











在本文中,我将尝试介绍三件事:

请先登录您的atyun账户,方可使用该功能
审核通过后即可使用此功能,请耐心等待~






自学如何使用Python和Keras构建你自己专属的AlphaZero系统
2018年01月29日 由 yining 发表
368770
0
近日,Applied Data Science的联合创始人David Foster发表了一份详细的教程,意在教你搭建一套属于自己的AlphaZero系统。以下是教程的完整内容。
1.为什么AlphaZero是人工智能向前迈出的一大步。
2.如何构建一个AlphaZero方法论来玩“四子连珠(Connect4)”对弈游戏
3.如何调整代码以插入其他游戏
AlphaGo → AlphaGo Zero → AlphaZero
2016年3月,Deepmind的AlphaGo在一场由2亿多人观看的比赛中以4-1的战绩击败了18次世界围棋冠军李世石。一台机器已经学会了玩围棋这样的超人类战略,这一壮举以前被认为是不可能的,或者至少是在10年之后才能完成的。
AlphaGo与李世石的第三场比赛
这本身就是一项了不起的成就。然而,在2017年10月18日,DeepMind又迈出了一大步。
在没有人类知识的情况下,一篇“在没有人类知识的情况下掌握围棋(Mastering the Game of Go without Human Knowledge)”的论文揭示了一种新的算法——AlphaGo Zero以100-0的成绩击败了AlphaGo。令人难以置信的是,它是通过独自学习,开始“tabula rasa”(空白状态)的学习,并逐渐找到能够打败前身的自我战略。
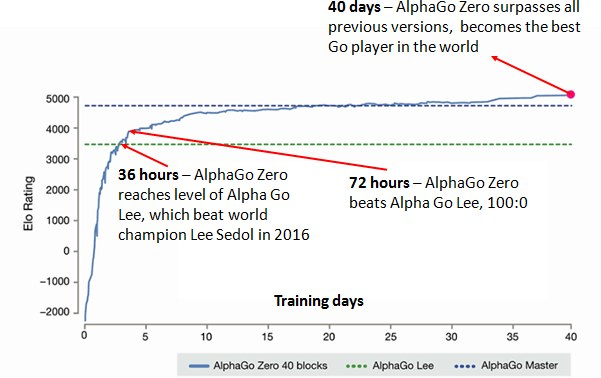
仅仅48天之后,在2017年12月5日,DeepMind发布了另一篇“精通国际象棋和日本象棋的自我对弈,通过一种通用的强化学习算法(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm)”论文,该论文展示了AlphaGo Zero如何能够在国际象棋和日本象棋的比赛中分别击败超强象棋引擎StockFish和Elmo。整个学习过程,从第一次看比赛,到成为世界上最好的电脑程序,只花了不到24小时。
这样,AlphaZero就诞生了——它是一种通用的算法,能快速地获得一些东西,而不需要任何人类专家策略的先验知识。关于这一成就,有两件令人惊异的事情:
1.AlphaZero需要零专业知识的人作为输入
