











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伪标签(Pseudo-Labelling)介绍:一种半监督机器学习技术
2017年09月26日 由 yining 发表
172261
0
我们在解决监督机器学习的问题上取得了巨大的进步。这也意味着我们需要大量的数据来构建我们的图像分类器。但是,这并不是人类思维的学习方式。一个人的大脑不需要上百万个数据来进行训练,需要通过多次迭代来完成相同的图像来理解一个主题。它所需要的只是在基础模式上用几个指导点训练自己。显然,我们在当前的机器学习方法中缺少一些东西。我们能否可以建立一个系统,能够要求最低限度的监督,并且能够自己掌握大部分的任务。
本文将介绍一种称为伪标签(Pseudo-Labelling)的技术。我会给出一个直观的解释,说明伪标签是什么,然后提供一个实际的实现。
内容
- 什么是半监督学习?
- 不加标签的数据有何帮助?
- 介绍伪标签
- 实现半监督学习
- 采样率的依赖
- 半监督学习的应用
什么是半监督学习?
比方说,我们有一个简单的图像分类问题。训练数据由两个被标记的图像Eclipse(日食)和Non-eclipse(非日食)组成,如下所示。

我们需要从非日食图像中对日食的图像进行分类。但是,问题是我们需要在仅仅两张图片的训练集上建立我们的模型。
因此,为了应用任何监督学习算法,我们需要更多的数据来构建一个鲁棒性的模型。为了解决这个问题,我们找到了一个简单的解决方案,我们从网上下载一些图片来增加我们的训练数据。

