











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






数据科学特征选择方法入门
2019年06月29日 由 sunlei 发表
804628
0
[caption id="attachment_41594" align="aligncenter" width="830"] Eugenio Mazzone在Unsplash上发布的照片[/caption]
Eugenio Mazzone在Unsplash上发布的照片[/caption]
让我们从定义特征开始。特征是数据集中的X变量,通常由列定义。现在很多数据集都有100多个特征,可以让数据分析师进行分类!正常情况下,这是一个荒谬的处理量,这就是特征选择方法派上用场的地方。它们允许您在不牺牲预测能力的情况下减少模型中包含的特征的数量。冗余或不相关的特征实际上会对模型性能产生负面影响,因此有必要(且有帮助)删除它们。想象一下,通过制造一架纸飞机来学习骑自行车。我怀疑你第一次骑车会走的远。
特征选择的主要好处是它减少了过度拟合。通过删除无关的数据,它允许模型只关注数据的重要特征,而不被无关的特征所困扰。删除无关信息的另一个好处是,它提高了模型预测的准确性。它还减少了得到模型所需的计算时间。最后,拥有较少的特征使您的模型更具可解释性和易于理解。总的来说,特征选择是能够以任何精度预测值的关键。
特征选择有三种类型:包装器方法(正向、向后和逐步选择)、过滤器方法(方差分析、皮尔逊相关、方差阈值)和嵌入方法(Lasso、Ridge、决策树)。我们将在下面的Python示例中对每种方法进行解释。
包装方法使用特定的特征子集计算模型,并评估每个特征的重要性。然后他们迭代并尝试不同的特征子集,直到达到最佳子集。该方法的两个缺点是计算时间长,数据特征多,在没有大量数据点的情况下容易对模型产生过拟合。最显著的特征选择包装器方法是前向选择、向后选择和逐步选择。
正向选择从零特征开始,然后,对于每个单独的特征,运行一个模型并确定与所执行的t-测试或f-测试相关联的p-值。然后选择p值最低的特征并将其添加到工作模型中。接下来,它接受所选择的第一个特征并运行添加了第二个特征的模型,并选择p值最低的第二个特征。然后它获取前面选择的两个特征并运行模型的第三个特征,以此类推,直到所有具有显著p值的特征都被添加到模型中。在迭代中尝试时没有显著p值的任何特征都将被排除在最终模型之外。

向后选择从数据集中包含的所有功能开始。然后,它运行一个模型,并为每个特征计算与模型的t检验或f检验相关联的p值。然后,将从模型中删除具有最大不重要p值的特征,然后重新开始该过程。这将一直持续到从模型中删除所有具有不重要p值的功能为止。

逐步选择是向前选择和向后选择的混合。它从零特征开始,并添加一个具有如上所述最低有效P值的特征。然后,它通过查找第二个具有最低有效P值的特征。在第三次迭代中,它将寻找具有最低有效P值的下一个功能,并且它还将删除以前添加的、现在具有不重要P值的任何功能。这允许最终模型具有包含所有重要功能的所有功能。