这一点是不可能被夸大的。这意味着,AlphaGo Zero的根本方法可以应用于任何拥有完美信息的博弈中(博弈状态在任何时候都是完全已知的),因为除了游戏规则之外,不需要任何专业技能。
这就是在最初的AlphaGo Zero论文发表48天之后,DeepMind才有可能发布国际象棋和日本象棋的论文。从字面上来说,需要改变的是输入文件,它描述了博弈的机制,并调整了与神经网络和蒙特卡洛树搜索相关的超参数。
2.这个算法非常“优雅”
在可能的未来场景中,考虑到可能的下棋路径,同时考虑其他人最可能对你的行为作出反应并继续探索未知的情况。
在到达一个不熟悉的状态后,评估你对这个位置的看法。
当你已经思考了未来的可能性之后,采取你已经探索过的行动。
在博弈结束时,回过头来评估一下你对未来位置价值的误判,并据此更新你的理解。
这听起来是不是很像你学习下围棋的方式? 当你做了一个糟糕的下棋动作时,要么是因为你错误地判断了结果位置的未来值,要么是你错误地判断了你的对手会采取某种行动的可能性,所以没有考虑去探索这种可能性。这正是AlphaZero被训练去学习的博弈性的两个方面。
如何构建你自己的AlphaZero
首先,请查看AlphaGo Zero的“作弊单”,以了解AlphaGo Zero是如何工作的。当我们查看代码的每个部分时,都需要引用这些内容。这里还有一篇很棒的文章,解释了AlphaZero如何更详细地工作。
- 作弊单(需翻墙):https://medium.com/applied-data-science/alphago-zero-explained-in-one-diagram-365f5abf67e0
- 文章地址:http://tim.hibal.org/blog/alpha-zero-how-and-why-it-works/
- 本文要引用的代码:https://github.com/AppliedDataSciencePartners/DeepReinforcementLearning
要启动学习过程,请在run.ipynb Jupyter notebook中运行前两个面板。一旦它建立起足够的博弈形势,神经网络就会开始训练。通过更多的自我对弈和训练,它将逐渐从任何位置预测博弈值和棋手的下一步动作,从而做出更好的决策。
现在,我们将更详细地了解代码,并展示一些结果,以证明人工智能随着时间的推移变得越来越强大。
注意:这是我自己对AlphaZero如何工作的理解,基于上面提到的论文中所提供的信息。
Connect4
我们的算法将学会玩的游戏是Connect4(四子连珠)。虽然不像围棋那样复杂,但仍然有4531,985,219,092种游戏位置。
Connect4