但是,对于监督的方法,我们也需要这些图像的标签。因此,我们手动将每个图像分类为如下所示的类别。

在对这些数据进行监督的算法之后,我们的模型肯定会比在训练数据中包含两个图像的模型表现得更突出。但是这种方法只适用于解决较小目的的问题,因为对大型数据集的注释可能非常困难且昂贵。
因此,我们定义了一种不同类型的学习,即半监督学习,即使用标签数据(受监督的学习)和不加标签的数据(无监督的学习)。
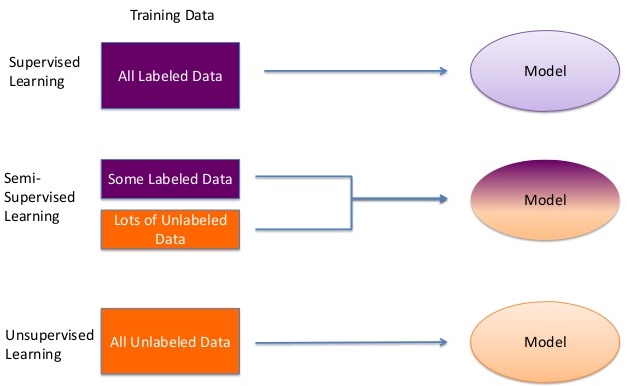
因此,让我们了解不加标签的数据如何有助于改进我们的模型。
不加标签的数据有何帮助?
考虑如下所示的情况:
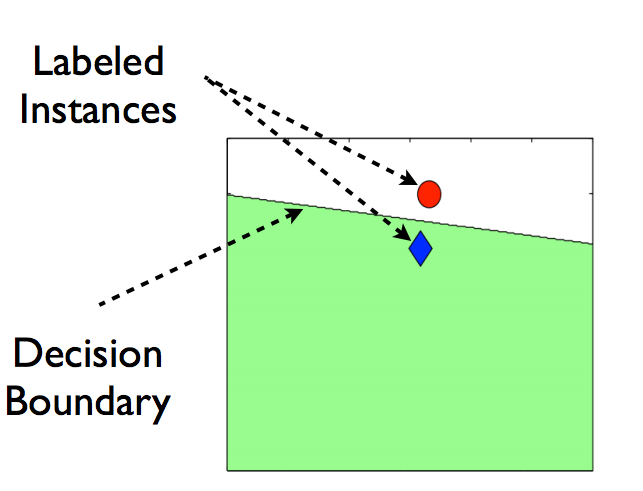
你只有两个属于两个不同类别的数据点,而所绘制的线是任何受监督模型的决策边界。现在,假设我们将一些不加标记的数据添加到这个数据中,如下图所示。
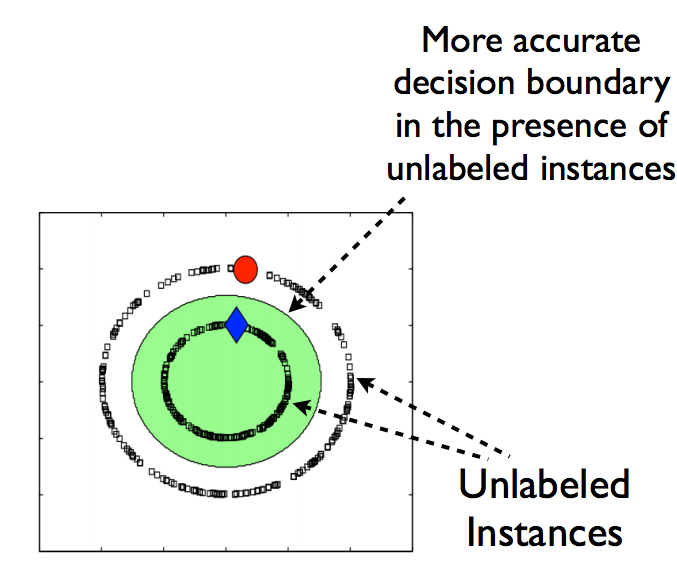
如果我们注意到上面两个图像之间的差异,你可以说,在添加了不加标签的数据之后,我们的模型的决策边界变得更加准确。因此,使用不加标签数据的好处是:
1.被贴上标签的数据既昂贵又困难,而没有标签的数据则是充足而廉价的。
2.它通过更精确的决策边界来改进模型的鲁棒性。
现在,我们对半监督学习有了一个基本的了解。有多种不同的技术在应用着半监督学习,在本文中,我们将尝试理解一种称为伪标签的技术。
介绍伪标签
在这种技术中,我们不需要手动标记不加标签的数据,而是根据标签的数据给出近似的标签。让我们通过分解如下图所示的步骤来使它更容易理解。
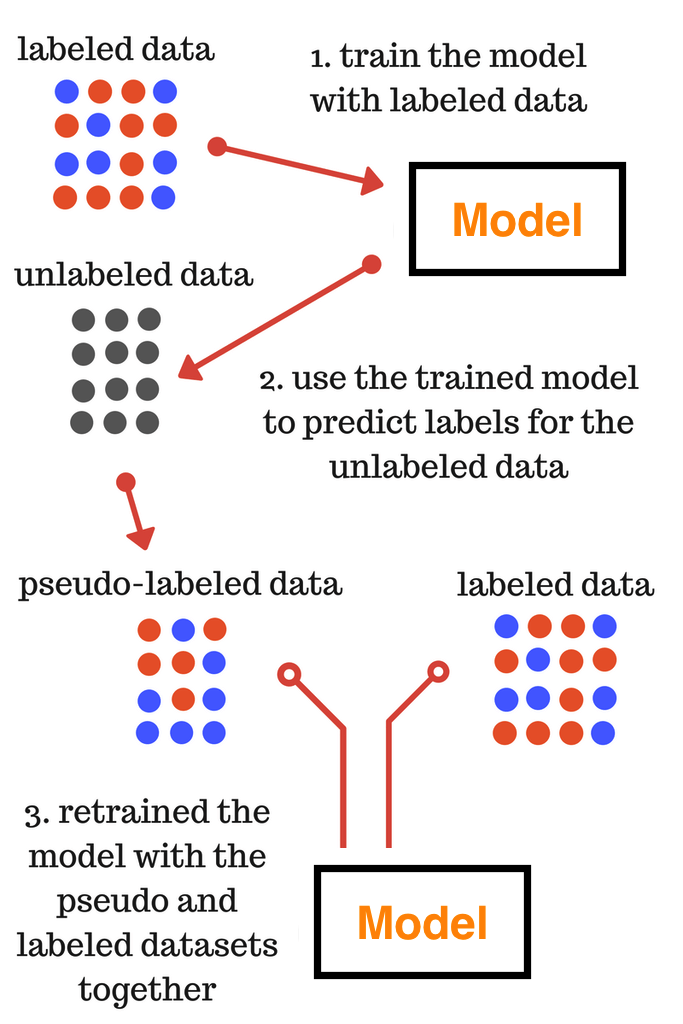
第一步:使用标签数据训练模型
第二步:使用训练的模型为不加标签的数据预测标签
第三步:同时使用pseudo和标签数据集重新训练模型
在第三步中训练的最终模型用于对测试数据的最终预测。
实现半监督学习
现在,我们将使用来自AV数据处理平台的大市场销售(Big Mart Sales)问题。因此,让我们从下载数据部分中的训练和测试文件开始。
那么,让我们从导入基本库开始。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import LabelEncoder
现在,看一下我们下载的训练和测试文件,并进行一些基本的预处理,以形成模型。
train = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/train.csv')
test = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/test.csv')
# preprocessing
### mean imputations
train['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True)
test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### reducing fat content to only two categories
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
## for calculating establishment year
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']