上述不同选择方法的好处是,如果您对数据和可能重要的特征没有直观的认识,那么它们将为您提供一个良好的起点。此外,它还能有效地从大量数据中选择具有显著特征的模型。但是,也有一些缺点,这些方法并不能运行所有特征的单个组合,因此它们可能不会得到绝对最佳的模型。此外,它还可以产生具有高多重共线性的模型(由于特征之间的关系而膨胀的β系数),这对准确预测不是很理想。
过滤方法使用错误率以外的度量来确定该特征是否有用。通过使用有用的描述性度量对特征进行排序,而不是调整模型(如包装方法中的模型),从而选择特征的子集。滤波方法的优点是计算时间非常短,不会使数据过拟合。然而,一个缺点是,它们对特征之间的任何交互或关联都视而不见。这需要单独考虑,具体解释如下。三种不同的过滤方法是方差分析、皮尔逊相关和方差阈值。
方差分析(ANOVA, Analysis of variance) 检验是一个特征治疗和治疗之间的变异。这些差异是这个特定过滤方法的重要指标,因为我们可以确定一个特征是否能够很好地解释因变量的变化。如果每个特定治疗的差异大于治疗之间的差异,那么这个特征就不能很好地解释因变量的变化。为了进行方差分析检验,计算每个特征的F统计量,其中分子处理(SST,通常与SStotal混淆)和分母处理之间的差异。然后根据无效假设(H0:所有治疗的平均值相等)和替代方案(Hα:至少有两种治疗方法不同)测试该试验统计数据。

皮尔逊相关系数是对-1和1之间两个特征相似性的度量。接近1或-1的值表示这两个特征具有很高的相关性,并且可能相关。要使用此相关系数创建具有缩减特征的模型,可以查看所有相关的heatmap(如下图所示),并选择与响应变量(y变量或预测变量)具有最高相关性的特征。高相关与低相关的临界值取决于每个数据集中相关系数的范围。高相关性的一般度量是0.7<相关性<1.0。这将允许使用所选功能的模型包含数据集中包含的大部分有价值的信息。

[caption id="attachment_41600" align="aligncenter" width="787"]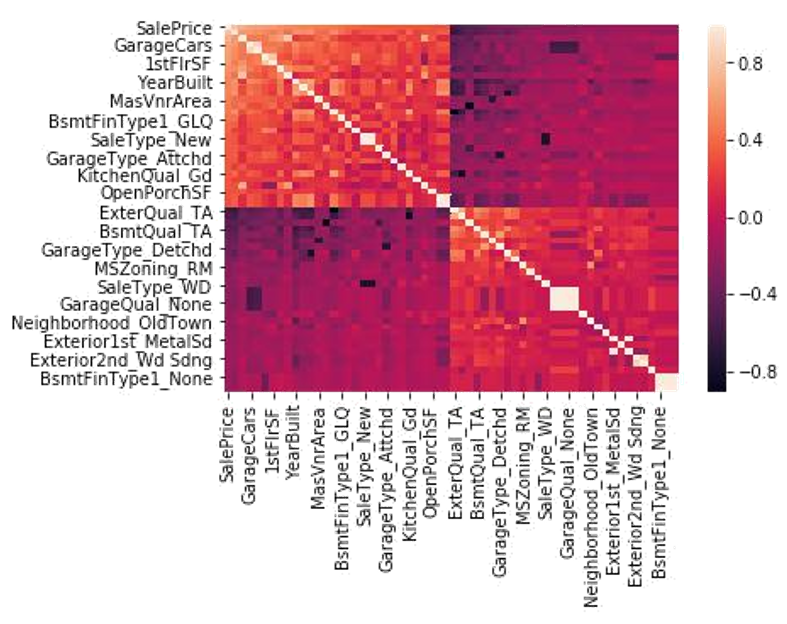 此数据集SalePrice的响应变量(顶部一行)显示了与其他变量的相关性。浅橙色和深紫色显示出很高的相关性。[/caption]
此数据集SalePrice的响应变量(顶部一行)显示了与其他变量的相关性。浅橙色和深紫色显示出很高的相关性。[/caption]
特征约简的另一种滤波方法是方差阈值法。特征的方差决定了它所包含的预测能力。方差越小,特征中包含的信息越少,它在预测响应变量时的值就越小。考虑到这一事实,方差阈值化是通过找出每个特征的方差,然后将所有特征降至某个方差阈值以下来实现的。如果只希望删除响应变量的每个实例具有相同值的特征,则此阈值可以为0。但是,要从数据集中删除更多的特征,可以将阈值设置为0.5、0.3、0.1或其他对方差分布有意义的值。

