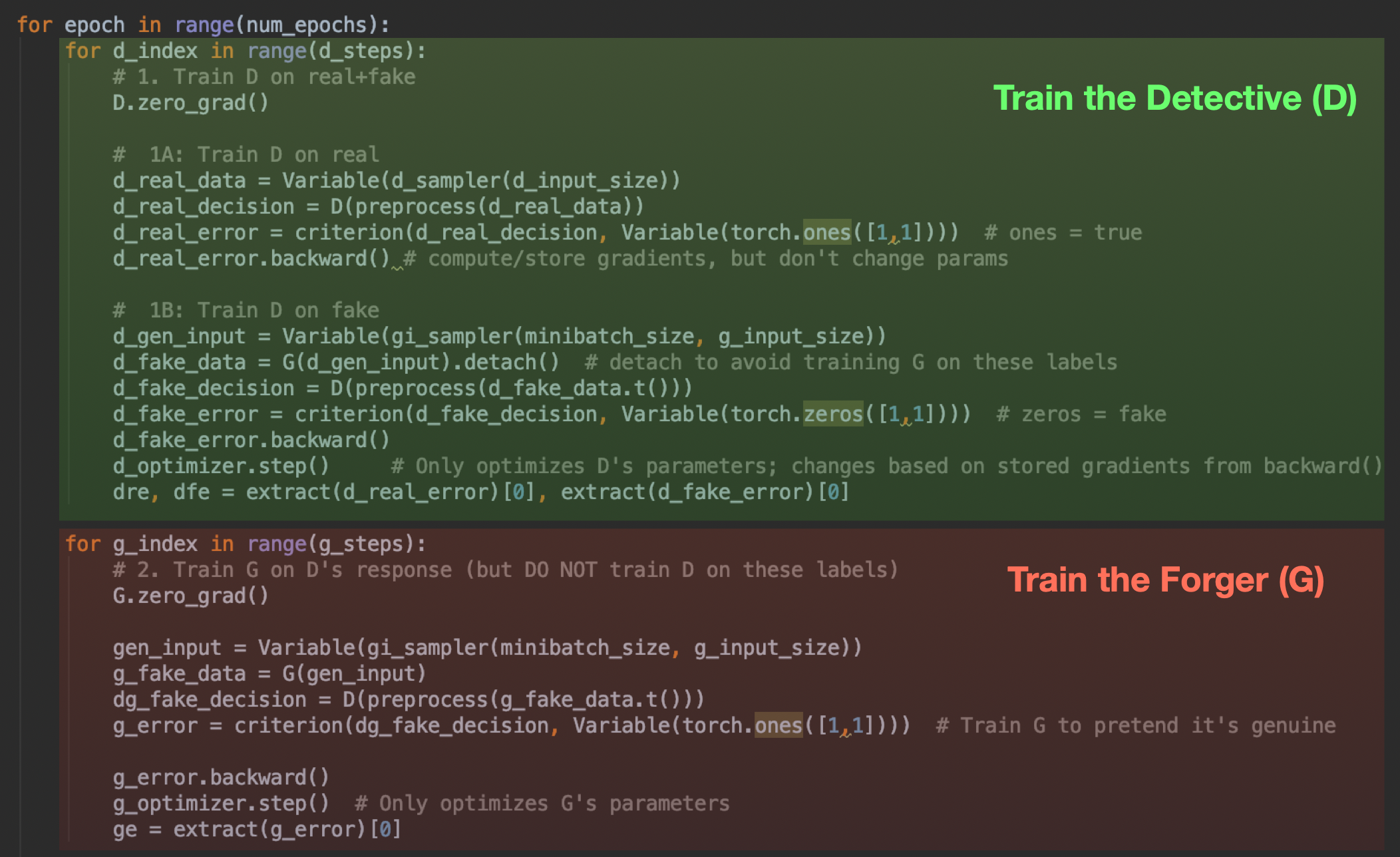
即使您以前没有见过PyTorch,您也可能知道发生了什么。在第一个(绿色)部分中,我们将这两种类型的数据都推入D,并对D的猜测与实际标签应用可微标准。这种推动是‘forward’”的一步;然后我们显式调用‘backward()’来计算梯度,然后使用梯度在d_optimizer step()调用中更新D的参数。G在这里使用,但没有经过训练。
然后在最后(红色)部分中,我们对G执行同样的操作——注意,我们还通过D运行G的输出(我们实际上是在给伪造者一个侦探来练习),但是在这一步我们没有优化或更改D。我们不想让D侦探知道错误的标签。因此,我们只调用g_optimizer.step()。
还有……就这些。还有一些其他的样板代码,但是特定于GAN的东西只是这5个组件,没有其他的。
在D和G之间跳了几千轮这种被禁止的舞蹈之后,我们得到了什么?鉴别器D很快就会变好(而G则慢慢上升),但一旦它达到一定的能力水平,G就会有一个值得尊敬的对手并开始改进,真正改善了。
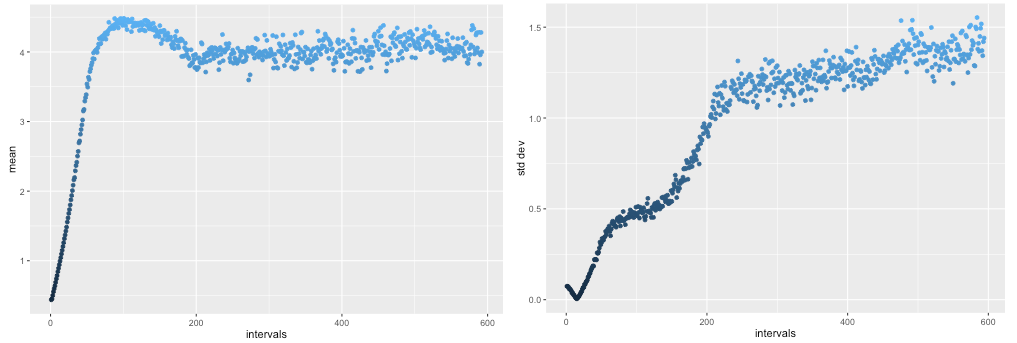