### missing values for size
train['Outlet_Size'].fillna('Small',inplace=True)
test['Outlet_Size'].fillna('Small',inplace=True)
### label encoding cate. var.
col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content']
test['Item_Outlet_Sales'] = 0
combi = train.append(test)
number = LabelEncoder()
for i in col:
combi[i] = number.fit_transform(combi[i].astype('str'))
combi[i] = combi[i].astype('int')
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## removing id variables
training = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
testing = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
y_train = training['Item_Outlet_Sales']
training.drop('Item_Outlet_Sales',axis=1,inplace=True)
features = training.columns
target = 'Item_Outlet_Sales'
X_train, X_test = training, testing
从不同的监督学习算法开始,让我们来看看哪一种算法给了我们最好的结果。
from xgboost import XGBRegressor
from sklearn.linear_model import BayesianRidge, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor, GradientBoostingRegressor
#from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score
model_factory = [
RandomForestRegressor(),
XGBRegressor(nthread=1),
#MLPRegressor(),
Ridge(),
BayesianRidge(),
ExtraTreesRegressor(),
ElasticNet(),
KNeighborsRegressor(),
GradientBoostingRegressor()
]
for model in model_factory:
model.seed = 42
num_folds = 3
scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error')
score_description = " %0.2f (+/- %0.2f)" % (np.sqrt(scores.mean()*-1), scores.std() * 2)
print('{model:25} CV-5 RMSE: {score}'.format(
model=model.__class__.__name__,
score=score_description
))