正如前面提到的,有时交互对于添加到模型中是有用的,特别是当您怀疑两个特征之间有关系,可以为模型提供有用的信息时。交互作用可以作为交互项添加到回归模型中,如B3X1X2所示。β系数(B3)修改了X1和X2的乘积,并测量了两个特征(Xs)组合模型的效果。要查看交互项是否重要,可以执行t检验或f检验,并查看该项的p值是否重要。一个重要的注意事项是,如果交互项很重要,那么两个低阶X项都必须保留在模型中,即使它们不重要。这是为了将X1和X2保留为两个独立变量,而不是一个新变量。

嵌入式方法将特征选择作为模型创建过程的一部分执行。这通常会导致前面解释的两种功能选择方法之间的折衷,因为选择是与模型调优过程一起完成的。Lasso和Ridge回归是两种最常见的特征选择方法,决策树也使用不同类型的特征选择创建模型。
有时,您可能希望在最终模型中保留所有特征,但您不希望模型过于关注任何一个系数。岭回归可以通过惩罚模型的贝塔系数过大来做到这一点。基本上,它缩小了与可能不像其他变量那么重要的变量之间的相关性。这将处理数据中可能存在的任何多重共线性(特征之间的关系,这些特征将会膨胀它们的beta)。平顺性回归是通过在回归的成本函数中添加一个惩罚项(也称为岭估计量或收缩估计量)来完成的。所有的beta并用一个必须调优的lambda(λ)项(通常是交叉验证:将相同的模型与lambda的不同值进行比较)对它们进行缩放。lambda是一个介于0和无穷大之间的值,但最好从0和1之间的值开始。lambda值越高,系数收缩的越多。当lambda等于0时,结果将是一个不带惩罚的正则普通最小二乘模型。
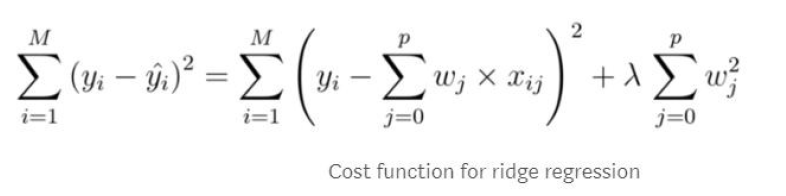

[caption id="attachment_41605" align="aligncenter" width="817"]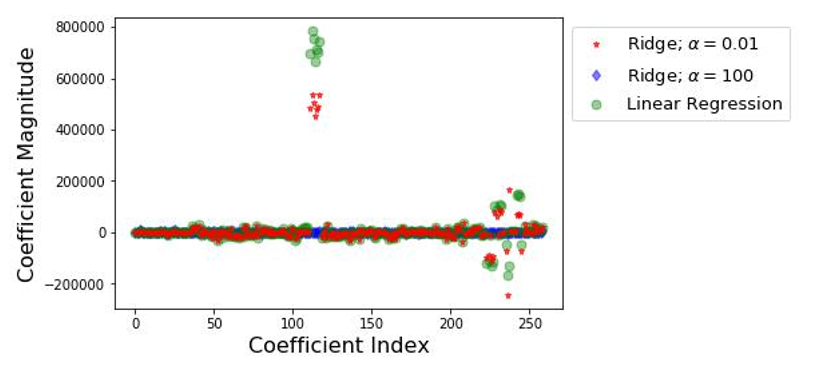 这说明了岭回归如何通过使线性回归中的一些大系数接近零来调整它们。[/caption]
这说明了岭回归如何通过使线性回归中的一些大系数接近零来调整它们。[/caption]
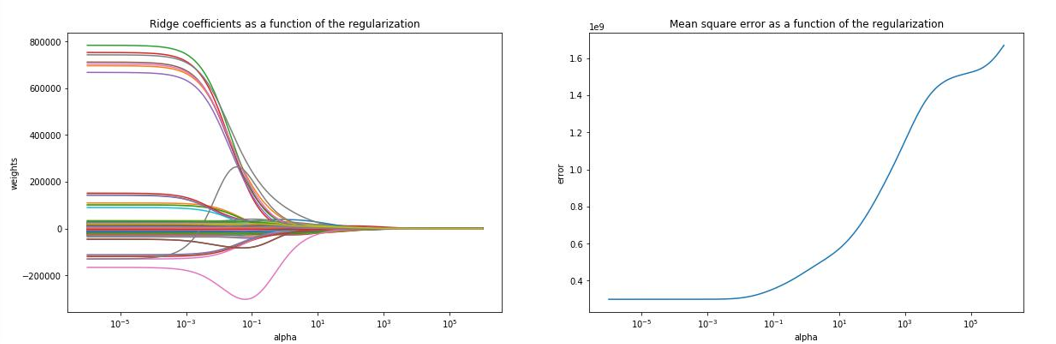 随着lambda(alpha)值的增加,系数被推向零,代价是MSE。
随着lambda(alpha)值的增加,系数被推向零,代价是MSE。
Lasso回归是另一种惩罚模型中β系数的方法,与岭回归非常相似。它还为模型的成本函数添加了一个惩罚项,必须对lambda值进行调整。与岭回归最重要的区别是,Lasso回归可以将beta系数强制为零,这将从模型中删除该特征。这就是为什么Lasso在某些时候更受欢迎,特别是当您希望降低模型复杂性时。模型的特征数量越少,复杂性越低。为了强制系数为零,加在成本函数上的惩罚项取β项的绝对值,而不是平方,当试图最小化成本时,它可以抵消函数的其余部分,导致β等于零。
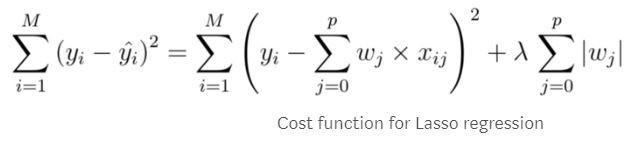

