


















建立智能的解决方案:将TensorFlow用于声音分类
 对于人类的语音识别,目前有很多不同的项目和服务,像Pocketsphinx,谷歌的语音API,以及其他等等。这样的应用程序和服务能够以一种很不错的质量识别语音然后转换成文本,但没有一个能够对麦克风所捕捉到的不同声音做出判断。
对于人类的语音识别,目前有很多不同的项目和服务,像Pocketsphinx,谷歌的语音API,以及其他等等。这样的应用程序和服务能够以一种很不错的质量识别语音然后转换成文本,但没有一个能够对麦克风所捕捉到的不同声音做出判断。
对于这样的任务,我们决定调查并建立样本项目,这些项目将能够使用机器学习算法对不同的声音进行分类。本文描述了我们选择的工具,我们面临的挑战,我们如何训练TensorFlow模型,以及如何运行我们的开源项目。此外,我们还可以向DeviceHive、IoT平台提供识别结果,以便在第三方应用中使用云服务。
选择工具和分类模型
首先,我们需要选择一些软件来处理神经网络。我们找到的第一个合适的解决方案是使用PyAudioAnalysis。它是一个开放源码的Python库,提供了大量的音频分析程序,包括:特征提取、音频信号分类、监督和非监督分割和内容可视化。
- PyAudioAnalysis:https://github.com/tyiannak/pyAudioAnalysis
机器学习的主要问题是有一个好的训练数据集。有许多用于语音识别和音乐分类的数据集,但对于随机的声音分类来说并不是很多。经过一些研究,我们发现了Urbansound数据集。
- Urbansound数据集:https://serv.cusp.nyu.edu/projects/urbansounddataset/
在进行了一些测试之后,我们面临以下问题:
- pyAudioAnalysis不够灵活。它不需要很多种参数,其中一些参数是即时的。例如训练实验数量基于样本数量,你不能改变这个。
- 该数据集只有10个类,所有这些都是“urban”的。
我们找到的下一个解决方案是使用Google AudioSet。它是基于有标签的YouTube视频片段,可以以两种格式下载:
1.每个片段的CSV文件描述,YouTube视频ID,开始时间,结束时间,以及一个或多个标签。
2.提取的音频特征存储为TensorFlow记录文件。
这些特征与YouTube-8M模型兼容。这个解决方案还提供了TensorFlow VGGish模型作为特征提取器。它的特征涵盖了我们需求的很大一部分,因此是我们的最佳选择。
训练模式
接下来需要弄清楚YouTube-8M的界面是如何工作的。它的设计是为了配合视频,但幸运的是,它也可以与音频一起工作。这个库非常灵活,但是它有一个硬编码的样例类。所以我们对它进行了一些修改以将类的数量作为参数。
YouTube-8M可以处理两种类型的数据:聚合特征和框架特征。Google AudioSet可以提供我们之前提到的特征。通过进一步的研究,我们发现这些特征是框架格式的。然后我们需要选择接受训练的模型。
资源、时间和准确性
与CPU相比,GPU是机器学习的更合适的选择。在我们的实验中,我们有一台NVIDIA GTX 970 4GB的计算机。
在我们的案例中,训练时间并不重要。1-2小时的训练足以对选定的模型及其准确性做出初步的决定。当然,我们希望尽可能的准确。但是为了训练一个更复杂的模型(可能更准确),你需要更大的内存(RAM),如GPU的视频内存来适应它。
选择模型
在这里可以提供完整的有描述的YouTube-8M模型。因为我们的训练数据是框架格式的,所以必须使用框架级的模型。Google AudioSet为我们提供了一个数据集,分成三个部分:平衡的训练、不平衡的训练和评估。更多信息请点击下方地址。
改良版的YouTube-8M被用于训练和评估。
平衡的训练
训练命令:
python train.py –
train_data_pattern=/path_to_data/audioset_v1_embeddings/bal_train
/*.tfrecord –num_epochs=100 –
learning_rate_decay_examples=400000 –