我们可以看到XGB算法为我们提供了最佳的模型性能。注意,我没有为了本文的简单性而调整任何算法的参数。
现在,让我们来实现伪标签,为了这个目的,我将使用测试数据作为不加标签的数据。
from sklearn.utils import shuffle
from sklearn.base import BaseEstimator, RegressorMixin
class PseudoLabeler(BaseEstimator, RegressorMixin):
'''
Sci-kit learn wrapper for creating pseudo-lebeled estimators.
'''
def __init__(self, model, unlabled_data, features, target, sample_rate=0.2, seed=42):
'''
@sample_rate - percent of samples used as pseudo-labelled data
from the unlabelled dataset
'''
assert sample_rate <= 1.0, 'Sample_rate should be between 0.0 and 1.0.'
self.sample_rate = sample_rate
self.seed = seed
self.model = model
self.model.seed = seed
self.unlabled_data = unlabled_data
self.features = features
self.target = target
def get_params(self, deep=True):
return {
"sample_rate": self.sample_rate,
"seed": self.seed,
"model": self.model,
"unlabled_data": self.unlabled_data,
"features": self.features,
"target": self.target
}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def fit(self, X, y):
'''
Fit the data using pseudo labeling.
'''
augemented_train = self.__create_augmented_train(X, y)
self.model.fit(
augemented_train[self.features],
augemented_train[self.target]
)
return self
def __create_augmented_train(self, X, y):
'''
Create and return the augmented_train set that consists
of pseudo-labeled and labeled data.
'''
num_of_samples = int(len(self.unlabled_data) * self.sample_rate)
# Train the model and creat the pseudo-labels
self.model.fit(X, y)
pseudo_labels = self.model.predict(self.unlabled_data[self.features])
# Add the pseudo-labels to the test set
pseudo_data = self.unlabled_data.copy(deep=True)
pseudo_data[self.target] = pseudo_labels
# Take a subset of the test set with pseudo-labels and append in onto
# the training set
sampled_pseudo_data = pseudo_data.sample(n=num_of_samples)
temp_train = pd.concat([X, y], axis=1)
augemented_train = pd.concat([sampled_pseudo_data, temp_train])
return shuffle(augemented_train)
def predict(self, X):
'''
Returns the predicted values.
'''
return self.model.predict(X)
def get_model_name(self):
return self.model.__class__.__name__
看起来很复杂,但是你不必为此担心,因为它是我们在上面学习的方法的相同实现。因此,每次需要执行伪标签时,都要复制相同的代码。
现在,让我们来检查一下数据集上的伪标签的结果。
model_factory = [
XGBRegressor(nthread=1),
PseudoLabeler(
XGBRegressor(nthread=1),
test,
features,
target,
sample_rate=0.3
),
]
for model in model_factory:
model.seed = 42
num_folds = 8
scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8)
score_description = "MSE: %0.4f (+/- %0.4f)" % (np.sqrt(scores.mean()*-1), scores.std() * 2)
print('{model:25} CV-{num_folds} {score_cv}'.format(
model=model.__class__.__name__,
num_folds=num_folds,
score_cv=score_description
))
在这种情况下,我们得到了一个rmse值,这个值比任何受监督的学习算法都要小。sample_rate(采样率)是其中一个参数,它表示不加标签数据的百分比被用作建模目的的伪标签。
因此,让我们检查一下采样率对伪标签性能的依赖性。
采样率的依赖
为了找出样本率对伪标签性能的依赖,让我们在这两者之间画一个图。在这里,我只使用了两种算法来表示对时间约束(time constraint)的依赖,但你也可以尝试其他算法。
sample_rates = np.linspace(0, 1, 10)
def pseudo_label_wrapper(model):
return PseudoLabeler(model, test, features, target)
# List of all models to test
model_factory = [
RandomForestRegressor(n_jobs=1),
XGBRegressor(),
]
# Apply the PseudoLabeler class to each model
model_factory = map(pseudo_label_wrapper, model_factory)
# Train each model with different sample rates
results = {}
num_folds = 5
for model in model_factory:
model_name = model.get_model_name()
print('%s' % model_name)
results[model_name] = list()
for sample_rate in sample_rates:
model.sample_rate = sample_rate
# Calculate the CV-3 R2 score and store it
scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8)
results[model_name].append(np.sqrt(scores.mean()*-1))
plt.figure(figsize=(16, 18))
i = 1
for model_name, performance in results.items():
plt.subplot(3, 3, i)
i += 1
plt.plot(sample_rates, performance)
plt.title(model_name)
plt.xlabel('sample_rate')
plt.ylabel('RMSE')
plt.show()
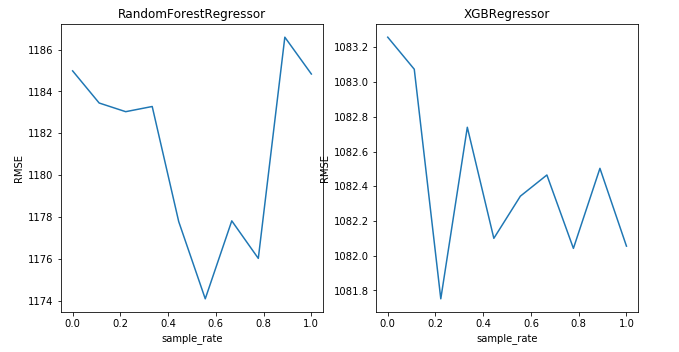
我们可以看到,rmse对于采样率的特定值来说是最小值,这对于算法来说是不同的。因此,对采样率进行调优是很重要的,以便在使用伪标签时获得更好的结果。
半监督学习的应用
在过去,半监督学习的应用数量有限,但目前在这一领域仍有很多工作要做。下面列出了一些我感兴趣的应用。
1.多模态半监督学习(Multimodal semi-supervised learning)图像分类
一般来说,在图像分类中,目标是对图像进行分类,无论它属于这个类别还是不属于类别。本文不仅利用图像进行建模,还利用半监督学习的方法来改进分类器,从而提高分类器的使用效果。

2.检测人口贩卖
人口贩卖是最残忍的犯罪之一,也是法律执行所面临的挑战问题之一。半监督学习使用标签和不加标签的数据,以产生比一般方法更好的结果。
本文的完整代码:https://github.com/shubhamjn1/Pseudo-Labelling---A-Semi-supervised-learning-technique

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消