关于Ridge和Lasso回归的一个重要注意事项是,您的所有特征都必须标准化。Python和R中的许多函数都自动执行此操作,因为lambda必须对每个特征都应用相同的值。如果一个特征的值是千位的,而另一个特征的值是十进制的,则不允许这种情况发生,因此需要标准化。
另一种常用的特征选择建模方法是决策树,它可以是回归树,也可以是分类树,具体取决于响应变量是连续的还是离散的。该方法基于某些特征在树中创建拆分,以创建一个算法来查找正确的响应变量。树的构建方式使用嵌入方法中的包装方法。我们的意思是,在建立树模型时,函数内置了几种特征选择方法。在每次拆分时,用于创建树的函数会尝试对所有功能进行所有可能的拆分,并选择将数据拆分为最同质组的功能。简单地说,它选择最能预测树中每个点的响应变量是什么的特征。这是一个包装方法,因为它尝试所有可能的功能组合,然后选择最好的功能组合。
在预测响应变量时,最重要的功能是在树的根(开始)附近进行拆分,而更不相关的功能是在树的节点(结束)附近进行拆分。这样,决策树会惩罚那些对预测响应变量没有帮助的特征(嵌入方法)。生成树之后,可以选择返回并“修剪”一些不向模型提供任何附加信息的节点。这可以防止过拟合,通常通过与保持测试集的交叉验证来实现。

那么,既然你已经克服了所有的困难,你认为最重要的是什么呢?尽管一个数据集可能有数百到数千个特征,但这并不意味着它们都是重要或有用的。尤其是现在,我们生活在一个拥有难以想象的海量数据的世界里,试着关注那些重要的数据才是最重要的。还有很多(复杂的)方法可以执行特征选择(我们在这里没有提到的),但是无论如何这都是一个很好的开始!祝你好运,再接再厉!
特征:一个x变量,通常是数据集中的一列
特征选择:通过选择要使用的特征子集来优化模型
包装方法:尝试具有不同特征子集的模型并选择最佳组合
正向选择:逐个添加特征以达到最佳模型
逆向选择:逐个删除特征以达到最佳模型
逐步选择:正向和反向选择的混合,逐个添加和删除特征以达到最佳模型
过滤方法:通过一个非误差的度量来选择一个特征子集(一个特征固有且不依赖于模型的度量)
皮尔逊相关:两个变量之间线性相关的度量
方差阈值化:选择方差截止点以上的特征,以保留数据方差分析中的大部分信息:(方差分析)一组统计估计程序和模型,用于观察治疗(样本)方法的差异;可用于判断特征对模型的统计显著性。
交互项:当两个特征依赖于另一个特征的值时,量化它们之间的关系;减轻多重共线性并能进一步洞察数据多重共线性:当两个或多个独立变量彼此高度相关时发生。
嵌入式方法:在模型创建过程中选择和调整功能子集
岭回归:一种改进的最小二乘回归,通过对成本函数应用lambda项来惩罚具有膨胀β系数的特征。
拉索回归:类似于岭回归,但不同的是,添加到成本函数的lambda项可以强制β系数为零。
决策树:一种非参数模型,利用特征作为节点来分割样本,以正确地对观测进行分类。在一个随机森林模型中,特征重要性可以用平均下降基尼系数来计算。
交叉验证:一种迭代生成训练和测试数据集的方法,用于评估未来未知数据集上的模型性能。
Eugenio Mazzone在Unsplash上发布的照片[/caption]什么是特征选择?