超过5000个训练回合,每回合训练D 20次,G 20次,G输出的平均值超过4.0,但随后回到一个相当稳定、正确的范围(左)。同样,标准偏差最初下降的方向是错误的,但随后上升到期望的1.25范围(右),与R匹配。
 好。所以基本的统计数据最终与R相匹配。那么更高的时刻呢?分布的形状看起来对吗?毕竟,均值为4.0,标准差为1.25的分布是均匀的,但这和R并不匹配。我们来看看G的最终分布:
好。所以基本的统计数据最终与R相匹配。那么更高的时刻呢?分布的形状看起来对吗?毕竟,均值为4.0,标准差为1.25的分布是均匀的,但这和R并不匹配。我们来看看G的最终分布: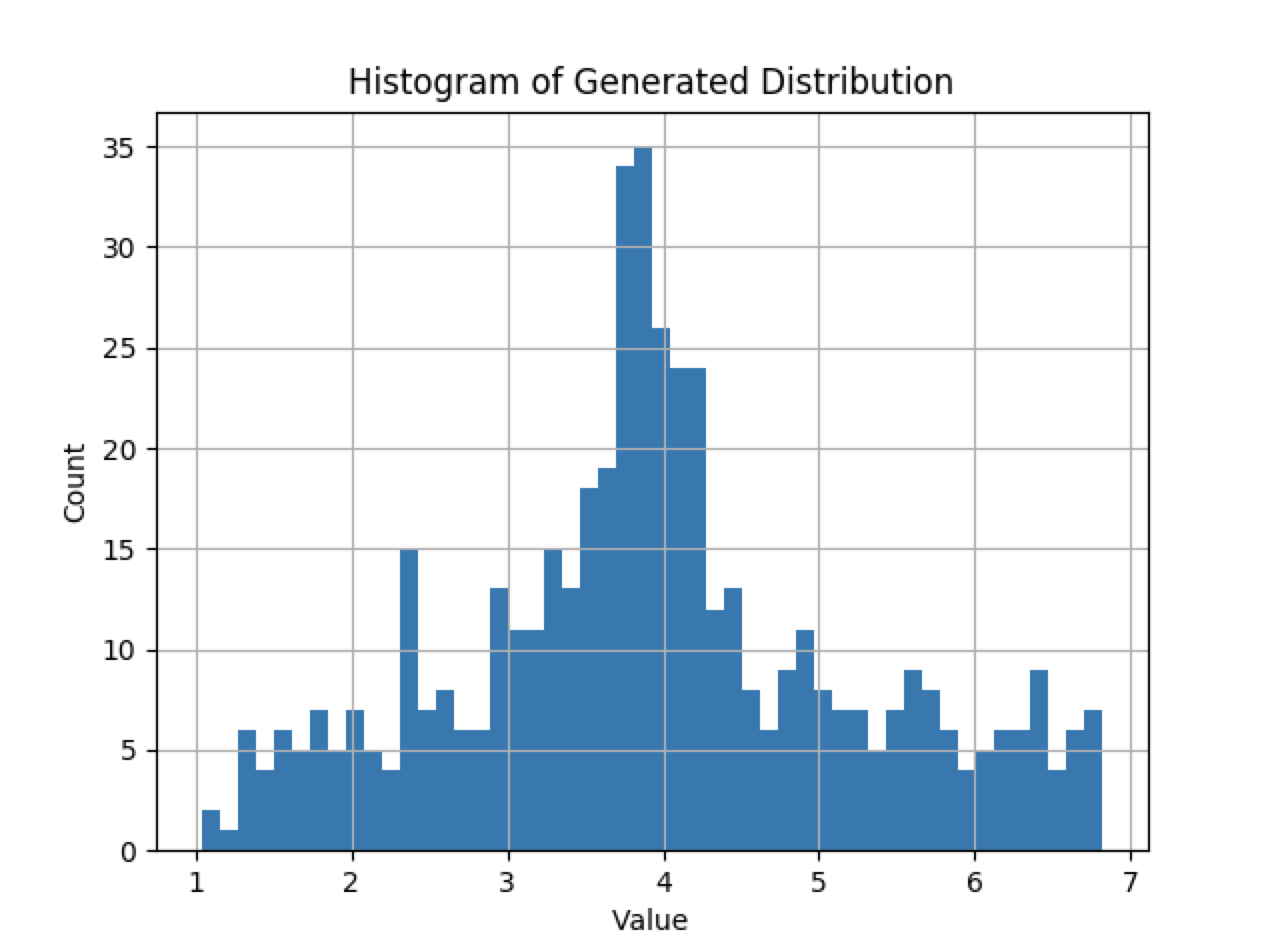
还不赖。右尾比左尾稍粗,但是歪斜和峰度,我们可以说,是原始高斯函数的再现。
G几乎完美地恢复了原始分布R,而D则蜷缩在角落里,喃喃自语,无法分辨事实与虚构。这正是我们想要的行为(参见Goodfellow中的图1)。少于50行代码。
现在,警告一句: GANs可能很挑剔和脆弱。当他们进入一种奇怪的状态时,他们通常不会不经过一点劝说就出来。运行我的示例代码10次(每次超过5000轮),显示了以下10个发行版:
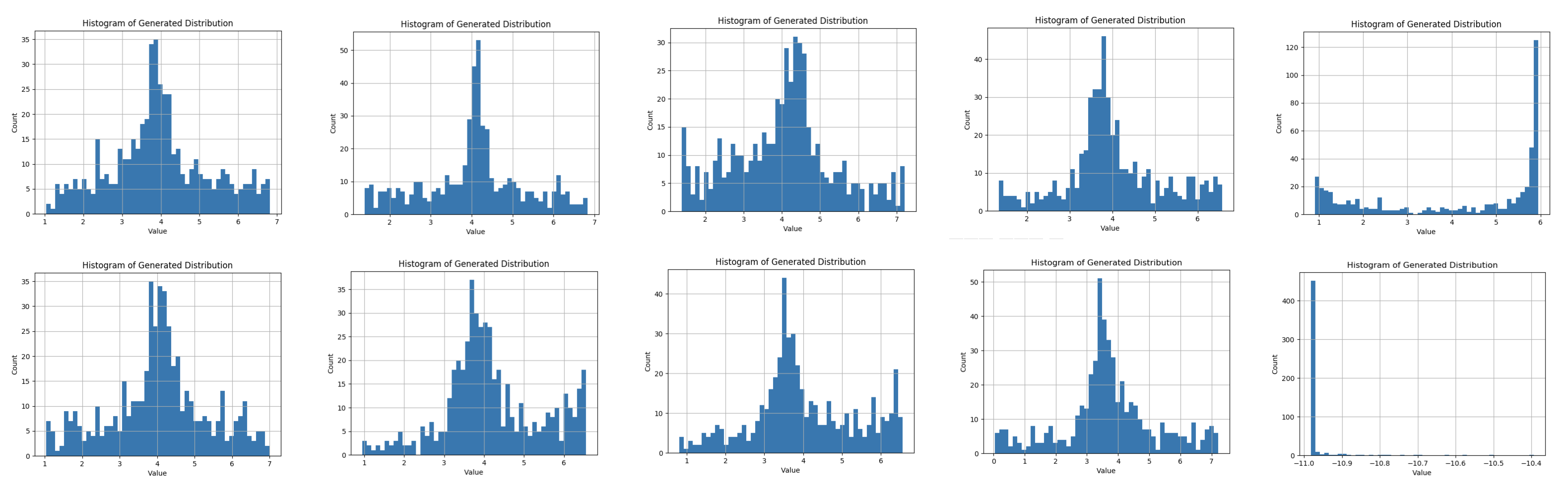
10次运行中有8次的最终分布非常好——类似于高斯分布,均值为4,标准差在正确的范围内。但是两次运行不是—在一次运行(运行5)中,有一个凹分布,平均值在6.0左右,在最后一次运行(运行10)中,在-11处有一个狭窄的峰值!当您开始在几乎所有的上下文中应用GANs时,您将会看到这种现象——GANs并不像一般的监督学习工作流那样稳定。但当它们发挥作用时,它们看起来事非常神奇的。
Goodfellow将继续发表关于GANs的许多其他论文,包括曾经的gem,其中描述了一些实际的改进,包括这里采用的小批量识别方法。这是他发布的一个2小时的教程。对于TensorFlow用户,这里有一篇来自Aylien在GANs上的类似文章。
好,说够了。点击这里去看看代码吧。
原文链接:https://medium.com/@devnag/generative-adversarial-networks-gans-in-50-lines-of-code-pytorch-e81b79659e3f

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消