feature_names=audio_embedding –feature_sizes=128 –frame_features
–batch_size=512 –num_classes=527 –train_dir=/path_to_logs –
model=ModelName
对于LstmModel,我们根据文档建议将基本学习速率更改为0.001。同样,我们将lstm_cells的默认值更改为256,因为我们没有足够的内存。
让我们看看训练结果:
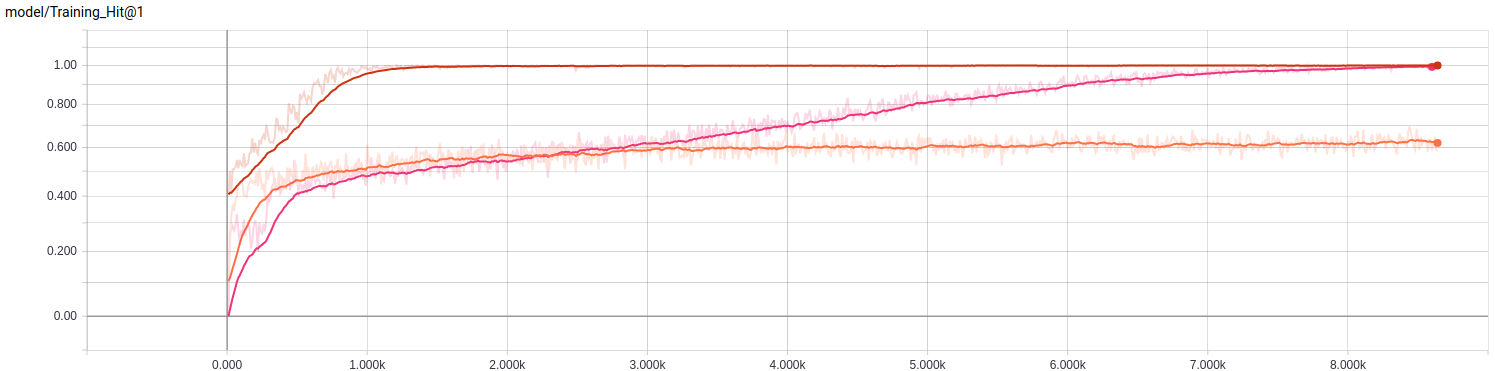
正如我们所看到的,我们在训练阶段取得了不错的成绩,但这并不意味着我们会在完整的评估中得到好的结果。
不平衡的训练
让我们试试不平衡的训练数据集。它有更多的样本,所以我们将把训练epoch的数量改为10(至少应该改成5,因为它花了很长时间来训练)。
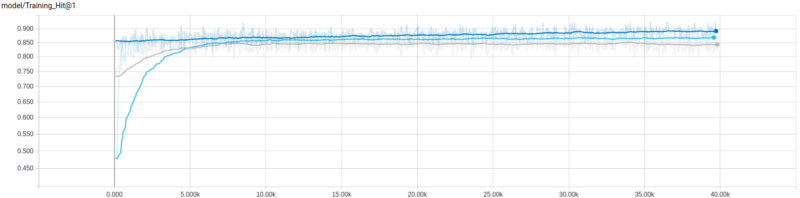
关于训练
你会有很多的参数,其中很多会影响到训练的过程。
例如:你可以调整学习速率和epoch的数量来改变训练过程,还有三种不同的函数可以用来进行损失计算和许多其他有用的变量,你可以调整和改变它们以改善结果。
使用带有音频采集设备的训练模型
现在我们有了一些经过训练的模型,是时候添加一些代码来与它们交互了。
我们需要从一个麦克风中获取音频数据。因此,我们将使用PyAudio。它提供了一个简单的接口,并且可以在大多数平台上工作。
声音准备
正如我们前面提到的,我们将使用TensorFlow VGGish模型作为特征提取器。
分类
最后,我们需要一个接口来将数据输入到神经网络并得到结果。我们将使用YouTube-8M接口作为一个例子,但将修改它移除序列化/反序列化的步骤。
安装
PyAudio使用libportaudio2和portaudio19-dev,因此你需要安装它们以使其工作。此外,需要一些Python库。你可以使用pip来安装它们。
pip install -r requirements.txt
你还需要下载并使用保存的模型将归档文件下载到项目根目录中。你可以在下面链接中找到它
运行
我们的项目提供了三个接口。
1.处理预先录制的音频文件
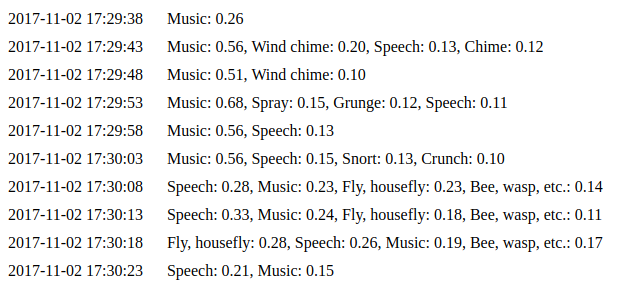
简单的运行python parse_file.py path_to_your_file.wav,然后在终端中你会看到类似于Speech: 0.75, Music: 0.12, Inside, large room or hall: 0.03这样的命令。
结果取决于输入文件。这些值是神经网络做出的预测。较高的值意味着属于该类的输入文件的几率更高。
2.从麦克风获取和处理数据
python capture.py启动了从麦克风中获取数据的过程。它将在每5-7秒(默认情况下)将数据提供给分类接口。你将在前面的示例中看到结果。
你可以使用–save_path=/path_to_samples_dir/来运行它,在这种情况下,所有获取的数据都将存储在wav文件所提供的目录中。如果你想使用相同的示例来尝试不同的模型,那么这个函数是很有用的。使用–help参数获取更多信息。
3.Web界面
python daemon.py实现了一个简单的web界面,默认情况下,它可以在http://127.0.0.1:8000中使用。我们使用与前一个示例相同的代码。你可以在events页面看到最近的十种预测。
- 地址:http://127.0.0.1:8000/events
物联网(IoT)服务集成
最后,最重要的是与物联网基础设施的整合。如果你运行上一节中提到的web界面,那么你可以在索引页面上找到DeviceHive客户端状态和配置。只要客户端连接,预测就会被发送到指定的设备作为通知。

结论
TensorFlow是一个非常灵活的工具,正如你所见,它可以帮助许多机器学习应用程序,如图像和声音识别。有了这样的解决方案和IoT平台,你就可以在一个非常广阔的领域内建立一个智能解决方案。
IoT平台这个解决方案可以安装在本地设备上(尽管它仍然可以部署在云服务的某个地方),以最小化流量和云计算费用,并自定义只提供通知,而不包括原始音频。请不要忘记这是一个开放源码项目,所以请随意使用它。