让我们从定义特征开始。特征是数据集中的X变量,通常由列定义。现在很多数据集都有100多个特征,可以让数据分析师进行分类!正常情况下,这是一个荒谬的处理量,这就是特征选择方法派上用场的地方。它们允许您在不牺牲预测能力的情况下减少模型中包含的特征的数量。冗余或不相关的特征实际上会对模型性能产生负面影响,因此有必要(且有帮助)删除它们。想象一下,通过制造一架纸飞机来学习骑自行车。我怀疑你第一次骑车会走的远。
特征选择的好处
特征选择的主要好处是它减少了过度拟合。通过删除无关的数据,它允许模型只关注数据的重要特征,而不被无关的特征所困扰。删除无关信息的另一个好处是,它提高了模型预测的准确性。它还减少了得到模型所需的计算时间。最后,拥有较少的特征使您的模型更具可解释性和易于理解。总的来说,特征选择是能够以任何精度预测值的关键。
概述
特征选择有三种类型:包装器方法(正向、向后和逐步选择)、过滤器方法(方差分析、皮尔逊相关、方差阈值)和嵌入方法(Lasso、Ridge、决策树)。我们将在下面的Python示例中对每种方法进行解释。
包装器方法
包装方法使用特定的特征子集计算模型,并评估每个特征的重要性。然后他们迭代并尝试不同的特征子集,直到达到最佳子集。该方法的两个缺点是计算时间长,数据特征多,在没有大量数据点的情况下容易对模型产生过拟合。最显著的特征选择包装器方法是前向选择、向后选择和逐步选择。
正向选择从零特征开始,然后,对于每个单独的特征,运行一个模型并确定与所执行的t-测试或f-测试相关联的p-值。然后选择p值最低的特征并将其添加到工作模型中。接下来,它接受所选择的第一个特征并运行添加了第二个特征的模型,并选择p值最低的第二个特征。然后它获取前面选择的两个特征并运行模型的第三个特征,以此类推,直到所有具有显著p值的特征都被添加到模型中。在迭代中尝试时没有显著p值的任何特征都将被排除在最终模型之外。
向后选择从数据集中包含的所有功能开始。然后,它运行一个模型,并为每个特征计算与模型的t检验或f检验相关联的p值。然后,将从模型中删除具有最大不重要p值的特征,然后重新开始该过程。这将一直持续到从模型中删除所有具有不重要p值的功能为止。
逐步选择是向前选择和向后选择的混合。它从零特征开始,并添加一个具有如上所述最低有效P值的特征。然后,它通过查找第二个具有最低有效P值的特征。在第三次迭代中,它将寻找具有最低有效P值的下一个功能,并且它还将删除以前添加的、现在具有不重要P值的任何功能。这允许最终模型具有包含所有重要功能的所有功能。
上述不同选择方法的好处是,如果您对数据和可能重要的特征没有直观的认识,那么它们将为您提供一个良好的起点。此外,它还能有效地从大量数据中选择具有显著特征的模型。但是,也有一些缺点,这些方法并不能运行所有特征的单个组合,因此它们可能不会得到绝对最佳的模型。此外,它还可以产生具有高多重共线性的模型(由于特征之间的关系而膨胀的β系数),这对准确预测不是很理想。
过滤方法
过滤方法使用错误率以外的度量来确定该特征是否有用。通过使用有用的描述性度量对特征进行排序,而不是调整模型(如包装方法中的模型),从而选择特征的子集。滤波方法的优点是计算时间非常短,不会使数据过拟合。然而,一个缺点是,它们对特征之间的任何交互或关联都视而不见。这需要单独考虑,具体解释如下。三种不同的过滤方法是方差分析、皮尔逊相关和方差阈值。