游戏规则是这样的:玩家轮流在任何一栏的顶部放置自己的颜色的棋子。谁最先在垂直、水平或对角线上都放置了同一种颜色,那么你就赢了。如果不是,游戏平局。
下面是组成代码库的关键文件的摘要:
GAME.PY
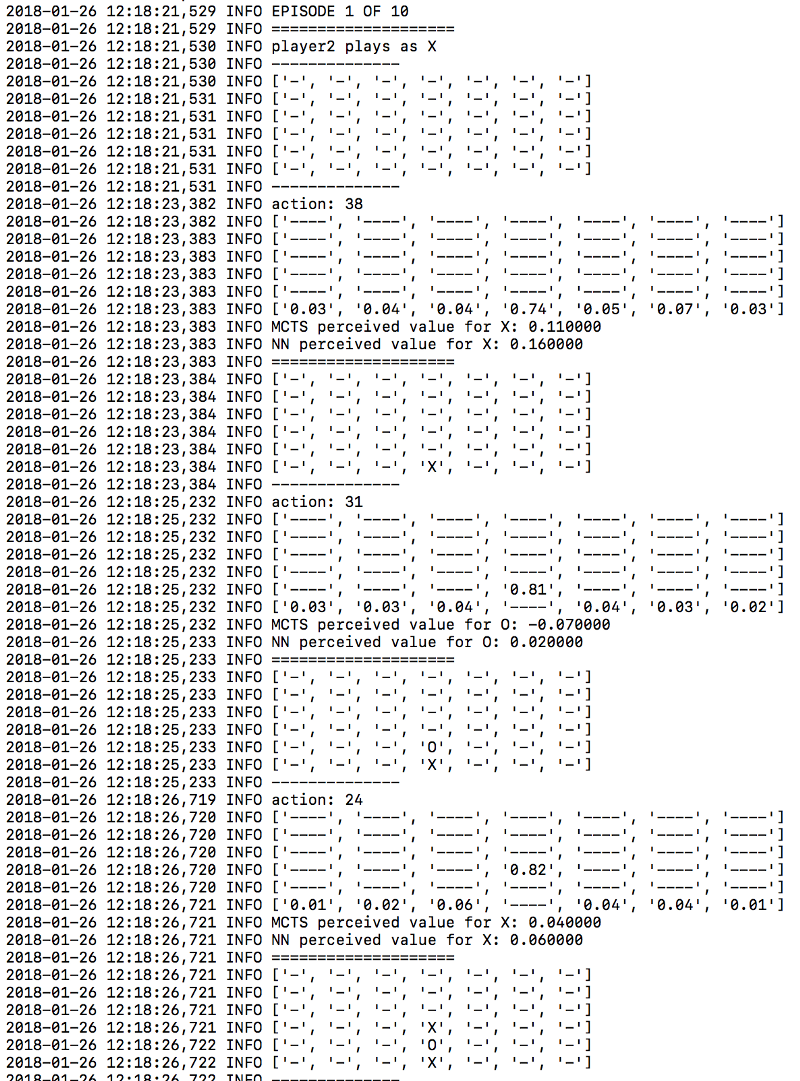
这个文件包含了Connect4的游戏规则。每个方块被分配了一个从0到41的数字,如下:
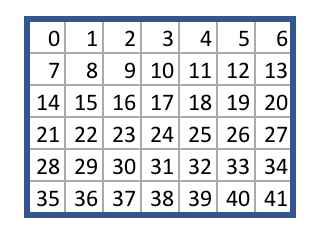
给定一个选择的动作,game.py文件给出了从一个博弈状态移动到另一个博弈状态的逻辑。例如,给定空棋盘和38号动作,takeAction方法返回到一个新的博弈状态,也就是底部一行的中心位置。
你可以将game.py文件替换为任何符合相同原则的API和算法的博弈文件,根据你所给出的规则,通过自我对弈学习策略。
run.ipynb
这个文件包含了启动学习过程的代码。它加载博弈规则,然后迭代算法的主循环,其中包含三个阶段:
1.自我对弈
2.再训练神经网络
3.评估神经网络
在这个循环中有两个agent,分别为best_player和current_player。
best_player包含了最好的神经网络,并被用来产生自我对弈的记忆。然后,current_player在这些记忆中重新训练它的神经网络,然后与best_player进行对抗。如果它赢了,best_player内部的神经网络被交换到current_player的神经网络中,而这个循环又将开始。
agent.py
这个文件包含了博弈中的一个参赛者的agent class。每个参赛者都有自己的神经网络和蒙特卡洛搜索树。
模拟方法运行蒙特卡洛树搜索过程。具体地说,agent将移动到树的叶节点(moveToLeaf),用它的神经网络对节点进行评估,然后通过树回填(backFill)节点的值。
act方法重复模拟多次,以了解从当前位置移动最有利的位置。然后,它将所选择的动作返回到游戏中,来执行这个动作。
Replay方法利用以前游戏中的记忆重新训练神经网络。
model.py
这个文件包含了Residual_CNN类,它定义了如何构建一个神经网络的实例。
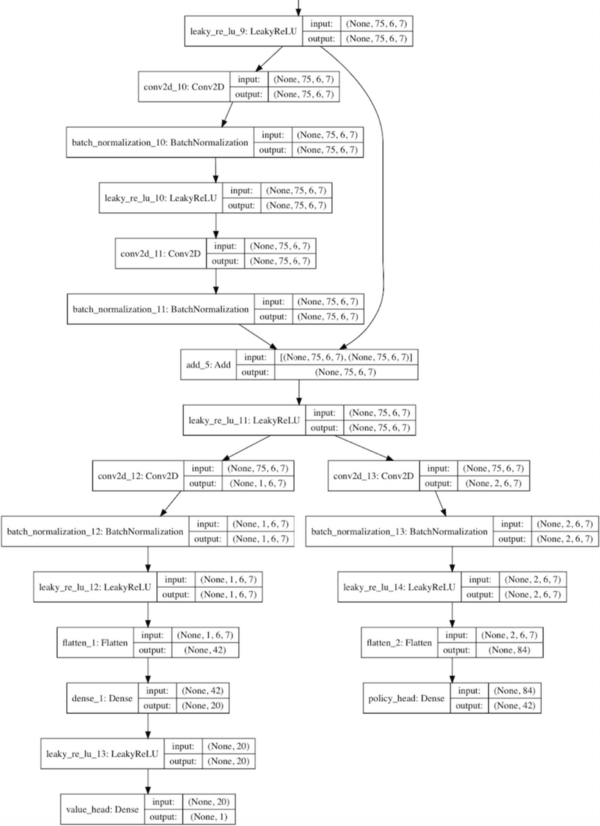
使用Keras的残差卷积网络的样本
它使用了AlphaGo Zero论文中的一个压缩版的神经网络体系结构,也就是一个卷积层,然后是许多残差层,然后分解为价值和策略两个分支。
可以在配置文件中指定卷积过滤的深度和数量。
Keras库是用来构建网络的,它的后端是Tensorflow。