方差分析(ANOVA, Analysis of variance) 检验是一个特征治疗和治疗之间的变异。这些差异是这个特定过滤方法的重要指标,因为我们可以确定一个特征是否能够很好地解释因变量的变化。如果每个特定治疗的差异大于治疗之间的差异,那么这个特征就不能很好地解释因变量的变化。为了进行方差分析检验,计算每个特征的F统计量,其中分子处理(SST,通常与SStotal混淆)和分母处理之间的差异。然后根据无效假设(H0:所有治疗的平均值相等)和替代方案(Hα:至少有两种治疗方法不同)测试该试验统计数据。
皮尔逊相关系数是对-1和1之间两个特征相似性的度量。接近1或-1的值表示这两个特征具有很高的相关性,并且可能相关。要使用此相关系数创建具有缩减特征的模型,可以查看所有相关的heatmap(如下图所示),并选择与响应变量(y变量或预测变量)具有最高相关性的特征。高相关与低相关的临界值取决于每个数据集中相关系数的范围。高相关性的一般度量是0.7<相关性<1.0。这将允许使用所选功能的模型包含数据集中包含的大部分有价值的信息。
[caption id="attachment_41600" align="aligncenter" width="787"]
此数据集SalePrice的响应变量(顶部一行)显示了与其他变量的相关性。浅橙色和深紫色显示出很高的相关性。[/caption]特征约简的另一种滤波方法是方差阈值法。特征的方差决定了它所包含的预测能力。方差越小,特征中包含的信息越少,它在预测响应变量时的值就越小。考虑到这一事实,方差阈值化是通过找出每个特征的方差,然后将所有特征降至某个方差阈值以下来实现的。如果只希望删除响应变量的每个实例具有相同值的特征,则此阈值可以为0。但是,要从数据集中删除更多的特征,可以将阈值设置为0.5、0.3、0.1或其他对方差分布有意义的值。
正如前面提到的,有时交互对于添加到模型中是有用的,特别是当您怀疑两个特征之间有关系,可以为模型提供有用的信息时。交互作用可以作为交互项添加到回归模型中,如B3X1X2所示。β系数(B3)修改了X1和X2的乘积,并测量了两个特征(Xs)组合模型的效果。要查看交互项是否重要,可以执行t检验或f检验,并查看该项的p值是否重要。一个重要的注意事项是,如果交互项很重要,那么两个低阶X项都必须保留在模型中,即使它们不重要。这是为了将X1和X2保留为两个独立变量,而不是一个新变量。
嵌入式方法
嵌入式方法将特征选择作为模型创建过程的一部分执行。这通常会导致前面解释的两种功能选择方法之间的折衷,因为选择是与模型调优过程一起完成的。Lasso和Ridge回归是两种最常见的特征选择方法,决策树也使用不同类型的特征选择创建模型。
有时,您可能希望在最终模型中保留所有特征,但您不希望模型过于关注任何一个系数。岭回归可以通过惩罚模型的贝塔系数过大来做到这一点。基本上,它缩小了与可能不像其他变量那么重要的变量之间的相关性。这将处理数据中可能存在的任何多重共线性(特征之间的关系,这些特征将会膨胀它们的beta)。平顺性回归是通过在回归的成本函数中添加一个惩罚项(也称为岭估计量或收缩估计量)来完成的。所有的beta并用一个必须调优的lambda(λ)项(通常是交叉验证:将相同的模型与lambda的不同值进行比较)对它们进行缩放。lambda是一个介于0和无穷大之间的值,但最好从0和1之间的值开始。lambda值越高,系数收缩的越多。当lambda等于0时,结果将是一个不带惩罚的正则普通最小二乘模型。
[caption id="attachment_41605" align="aligncenter" width="817"]
这说明了岭回归如何通过使线性回归中的一些大系数接近零来调整它们。[/caption] 随着lambda(alpha)值的增加,系数被推向零,代价是MSE。Lasso回归是另一种惩罚模型中β系数的方法,与岭回归非常相似。它还为模型的成本函数添加了一个惩罚项,必须对lambda值进行调整。与岭回归最重要的区别是,Lasso回归可以将beta系数强制为零,这将从模型中删除该特征。这就是为什么Lasso在某些时候更受欢迎,特别是当您希望降低模型复杂性时。模型的特征数量越少,复杂性越低。为了强制系数为零,加在成本函数上的惩罚项取β项的绝对值,而不是平方,当试图最小化成本时,它可以抵消函数的其余部分,导致β等于零。
关于Ridge和Lasso回归的一个重要注意事项是,您的所有特征都必须标准化。Python和R中的许多函数都自动执行此操作,因为lambda必须对每个特征都应用相同的值。如果一个特征的值是千位的,而另一个特征的值是十进制的,则不允许这种情况发生,因此需要标准化。
另一种常用的特征选择建模方法是决策树,它可以是回归树,也可以是分类树,具体取决于响应变量是连续的还是离散的。该方法基于某些特征在树中创建拆分,以创建一个算法来查找正确的响应变量。树的构建方式使用嵌入方法中的包装方法。我们的意思是,在建立树模型时,函数内置了几种特征选择方法。在每次拆分时,用于创建树的函数会尝试对所有功能进行所有可能的拆分,并选择将数据拆分为最同质组的功能。简单地说,它选择最能预测树中每个点的响应变量是什么的特征。这是一个包装方法,因为它尝试所有可能的功能组合,然后选择最好的功能组合。
在预测响应变量时,最重要的功能是在树的根(开始)附近进行拆分,而更不相关的功能是在树的节点(结束)附近进行拆分。这样,决策树会惩罚那些对预测响应变量没有帮助的特征(嵌入方法)。生成树之后,可以选择返回并“修剪”一些不向模型提供任何附加信息的节点。这可以防止过拟合,通常通过与保持测试集的交叉验证来实现。
总结
那么,既然你已经克服了所有的困难,你认为最重要的是什么呢?尽管一个数据集可能有数百到数千个特征,但这并不意味着它们都是重要或有用的。尤其是现在,我们生活在一个拥有难以想象的海量数据的世界里,试着关注那些重要的数据才是最重要的。还有很多(复杂的)方法可以执行特征选择(我们在这里没有提到的),但是无论如何这都是一个很好的开始!祝你好运,再接再厉!
关键词汇:
特征:一个x变量,通常是数据集中的一列
特征选择:通过选择要使用的特征子集来优化模型
包装方法:尝试具有不同特征子集的模型并选择最佳组合
正向选择:逐个添加特征以达到最佳模型
逆向选择:逐个删除特征以达到最佳模型
逐步选择:正向和反向选择的混合,逐个添加和删除特征以达到最佳模型
过滤方法:通过一个非误差的度量来选择一个特征子集(一个特征固有且不依赖于模型的度量)
皮尔逊相关:两个变量之间线性相关的度量
方差阈值化:选择方差截止点以上的特征,以保留数据方差分析中的大部分信息:(方差分析)一组统计估计程序和模型,用于观察治疗(样本)方法的差异;可用于判断特征对模型的统计显著性。
交互项:当两个特征依赖于另一个特征的值时,量化它们之间的关系;减轻多重共线性并能进一步洞察数据多重共线性:当两个或多个独立变量彼此高度相关时发生。
嵌入式方法:在模型创建过程中选择和调整功能子集
岭回归:一种改进的最小二乘回归,通过对成本函数应用lambda项来惩罚具有膨胀β系数的特征。
拉索回归:类似于岭回归,但不同的是,添加到成本函数的lambda项可以强制β系数为零。
决策树:一种非参数模型,利用特征作为节点来分割样本,以正确地对观测进行分类。在一个随机森林模型中,特征重要性可以用平均下降基尼系数来计算。
交叉验证:一种迭代生成训练和测试数据集的方法,用于评估未来未知数据集上的模型性能。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消