要在神经网络中查看单个卷积过滤和密集连接的层,请在run.ipynb notebook中运行以下内容:
current_player.model.viewLayers()
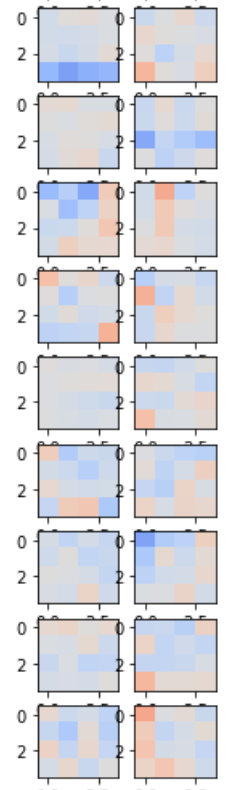 神经网络的卷积过滤
神经网络的卷积过滤
MCTS.py
它包含节点、边缘和MCTS类,构成了一个蒙特卡洛搜索树。
MCTS类包含前面提到的moveToLeaf和backFill方法,并且边缘类的实例存储每个可能的移动的统计信息。
config.py
这是你设置影响算法的关键参数的地方。

调整这些变量将影响算法的运行时间、神经网络的准确性和整体的成功。上面的参数产生了一个高质量的Connect4玩家,但是要花很长时间才能完成。为了加快算法的速度,请尝试以下参数。

funcs.py
包含playMatches和playMatchesBetweenVersions函数两个agent之间的对弈。如果要对你的创建进行操作,请运行以下代码(它也在run.ipynb notebook中):
from game import Game
from funcs import playMatchesBetweenVersions
import loggers as lg
env = Game()
playMatchesBetweenVersions(
env
, 1 # the run version number where the computer player is located
, -1 # the version number of the first player (-1 for human)
, 12 # the version number of the second player (-1 for human)
, 10 # how many games to play
, lg.logger_tourney # where to log the game to
, 0 # which player to go first - 0 for random
)
initialise.py
当你运行该算法时,所有的模型和内存文件都保存在run文件夹中,在根目录中。
稍后要从这个检查点重新启动算法,将run文件夹转移到run_archive文件夹中,将一个运行编号(run number)附加到文件夹名称。然后,将运行编号、模型版本号和Memory版本号输入到initialise.py文件中,对应于run_archive文件夹中相关文件的位置。像往常一样运行这个算法,然后从这个检查点开始。
memory.py
Memory类的一个实例存储了以前博弈的记忆,这个算法用来训练current_player的神经网络。
loss.py
这个文件包含一个自定义的损失函数,它在传递到交叉熵损失函数之前,掩盖了非法移动的预测。
settings.py
run和run_archive文件夹的位置。
loggers.py
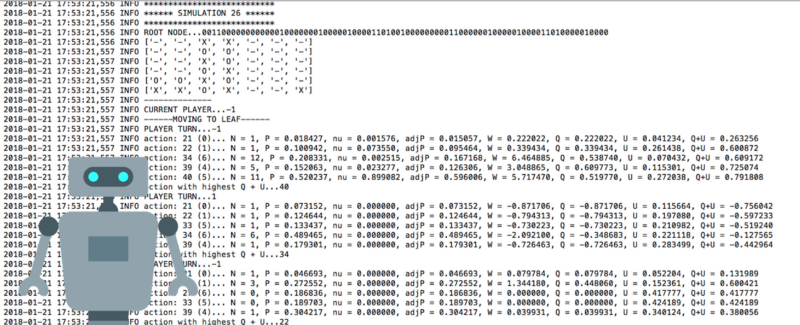
日志文件被保存到run文件夹中的log文件夹中。要打开日志记录,将logger_disabled变量的值设置为“False”。查看日志文件将帮助你了解算法的工作原理,并了解它的“思想”。
 从logger.mcts文件输出
从logger.mcts文件输出
你可以看到在评估期间每次(博弈)下法的概率。
结果
在几天内进行的训练会产生以下的关于小批量(mini-batch)迭代编号的损失图表:
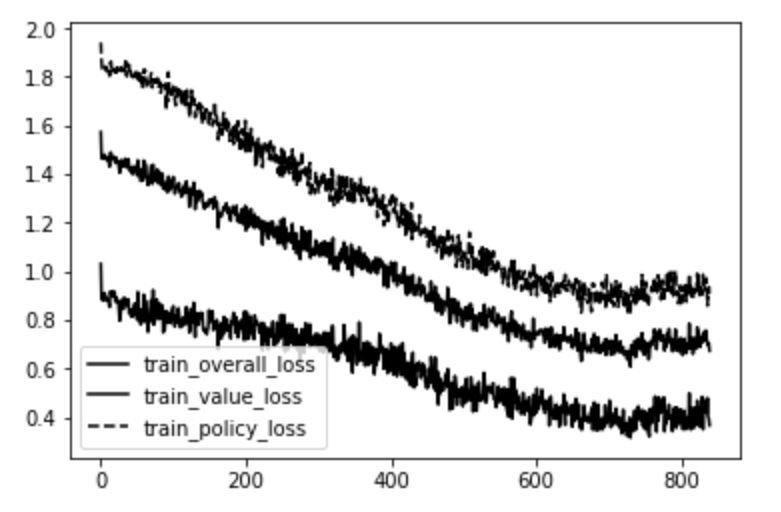
对小批量迭代数的损失
最上面的线是策略端的误差(MCTS的交叉熵移动概率与神经网络的输出相对应)。下面的线是价值端的误差(实际博弈值与神经网络值之间的均方差)。中间的线是两者的平均值。
很明显,神经网络在预测每个博弈状态的价值和可能的下一步动作方面做得越来越好。为了展示这一结果如何变得更加强大,我在17个参赛者之间进行了一场联赛,从首次迭代的神经网络到第49次迭代,每对搭档都交手了两次,两名玩家都有机会先上场。
以下是最终排名: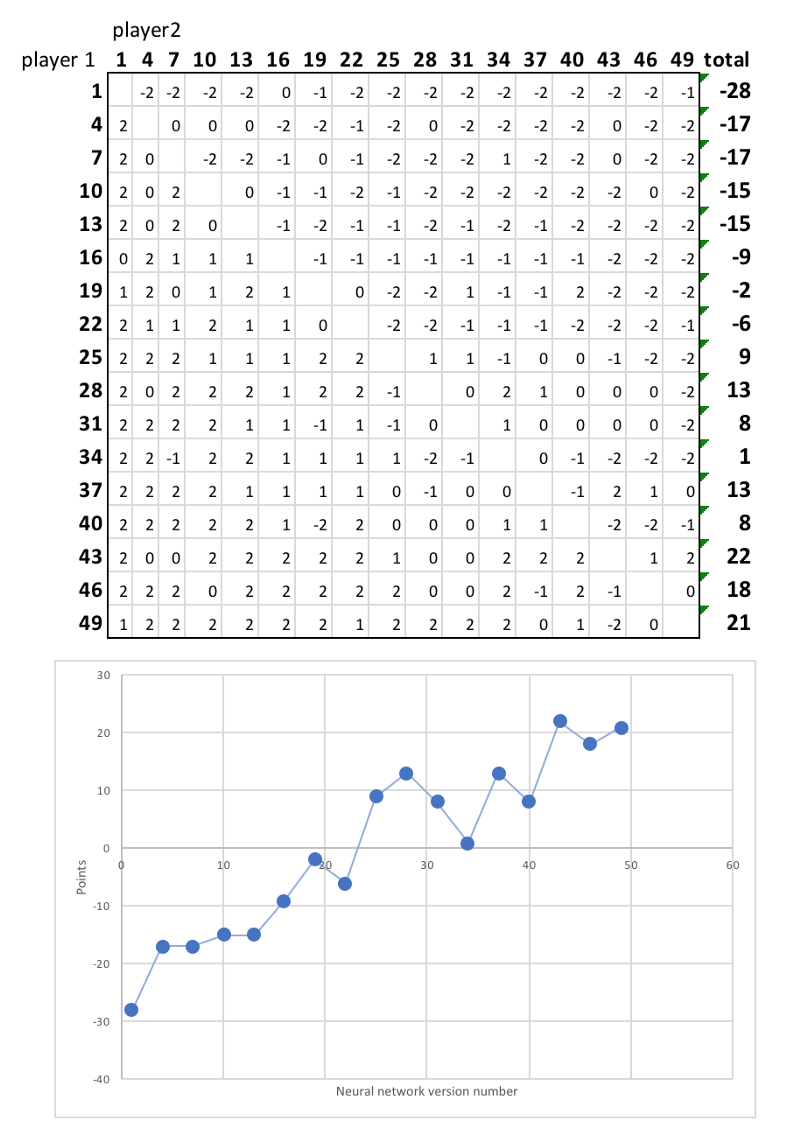
很明显,神经网络的后期版本比以前的版本要优越,赢得了大部分的比赛。同时,学习还没有达到饱和——随着训练时间的增加,参赛者将会继续变得更加厉害,学习越来越复杂的策略。
例如,神经网络一直偏爱的一个清晰的策略是尽早抢占中心栏。看看下面算法的首个版本和第30个版本之间的区别:
神经网络的首个版本:
神经网络的第30个版本:
这是一个很好的策略,因为很多下棋线路都需要中心栏——提前声明,确保你的对手不能利用这一点。这是由神经网络学会的,没有任何人类的输入。
学习一种不同的博弈游戏
在game.py文件中的games文件夹里,有一个叫做“Metasquares”的游戏。这个游戏是在网格中放置X和O标记,以尝试形成不同大小的方块。方块越大,玩家分数越高。
如果把Connect4的game.py文件替换成Metasquares的game.py文件,同样的算法就开始学习玩新的Metasquares游戏。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消